

Character encoding. You may have heard of it, but what is it, and why should you care? What can happen if you get it wrong? How do you know which one to use?
We’ll look into the details in a minute, but for now let’s just say that a character encoding is the way that letters, digits and other symbols are expressed as numeric values that a computer can understand.
A file — an HTML document, for instance — is saved with a particular character encoding. Information about the form of encoding that the file uses is sent to browsers and other user agents, so that they can interpret the bits and bytes properly. If the declared encoding doesn’t match the encoding that has actually been used, browsers may render your precious web page as gobbledygook. And of course search engines can’t make head nor tail of it, either.
Key Takeaways
- Understand the Basics: Character encoding is essential for the correct display and interpretation of text on web pages. It converts characters into bytes that computers can understand, affecting how text appears in different languages and scripts.
- Choose the Right Encoding: Selecting an appropriate character encoding, like UTF-8, is crucial, especially for multilingual websites. UTF-8 supports a vast range of characters and is widely compatible with various systems and devices.
- Declare Encoding Properly: Always specify the character encoding used in your HTML documents using the `` tag in the head section to prevent display errors and ensure consistency across different browsers.
- Consider Using Entities for Special Characters: When characters are not supported by the chosen encoding, use HTML entities or numeric character references to include special characters like © or accents.
- Be Aware of Encoding Limitations: Each encoding has its limitations and compatibility issues. For instance, older browsers might not support newer encodings like UTF-8, and some text editors may not handle all encodings correctly, which could affect how text is displayed or saved.
What’s the Difference?
Why does it matter which form of encoding we choose? What happens if we choose the “wrong” one?
The choice of character encoding affects the range of literal characters we can use in a web page. Regular Latin letters are rarely a problem, but some languages need more letters than others, and some languages need various diacritical marks above or below the letters. Then, of course, some languages don’t use Latin letters at all. If we want proper — as in typographically correct — punctuation and special symbols, the choice of encoding also becomes more critical.
What if we need a character that cannot be represented with the encoding we’ve chosen? We have to resort to entities or numeric character references (NCR). An entity reference is a symbolic name for a particular character, such as © for the © symbol. It starts with an ampersand (&) and should end with a semicolon (;). An NCR references a character by its code position (see below). The NCR for the copyright symbol is © (decimal) or © (hexadecimal).
Entities or NCRs work just as well as literal characters, but they use more bytes and make the markup more difficult to read. They are also prone to typing errors.
What Affects the Choice?
A number of parameters should be taken into consideration before we choose a form of encoding, including:
- Which characters am I going to use?
- In which encodings can my editor save files?
- Which encodings are supported by the various components in my publishing chain?
- Which encodings are supported by visitors’ browsers?
Let’s consider each of these issues in turn.
Character Range
The first parameter we need to consider is the range of characters we’re going to need. Obviously, a site that’s written in a single language uses a more limited range of characters than a multilingual site — especially one that mixes Latin letters with Cyrillic, Greek, Hebrew, Arabic, Chinese, and so on.
If we want to use typographically correct quotation marks, dashes and other special punctuation, the “normal” encodings fall short. This is also true if we need mathematical or other special symbols.
Text Editor Capabilities
Some authors prefer to use regular text editors like Notepad or Vim; others like a point-and-click WYSIWYG tool like Dreamweaver; some use a sophisticated content management system (CMS). Regardless of personal preference, our choice of editors affects our choice of encoding. Some editors can only save in one encoding, and they won’t even tell you which one. Others can save in dozens of different encodings, but require you to know which one will suit your needs.
Other Components
A publishing chain consists of more than an editor. There’s always a web server (HTTP server) at the far end of the chain, but there can be other components in between: databases, programming or scripting languages, frameworks, application servers, servlet engines and more.
Each of these components may affect your choice of encoding. Maybe the database can only store data in one particular encoding, or perhaps the scripting language you’re using cannot handle certain encodings.
It’s not possible to enumerate the capabilities of all the different editors, databases, and so on in this article, because there are simply too many of them. You need to look at the documentation for your components before choosing the encoding to use.
Browser Support
Some encodings — like US-ASCII, the ISO 8859 series and UTF-8 — are widely supported. Others are not. It is probably best to avoid the more esoteric encodings, especially on a site that’s intended for an international audience.
What is a Character Encoding?
