

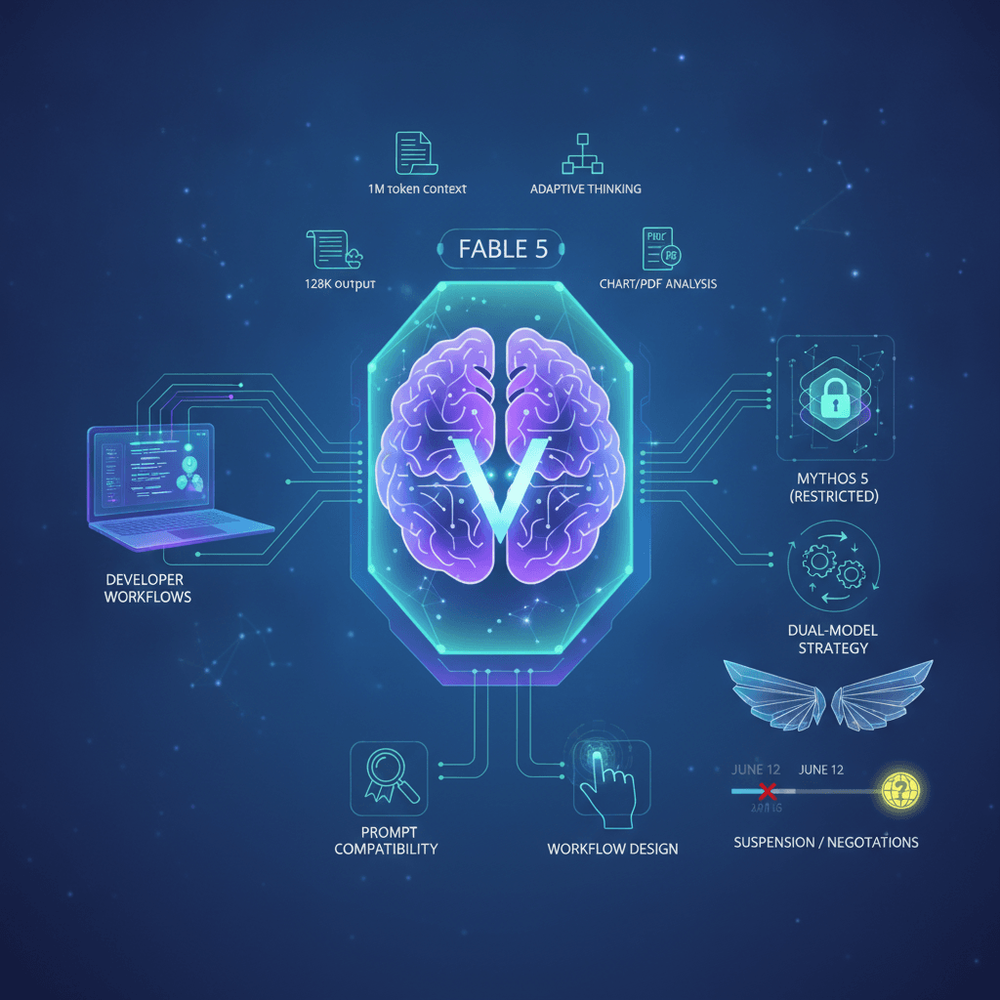
Disclaimer: As of this writing, "Claude Fable 5," the "Mythos-class" tier, and the specifications described below have not been confirmed in Anthropic's public documentation. Treat all capability claims, model IDs, and events in this article as reported and speculative until official release notes or documentation are available. Always verify model identifiers and specifications at docs.anthropic.com before using them in production.
Claude Fable 5 has been reported as Anthropic's most capable coding model to date. Anthropic reportedly made it available for less than a week before pulling access. According to unconfirmed reports, the model shipped with a 1M token context window and 128K token output limit, capabilities that would reshape how developers interact with AI across entire codebases. Then, on or around June 12, Anthropic suspended access amid reported discussions around AI export control frameworks. The model disappeared from Claude.ai and the API, leaving developers who had barely begun exploring its capabilities scrambling to understand what happened and what comes next.
This article covers what Fable 5 reportedly is, how the reported Mythos-class tier would fit into Anthropic's model lineup, what the suspension means in practical terms, and most importantly, what developers should be doing right now to prepare their workflows for its eventual return. The focus here is practical preparation, not speculation.
