The designer’s toolset seems to be always expanding. Long gone are the days when a web designer could rely solely on an HTML editor and Photoshop. Now, especially when working in a team with developers, you need to work smarter and more collaboratively.
In this post, I’m going to discuss using Git.
Git is version-control software, originally created by Linus Torvalds (the creator of Linux). It’s main purpose is to track changes to files, so that you can better manage your work.
As a designer, why should you care? Why should you learn a command line to use version control software?
Because Git is fantastic.
In essence, it keeps track of all the changes to your files in a project, so if you break something, Git will be there to help you get back on track. Its powerful tools let you view your changes, helping you fix your code so that it’s free of a certain bug, or see exactly who broke your precious code.
It does, however, have a mantra among its users: Git will do exactly what you say, but not always exactly what you mean. So in this article, I’ll cover both the right way to use it, as well as common pitfalls that would otherwise cause you problems.
The Tree Metaphor
Most source control systems (Git included) use the concept of a tree to describe a repository. A repository is a collection of files and directories (your project), as well as a list of changes to those files over the life of the repository.
The master branch, sometimes referred to as “the trunk,” is the current state of the files in your project. You can create additional branches from the master branch, depending on your needs, or the way you work.
When working with Git, you’ll need to know these terms:
- Branching creates a copy of a branch, typically the master branch, so that it’s now independent of the one it was created from. It enables you to have a clean slate to make changes to your heart’s content, and when you’re happy with them, you can merge them back in.
- Merging is like the opposite of branching. You have two branches, and you can merge one branch’s changes into another. At the end of a merge, you still have two branches, but one branch’s changes are now also on the other branch.
Feature branches are a branch off the master branch, and a common way to work when you start on a new feature of your website. When the feature is complete, you can merge it safely back into the master branch. This way, managing the features you’re working on is easy: you can have a whole set of features for a project in progress, and merge back into the master only the features that are finished and working.
Beginning a Repository
To start using Git, you have to install it. Head to http://git-scm.com/download to find installers for your operating system.
Once it’s installed, create a folder. I’ll name the one I’m using here sitepointexample:
> mkdir sitepointexample > cd sitepointexample > git init Initialized empty Git repository in /Users/mark/sitepointexample/.git/
[Caveat: I’m a Mac guy. That means the command line is a little different for you Windows users, but the Git commands are mostly the same.]
git init steps up a blank repository. It will return Initialized empty Git repository in /Users//sitepointexample/.git/ letting you know your repo is ready to use.
Local Branch, Remote Branch
It’s quite common to have a remote master. A remote master is a copy of the repository (usually on a server that’s accessible by all the development members of your team) that you can push or pull changes from/to.
I’ll skip going into this in any depth; there are many resources on the Internet that will explain this in more detail.
Status, Add, Commit, Pull, Merge, Push
There are six basic actions you can do with Git. This is by no means all you can do, but in your day-to-day tasks these are the six that you’ll use most often, in this order (apart from merge, which you’ll use less than the other five). Most likely, you’ll learn these by rote; you will definitely use them a lot!
Status
git status shows you everything you need to know about the state of your repository. It shows which branch you’re working on, what files have been changed since they were last committed, and which files Git knows nothing about. It will indicate if files have been moved or deleted, or if there are merges that need to be made manually.
Typically, git status shows three groups of files:
- Tracked changes are files that have had
git addrun on them. These files would be committed ifgit commitwas run. - Untracked changes haven’t had
git addrun on them, and there are changes that Git knows about, but will do nothing with. - Untracked files are files Git knows nothing about. They are either new files or files that have never been added to the repository.
Below are three commands: a git status telling me I’ve not committed anything yet; I’ve created (or touched) an empty file called README; and I’ve done another git status, telling me I have an untracked file (called README):
> git status # On branch master # # Initial commit # nothing to commit (create/copy files and use "git add" to track) > touch README > git status # On branch master # # Initial commit # # Untracked files: # (use "git add ..." to include in what will be committed) # # README nothing added to commit but untracked files present (use "git add" to track)
git status is the first command to use. Do it before you do anything else, every time.
Add
git add <filename> tells the repository you want to keep track of the changes to a file. You can keep working after you’ve added the changes to the repository, but only the changes up to the point of adding would be committed. You can always add changes over added changes; it won’t lose anything, just keep track of more changes. Once you’ve run git add, you should use git status to make sure that what was added was what you wanted:
> git add README > git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached ..." to unstage) # # new file: README #
So I’ve added the README file, and another git status tells me that when I commit, Git will commit the changes to that file.
In case you’ve added changes in error, you can undo the changes by running git reset HEAD <filename>, which tells the repository not to do anything with the changes. It will not drop any changes you’ve made; it just won’t commit them.