A character is the smallest unit of writing that’s capable of conveying information. It’s an abstract concept: a character does not have a visual appearance. “Uppercase Latin A” is a different character from “lowercase Latin a” and from “uppercase Cyrillic A” and “uppercase Greek Alpha”.
A visual representation of a character is known as a glyph. A certain set of glyphs is called a font. “Uppercase Latin A”, “uppercase Cyrillic A” and “uppercase Greek Alpha” may have identical glyphs, but they are different characters. At the same time, the glyphs for “uppercase Latin A” can look very different in Times New Roman, Gill Sans and Poetica chancery italic, but they still represent the same character.
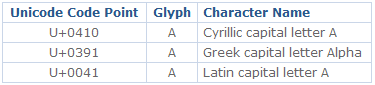
The set of available characters is called a character repertoire. The location (index) of a given character within a repertoire is known as its code position, or code point.
The method of numerically representing a code point within a given repertoire is called the character encoding. Unfortunately, the term “character set”, or “charset”, has been used both for repertoires and for encodings, so it is best to avoid it altogether.
Encodings are normally expressed in terms of octets. An octet is a group of eight binary digits, i.e., eight ones and zeros. An octet can express a numeric range between 0 and 255, or between 0x00 and 0xFF, to use hexadecimal notation.
A Brief History
The early computers didn’t have a standardised character encoding, but this didn’t matter much, because computers could rarely communicate with one another back then. When inter-computer communication became possible, the need for encoding standards became apparent. A common early repertoire/encoding was EBCDIC, another was the American Standard Code for Information Interchange, a.k.a. ASCII. The U.S. version, US-ASCII, has been standardised as ISO 646.
ASCII uses only seven bits (ones and zeros), which means it can represent 128 numbers: 0 through 127, inclusive. The 0-31 range is reserved for C0 control characters and 127 is reserved for DEL (delete), which leaves a total of 95 printable characters. That’s enough for the English alphabet in uppercase and lowercase, plus digits and some common (and, admittedly, some less common) punctuation. But it’s not enough to take in the accented characters and diacritical marks necessary for many European languages, let alone any writing that doesn’t use Latin letters. Mutually incompatible national versions of ASCII used to be commonplace, but they don’t work for international information exchange.
The ISO 8859 series was an attempt to provide alternatives for languages other than English. It is a superset of ASCII, i.e., the first 128 code points are the same in ASCII and all versions of ISO 8859. But ISO 8859 uses eight bits and can thus represent 256 characters (0-255). It is therefore sometimes, incorrectly, called “8-bit ASCII”. The range from 128 to 159 (0x80 to 0x9F) is reserved for C1 control characters.
The most common version for Western languages is ISO 8859-1, a.k.a. ISO Latin-1. It contains a number of accented versions of vowels, plus various special characters. It has now been replaced by ISO 8859-15, to accommodate the Euro sign (€,€).
ASCII and the ISO 8859 series are both character repertoires and encodings. The code points range from 0 to 127 for ASCII and from 0 to 255 for ISO 8859. The encoding is a simple one-to-one, since one octet can comfortably express the whole range. “Uppercase Latin A” has code point 65 (0x41) and is encoded as 65 (01000001).
Microsoft, never known for following someone else’s standard when it can create its own, has also created a number of character repertoires/encodings. These were called “code pages” in DOS, and CP850 was the code page used for Western languages.
One of the most common Microsoft repertoires/encodings is known as Windows-1252. While very similar to ISO 8859-1, it’s not identical. The range reserved for C1 control characters in the ISO encodings is used by Microsoft to provide certain handy characters that aren’t available in the ISO series, such as typographically correct quotation marks and dashes.
For languages that don’t use Latin letters, similar specialized repertoires/encodings were devised. The problem was that there was no repertoire/encoding that could be used for combinations of such languages.
Unicode / ISO 10646
The solution to this problem is called Unicode — a character repertoire that contains most of the characters used in the languages of the world. It can accommodate millions of characters, and already contains hundreds of thousands. Unicode is divided into “planes” of 64K characters. The only one used in most circumstances is the first plane, known as the basic multilingual plane, or BMP.
The first 256 code points in Unicode are compatible with ISO 8859-1, which also means that the first 128 code points are compatible with US-ASCII. Code points in Unicode are written in hexadecimal, prefixed by a capital “U” and a plus sign (e.g., U+0041 for “uppercase Latin A” (code point 65, or 0x41)).