Table of Contents
- What Is Mythos-Class? Fable 5 vs. the Opus Tier
- The Dual-Model Strategy Explained: Fable 5 Public vs. Mythos 5 Restricted
- Developer-Relevant Capabilities Deep Dive
- What the June 12 Suspension Means
- Practical Preparation Steps You Can Take Today
- The Reported Mythos 5 / Project Glasswing Angle for Enterprise Teams
- Implementation Checklist: Your Forward-Compatibility Readiness Plan
- Next Steps
What Is Mythos-Class? Fable 5 vs. the Opus Tier
Anthropic's Model Tier History (Haiku to Sonnet to Opus to Mythos)
Anthropic has structured its Claude model family into distinct tiers since the Claude 3 generation. Haiku occupies the lightweight, low-latency end. Sonnet sits in the middle as the general-purpose workhorse. Opus represents the high-capability ceiling for complex reasoning and code generation. Opus currently sits at the top of Anthropic's production lineup, handling coding, analysis, and generation tasks with a 200K token context window.
Mythos is the name reported for a new tier above Opus. Anthropic's public documentation does not confirm this as of publication. The naming convention itself would signal a departure: where Haiku, Sonnet, and Opus suggest increasing scale within a familiar frame, Mythos implies a qualitative shift in what the model can handle.
Fable 5 by the Numbers (Unconfirmed)
The following specifications have been reported but not verified against Anthropic's official documentation. Treat them as unconfirmed until official model cards are published.
- Context window: 1M tokens (vs. 200K in current Opus models), a 5x increase
- Output limit: 128K tokens (vs. Sonnet 4 at a reported 8,192 output tokens; Opus 4 at a reported 32,000 output tokens; verify against current API documentation). This substantially reduces truncation risk for large file generation.
- Adaptive thinking: A reported dynamic reasoning mode where the model allocates computational effort based on task complexity, described as distinct from standard chain-of-thought prompting
- The model also reportedly accepts multimodal input, natively analyzing charts, PDFs, images, and technical diagrams.
Note: GPT-5 and Gemini 2.5 Pro specifications below are also unconfirmed or subject to change. Verify at platform.openai.com and ai.google.dev before making model selection decisions.
| Capability | Fable 5 (reported) | Current Opus | GPT-5 (reported) | Gemini 2.5 Pro (reported) |
|---|---|---|---|---|
| Context Window | 1M tokens | 200K tokens | 200K tokens | 1M tokens |
| Output Limit | 128K tokens | Up to 32K tokens | 16K–32K tokens | 64K tokens |
| Multimodal Input | Charts, PDFs, images | Images, limited PDF | Images, audio, video | Images, audio, video |
| Adaptive Reasoning | Reported | No | Yes (reasoning mode) | Yes (thinking mode) |
| Pricing Tier | Mythos (premium) | Opus (high) | Premium | Premium |
The Dual-Model Strategy Explained: Fable 5 Public vs. Mythos 5 Restricted
Fable 5 and Mythos 5 reportedly share the same model weights; they differ only in access controls and output behavior tuning.
Fable 5: The Public-Facing Model
Fable 5 is reportedly the publicly accessible instantiation of the Mythos architecture. When unsuspended, developers would access it through both the Claude API and Claude.ai for general developer and consumer use. It reportedly carries capability guardrails relative to the full Mythos architecture, meaning certain reasoning depths and output behaviors are tuned for broad deployment rather than unrestricted performance.
Mythos 5 and Project Glasswing: The Enterprise/Government Tier
Mythos 5 reportedly represents the unrestricted or less-constrained version of the same underlying architecture, available only through restricted channels. A separate enterprise tier has been reported under the name "Project Glasswing," but Anthropic's public communications do not confirm this. If it exists, the bifurcation would signal a deliberate strategy: consumer and general developer access through Fable 5, with a separate procurement path for enterprises and government entities requiring the full Mythos capability set.
Fable 5 and Mythos 5 reportedly share the same model weights; they differ only in access controls and output behavior tuning.
For enterprise developers planning procurement, this would mean evaluating two distinct access paths. For startups, it means building on the publicly available tier while maintaining flexibility to upgrade if enterprise access becomes viable.