Commit
git commit saves the changes to the repository. A commit gives you a commit identifier, a long string of characters (an MD5 hash) that the repository uses to name the point in time the commit was made. These are what you can use in the unfortunate event that you need to roll back to a previous point in time:
>git commit --message 'My First Commit' [master (root-commit) d602d2b] My First Commit 0 files changed, 0 insertions(+), 0 deletions(-) create mode 100644 README
I’ve committed the changes to the file with the --message 'My First Commit'. These are handy hints you can write when you’re checking through the commit log looking for a certain change you made. Make these as descriptive as you can. They save you lots of time when something goes wrong. You can also use -m 'MESSAGE' instead of --message 'MESSAGE' as a short form, saving you time.
Pull
git pull pulls in changes other members of your team have made. For this example, I don’t have other team members using the repository (the whole repository is on my machine), but when you do, it will look like this:
> git pull remote: Counting objects: 118, done. remote: Compressing objects: 100% (75/75), done. remote: Total 78 (delta 52), reused 0 (delta 0) Unpacking objects: 100% (78/78), done. From git@github.com:sitepoint/example 36aeed8..8c18ec5 branchname -> origin/branchname Merge made by recursive. .../Resource/otherfile.php | 19 ++ .../Resource/file.php | 8 - 2 files changed, 19 insertions(+), 8 deletions(-) create mode 100755 /Resource/file.php
Some points here:
- We use GitHub, a company that hosts repositories. They have excellent documentation and help online. Check them out.
- The remote branch is
origin/branchname. Typically,originmeans the remote server hosting your repository. 36aeed8..8c18ec5are the two commit ids: what this means is that Git is updating from the first commit (which you had on your machine, being36aeed8), to the second (8c18ec5).- Two files were pulled down, and one of them (
create mode 100755 /Resource/file.php) was a new file in your repository. It was added by another member of the team.
Merge
git merge is used when you have two branches, and you want to take the changes from one and add them to the other branch.
Usually, you’ll have changes on a feature branch and, when you’re happy with the work, you’ll merge the changes in the master:
> git branch otherexample > git checkout otherexample Switched to branch 'otherexample' > git branch master * otherexample > touch OTHERFILE > git add OTHERFILE > git commit -m 'Other File Added' [otherexample 16283e5] Other File Added 0 files changed, 0 insertions(+), 0 deletions(-) create mode 100644 OTHERFILE > git checkout master Switched to branch 'master' > git status # On branch master nothing to commit (working directory clean) > git merge otherexample Updating d602d2b..16283e5 Fast-forward 0 files changed, 0 insertions(+), 0 deletions(-) create mode 100644 OTHERFILE
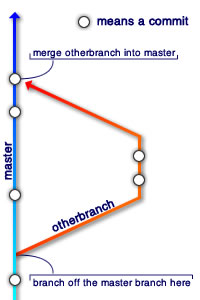
Here’s what I’ve done:
git branch otherexamplecreates a new branch, calledotherexample.git checkout otherexampleswitches to that new branch.git branchshows what branches I have available. It tells me I have two branches,masterandotherexample. [FYI:git branch -rshows what branchesorigin(the remote server I alluded to earlier) has].touch OTHERFILE,git add OTHERFILE, andgit commit -m 'Other File Added'create a new file on the new branch, tell GIT that you want to commit the change, and commit it with a message of'Other File Added', just like the steps above.git checkout masterjumps back to themasterbranch.git merge otherexampletakes the changes onotherexampleand merges them intomaster, the branch you’re on. You can see that it has created the file “OTHERFILE” in yourmasterbranch.
Push
git push will push your changes to the remote server, sharing them with your team. When they next git pull, they’ll see your changes.
git push origin master is usually how it’s used. The difference between git push and git push origin master is that the latter will only push the master branch, while the former will try and push all branches.
It would be used, for example, when you want to push just a single feature branch, so that a team member can also see the changes you’ve made to ‘otherbranch’, and you’d use git push origin otherbranch.
Conclusion
And they are the basics of Git. It is, however, a complex beast. There are many, many more commands—some are really helpful, while others are a little dangerous. You can pick out a single commit and merge it into your branch, ignoring all commits after it. You can use Git to find the exact commit where your code was broken. You can roll back to an individual commit you made earlier in the day, the day before, three weeks earlier, or any time along the repository’s timeline.
As the designer’s toolkit expands, we need to take advantage of handy workflow tools that make the most of our day. Use Git, and never lose all your changes again.
 Mark Cipolla
Mark CipollaMark Cipolla is a web guy at heart; front-end design and coding (with xhtml/html5/css with a touch of javascript) meets programming (Ruby on Rails and a touch of PHP).