A version of Unicode that has been standardised by ISO is called ISO 10646 (the number is no coincidence; compare to US-ASCII’s ISO 646). There are minor differences between Unicode and ISO 10646, but nothing that we mere mortals need to worry about.
ISO 10646 is important, because it is the character repertoire that’s used by HTML.
But ISO 10646 is only a repertoire. We need an encoding to go with it. Since the repertoire can represent millions of code points, a one-to-one encoding would be very inefficient. We’d need 32 bits (four octets) for each character and that would be quite a waste, especially for Western languages. Such an encoding (UTF-32) exists, but it is rarely used. Another one is UTF-16, which uses two octets for each character, but it hasn’t quite caught on.
Instead, a more efficient (for Western languages) encoding known as UTF-8 has become the recommended way forward. It uses a variable number of octets to represent different characters. The ASCII range (U+0000 to U+007F) is encoded one-to-one. For other characters, two, three or four octets are needed. In theory, UTF-8 can employ up to six octets to encode certain characters.
Which Encoding Should I Choose?
For an English-only site, it doesn’t matter all that much. Unless you want to use some typographically correct punctuation (curly quotes, etc.), plain old US-ASCII will be sufficient. ISO 8859-1 has become something of a de facto standard for Western sites, and may be of interest if you prefer spellings like “naïve” or “rôle” or “smörgåsbord.”
For those of us who need to write in some other Western European language, such as French, Spanish, Portuguese, Italian, German, Swedish, Norwegian, Danish or Finnish, ISO 8859-1 works quite well. Those who need the diacritical marks of Czech or Polish, or completely separate alphabets like Greek or Cyrillic, can choose from other versions of the ISO 8859 series.
As I’ve mentioned, specialized encodings exist for Hebrew, Arabic and Oriental scripts as well. But what if you need to mix English, Russian, Greek and Japanese on the same site? Or even on the same page?
I would recommend using UTF-8 wherever possible, since it can represent any character in the ISO 10646 repertoire. Even if you only write in English, UTF-8 gives you direct access to typographically correct quotation marks, several dashes, ellipses, and more. And if you need to write in Greek or Japanese, you can do so without having to muck about with entities or NCRs.
On a multilingual site, it’s certainly possible to use different encodings for different pages, but think of the maintenance nightmare. Why not use UTF-8 for everything and stop worrying?
Unfortunately, though, a few minor problems are associated with using UTF-8 — even in this day and age.
UTF-8 Problems
The first problem with using UTF-8 is that not all editors or publishing tools support it. You’d think that all software would support UTF-8 after all these years, but sadly this is not so.
The next problem is something called a byte order mark, or BOM. This is a sequence of two (UTF-16) or three (UTF-8) octets that tells a computer whether the most or least significant octet comes first. Some browsers don’t understand the BOM, and will output it as text. Other editors won’t allow us to omit the BOM.
A minor problem is that some ancient browsers don’t support UTF-8 (even without the BOM). However, those should be few and far between these days.
ISO 8859 Problems
If you’re publishing in English, French and German, and encounter problems with UTF-8, you may choose to go with our trusted old friend: ISO 8859-1. But there are still a few pitfalls to look out for.
Many editors under Windows will use Windows-1252 as the default (or only!) encoding. If you save files as Windows-1252 and declare the encoding to be ISO 8859-1, it usually works. This is because the two are very similar.
But if you use certain literal characters, like typographically correct quotation marks, dashes, ellipses, and so on, you’ll run into trouble. These characters are not part of ISO 8859-1. In Windows-1252, they’re located in the range that the ISO encoding reserves for C1 control characters — in other words, those code points are invalid in ISO 8859-1. Copying from another Windows application, like Word, is a particularly likely cause of problems.
The W3C’s HTML validator will catch these types of invalid characters and report them as errors.
Problems with Other Encodings
UTF-8 and the ISO 8859 series are well supported by modern browsers. Most browsers also support quite a few other encodings, but if you choose an exotic encoding, you run the risk that some visitors won’t be able to read your content.
In some countries in which the Latin alphabet isn’t used, web developers may use a font that offers the required characters and not care about the encoding at all. This is most unwise. Any visitor who doesn’t have that particular font installed will see nothing but gibberish. And those “visitors” include Google and the other search engines.
Specifying the Encoding
Once you’ve chosen the encoding you’ll use, you must make sure that the proper information is passed to browsers, search engines, and so on.