Developer-Relevant Capabilities Deep Dive
1M Token Context: Large Codebase Analysis
One million tokens translates to roughly 67,000–133,000 lines of code (at ~40 characters per line average), enough to encompass large modules or small-to-mid-size repositories in a single context window. This would unlock use cases that were previously impossible without chunking and multi-pass strategies: cross-file refactoring with full dependency awareness, architectural review across an entire service, and dependency auditing that can trace import chains end-to-end.
However, context does not equal comprehension at scale. Research on large-context models consistently shows diminishing attention patterns as context length increases. Information in the middle of very long contexts tends to receive less model attention than information at the beginning or end (see: Liu et al., 2023, "Lost in the Middle: How Language Models Use Long Contexts"). Structuring context with clear delimiters, metadata headers, and targeted analysis instructions remains essential.
Prompt Pattern: Repository-Scale Analysis
Prerequisites:
- Node.js 18.17.0 or later (required for
readdirSyncrecursive option) @anthropic-ai/sdk(install vianpm install @anthropic-ai/sdk)ANTHROPIC_API_KEYenvironment variable set with a valid Anthropic API key
import Anthropic from '@anthropic-ai/sdk';
import { readdirSync, readFileSync, statSync } from 'fs';
import { join, extname, resolve, relative } from 'path';
import { fileURLToPath } from 'url';
// Requires Node.js >= 18.17.0 for recursive readdirSync
const MAX_FILE_BYTES = 1 * 1024 * 1024; // 1 MB per file
const MAX_TOTAL_BYTES = 50 * 1024 * 1024; // 50 MB total payload
function collectSourceFiles(dir, extensions = ['.js', '.ts', '.jsx', '.tsx']) {
const resolved = resolve(dir);
const files = [];
for (const entry of readdirSync(resolved, { recursive: true })) {
const fullPath = join(resolved, String(entry));
try {
const stat = statSync(fullPath);
if (stat.isFile() && extensions.includes(extname(fullPath)) && stat.size <= MAX_FILE_BYTES) {
files.push(fullPath);
}
} catch {
// skip broken symlinks, permission errors, vanished files
}
}
return files;
}
function buildContextPayload(repoPath) {
const resolvedRepo = resolve(repoPath);
const files = collectSourceFiles(resolvedRepo);
const parts = [];
let totalBytes = 0;
for (const filePath of files) {
let content;
try {
content = readFileSync(filePath, 'utf-8');
} catch {
continue; // skip unreadable files
}
const relativePath = relative(resolvedRepo, filePath);
const chunk = `===FILE: ${relativePath}===
// Lines: ${content.split('
').length}
// Imports: ${(content.match(/^import .+/gm) || []).join(', ')}
${content}
===END FILE===
`;
totalBytes += Buffer.byteLength(chunk, 'utf-8');
if (totalBytes > MAX_TOTAL_BYTES) {
console.warn(`[buildContextPayload] Payload size limit reached at ${filePath}; truncating.`);
break;
}
parts.push(chunk);
}
return parts.join('');
}
async function analyzeRepository(repoPath) {
const client = new Anthropic();
const codebaseContext = buildContextPayload(repoPath);
const response = await client.messages.create({
model: 'claude-sonnet-4-20250514', // Verify model ID at docs.anthropic.com/models before use
max_tokens: 16000,
system: 'You are a senior software architect. Analyze the full codebase provided between ===FILE=== delimiters. Identify architectural patterns, circular dependencies, dead code, and suggest refactoring priorities. Reference specific files and line ranges.',
messages: [{ role: 'user', content: codebaseContext }]
});
return response.content[0].text;
}
// Only execute when run directly, not when imported
if (process.argv[1] === fileURLToPath(import.meta.url)) {
const repoPath = process.argv[2] || './my-repo';
analyzeRepository(repoPath).then(console.log).catch(console.error);
}128K Output: Complete File Generation in a Single Pass
A 128K output limit would eliminate one of the most frustrating constraints in AI-assisted development: truncated output. Current workflows frequently require chaining multiple API calls, asking the model to "continue" where it left off, and manually stitching results together. With 128K tokens of output, a single API call could produce an entire React component module complete with TypeScript types, unit tests, and documentation.
Longer output does not inherently mean better output, though. Validation becomes more important as output length increases. For example, a type mismatch introduced early in a generated file can propagate through hundreds of lines of downstream test code, producing output that looks complete but fails on first compile.