Web pages are served using the HyperText Transfer Protocol (HTTP): a browser sends a request via HTTP and the server sends a response back via HTTP. The response consists of two parts: headers and body, separated by a blank line. The headers provide information about the body (content). The body contains the requested resource (typically an HTML document).
For HTML, encoding information should be sent by the web server using the Content-Type header:
Content-Type: text/html; charset=utf-8You may also wish to provide an HTTP equivalent in HTML that will declare the encoding when the page is viewed offline. You can do so using a META element in the HEAD-section of your document:
<meta http-equiv="Content-Type"
content="text/html; charset=utf-8">Note, however, that any real HTTP header will override a META element, so it’s imperative that you set up the web server correctly. For Apache, you can do so by editing the configuration file (/etc/httpd.conf on most *nix systems). The directive should look something like this:
AddDefaultCharset UTF-8For Microsoft IIS, this setting needs to be located within its numerous dialog boxes.
For XML — including properly served XHTML — the encoding should be specified in the XML declaration at the top of the file. In these cases, the Content-Type header should not contain any encoding information at all. XML parsers are only required to support UTF-8 and UTF-16, which makes the choice somewhat easier:
<?xml version="1.0" encoding="utf-8"?>Note that this does not apply to XHTML served as text/HTML, because that’s not really XHTML at all, so the XML declaration doesn’t work.
Summary
Choosing the right character encoding is important. If you choose an encoding that’s unsuitable for your site (e.g. using ISO 8859-1 for a Chinese site), you’ll need to use lots of entities or NCRs, which will bloat file sizes unnecessarily.
Unfortunately, choosing an encoding isn’t always easy. Lack of support within the various components in the publishing chain can prevent you from using the encoding that would best suit your content.
Use UTF-8 (without a BOM) if at all possible, especially for multilingual sites.
And perhaps the most important thing of all: the encoding you declare must match the encoding you used when saving your files!
Frequently Asked Questions about Web Character Encoding
What is the importance of character encoding in HTML?
Character encoding in HTML is crucial as it ensures that the content displayed on the web page is correctly interpreted and displayed. It defines the set of characters (letters, numbers, symbols) that are used in the HTML document. Without proper character encoding, certain characters may not display correctly, leading to misinterpretation of the content.
How does UTF-8 differ from other character encodings?
UTF-8 is a universal character encoding standard that can represent any character in the Unicode standard, yet it is backward-compatible with ASCII. It uses one to four 8-bit bytes to represent each symbol. Unlike other encodings, UTF-8 can accommodate characters from a wide range of languages, making it a popular choice for web pages and email.
How do I declare character encoding in an HTML document?
To declare character encoding in an HTML document, you need to use the meta tag in the head section of your HTML document. For example, to declare UTF-8 encoding, you would use the following code: <meta charset="UTF-8">.
What happens if I don’t specify a character encoding in my HTML document?
If you don’t specify a character encoding in your HTML document, the browser may use a default encoding to interpret your document, which could lead to incorrect display of characters. This is especially problematic if your document contains non-ASCII characters.
Can I use multiple character encodings in a single HTML document?
No, you cannot use multiple character encodings in a single HTML document. An HTML document can only have one character encoding declaration. Using multiple encodings can lead to unpredictable results and is not recommended.
What is the difference between character encoding and character set?
A character set is a list of characters with corresponding numeric codes, while character encoding is the method used to represent these characters in binary so they can be stored in a computer or transmitted over a network.
Why is UTF-8 recommended for web pages?
UTF-8 is recommended for web pages because it supports a wide range of characters from different languages, making it suitable for international content. It’s also backward-compatible with ASCII, which means it can handle content designed for ASCII encoding.
How can I convert my HTML document to a different character encoding?
To convert your HTML document to a different character encoding, you can use a text editor that supports encoding conversion. You would open your document in the text editor, then save it with the new encoding.
What is the role of the BOM in character encoding?
The Byte Order Mark (BOM) is a special character used to indicate the endianness (byte order) of a text file or stream. It’s particularly useful in UTF-16 and UTF-32, but it’s optional in UTF-8.
How can I check the character encoding of an existing HTML document?
You can check the character encoding of an existing HTML document by looking at the meta charset tag in the head section of the document. If the document doesn’t have a meta charset tag, you can use a web development tool like Chrome’s DevTools to view the encoding.