A 128K output limit would eliminate one of the most frustrating constraints in AI-assisted development: truncated output.
Prompt Pattern: Full Module Generation with Validation
import Anthropic from '@anthropic-ai/sdk';
const client = new Anthropic(); // requires ANTHROPIC_API_KEY env var
function buildFullModulePrompt(componentName, requirements) {
return `
Generate a complete, production-ready React module for "${componentName}" with the following requirements:
${requirements}
Output the following sections in order, each wrapped in labeled code blocks:
1. **TypeScript Types** (\`${componentName}.types.ts\`)
- All prop interfaces, state types, and utility types
2. **Component Implementation** (\`${componentName}.tsx\`)
- Functional component with hooks
- Full error boundary handling
- Accessibility attributes (ARIA)
3. **Unit Tests** (\`${componentName}.test.tsx\`)
- Minimum 8 test cases covering props, state transitions, error states
- Use React Testing Library and Jest
4. **Storybook Stories** (\`${componentName}.stories.tsx\`)
- Default, loading, error, and edge-case stories
VALIDATION RULES (apply before outputting):
- Every type referenced in the component must be defined in the types file
- Every exported function must have at least one corresponding test
- No \`any\` types permitted
- All imports must reference files within this module or standard libraries
`;
}
// Usage with Claude API
async function generateModule(componentName, requirements) {
const response = await client.messages.create({
model: 'claude-sonnet-4-20250514', // Verify model ID at docs.anthropic.com/models
max_tokens: 32000,
messages: [{ role: 'user', content: buildFullModulePrompt(componentName, requirements) }]
});
return response.content[0].text;
}Adaptive Thinking and Autonomous Coding
The following capabilities are drawn from unverified reports about Fable 5. None have been independently confirmed.
Adaptive thinking differs from standard chain-of-thought in a structural way: rather than the developer instructing the model to "think step by step," the model itself dynamically allocates reasoning effort based on task complexity. Simple tasks get fast, direct responses. Complex multi-step code generation triggers deeper reasoning passes internally. For developers, this would mean fewer prompt engineering workarounds to get reliable results on hard problems, and less overhead on easy ones.
Chart, PDF, and Image Analysis for Documentation Tasks
Fable 5's reported multimodal capabilities would allow ingestion of technical diagrams, API documentation PDFs, and architecture charts directly. A practical use case: feeding a design specification PDF into the model alongside a codebase context and requesting implementation code that matches the spec. Current limitations in multimodal code generation center on the model's ability to accurately interpret complex visual layouts. Grid-based designs, for instance, are often misread as linear lists, causing generated layout code to flatten spatial relationships.
What the June 12 Suspension Means
Export Controls and Regulatory Context
Fable 5 reportedly launched and was available briefly through both the API and Claude.ai. Anthropic suspended access around June 12. Reports attribute the suspension to ongoing negotiations around AI export control frameworks, though Anthropic has not confirmed the specific date or regulatory cause as of publication. The regulatory context reportedly involves compute thresholds and distribution restrictions that apply to frontier AI models. Reports describe this as a suspension rather than a full withdrawal, a distinction that matters for planning purposes if accurate. Anthropic has not provided a specific return date.
What Developers Lost Access To (and What Still Works)
All Claude models below the reported Mythos tier remain fully available. Current Opus, Sonnet, and Haiku models continue to function through the API and Claude.ai. Existing integrations against these models continue to work. Practically, this means developers cannot currently use Fable 5 for production workloads, but they can build and test workflows against current models with forward-compatible patterns.
Practical Preparation Steps You Can Take Today
Step 1: Audit Your Prompts for Forward Compatibility
Prompts designed for 200K context and 8K output will function on higher-capability models but will leave most of their capacity unused. The opportunity is to design modular prompt architectures that scale across model tiers.
// Verify all model IDs and limits at docs.anthropic.com/models before use
class PromptBuilder {
static MODEL_CAPS = {
'claude-sonnet-4-20250514': { contextLimit: 200000, outputLimit: 8192, supportsAdaptive: false }, // Verify outputLimit via API
'claude-opus-4-20250514': { contextLimit: 200000, outputLimit: 32000, supportsAdaptive: false }, // Verify outputLimit via API
'PLACEHOLDER_FABLE5_ID': { contextLimit: 1000000, outputLimit: 128000, supportsAdaptive: true } // Replace with official model ID when announced
};
constructor(modelId) {
this.model = modelId;
this.caps = PromptBuilder.MODEL_CAPS[modelId] || PromptBuilder.MODEL_CAPS['claude-sonnet-4-20250514'];
}
buildAnalysisPrompt(files, analysisType) {
const contextBudget = Math.floor(this.caps.contextLimit * 0.85); // reserve 15% for system prompt and overhead
const fileContent = this.#packFiles(files, contextBudget);
const depth = this.caps.outputLimit > 32000 ? 'comprehensive' : 'summary';
return {
model: this.model,
max_tokens: Math.min(this.caps.outputLimit, 16000),
system: `Perform a ${depth} ${analysisType} analysis. ${this.caps.supportsAdaptive ? 'Use adaptive thinking for complex dependency chains.' : 'Be concise and prioritize critical findings.'}`,
messages: [{ role: 'user', content: fileContent }]
};
}
// files: array of { content: string, path: string }
// Conservative multiplier: dense TS/JSX tokenizes at 1.5–3x the char/4 ratio.
// Use Anthropic's token counting API for accuracy in production.
#packFiles(files, budget) {
let packed = '';
let tokenEstimate = 0;
const TOKEN_CHAR_RATIO = 3; // chars per token (conservative for code)
for (const file of files) {
const fileTokens = Math.ceil(file.content.length / TOKEN_CHAR_RATIO);
if (tokenEstimate + fileTokens > budget) {
console.warn(`[PromptBuilder] Budget reached; ${file.path} and subsequent files omitted.`);
break;
}
packed += `===FILE: ${file.path}===
${file.content}
===END===
`;
tokenEstimate += fileTokens;
}
return packed;
}
}Step 2: Design Workflows for Large-Context Models
Repository indexing and automated output validation are foundational infrastructure for large-context workflows. Generated code should be validated automatically before any human reviews it.
Note: This validation example requires npx, ESLint, and Jest to be available in your PATH. The ESLint check uses --no-eslintrc, which disables all project configuration and checks only for undefined references and unused variables. For TypeScript files, integrate @typescript-eslint/parser and relevant rules for meaningful validation.
import { writeFileSync, mkdtempSync } from 'fs';
import { rm } from 'fs/promises';
import { spawn } from 'child_process';
import { join, basename } from 'path';
import { tmpdir } from 'os';
function runCommand(cmd, args, options) {
return new Promise((resolve) => {
const proc = spawn(cmd, args, { ...options, stdio: 'pipe' });
const stdout = [];
const stderr = [];
proc.stdout.on('data', d => stdout.push(d));
proc.stderr.on('data', d => stderr.push(d));
const timer = setTimeout(() => {
proc.kill();
resolve({ status: -1, stdout: '', stderr: 'timeout' });
}, 30000);
proc.on('close', (status) => {
clearTimeout(timer);
resolve({
status,
stdout: Buffer.concat(stdout).toString().slice(0, 4000), // truncate large output
stderr: Buffer.concat(stderr).toString().slice(0, 4000),
});
});
proc.on('error', (err) => {
clearTimeout(timer);
resolve({ status: -1, stdout: '', stderr: err.message });
});
});
}
async function validateGeneratedOutput(generatedCode, fileName) {
// Strip all directory components — only the bare filename is permitted
const safeFileName = basename(fileName);
if (!safeFileName || safeFileName !== fileName) {
throw new Error(`fileName must be a bare filename with no path components: ${fileName}`);
}
if (/[;&|`$(){}]/.test(safeFileName)) {
throw new Error('Invalid characters in fileName');
}
const workDir = mkdtempSync(join(tmpdir(), 'ai-validate-'));
try {
const filePath = join(workDir, safeFileName);
writeFileSync(filePath, generatedCode);
// Create a minimal package.json so Jest can run
writeFileSync(join(workDir, 'package.json'), JSON.stringify({ name: 'ai-validate', version: '1.0.0' }));
const results = { eslint: null, jest: null, passed: false };
// WARNING: --no-eslintrc disables project config. This checks only undefined references and unused vars.
// For TypeScript, add @typescript-eslint/parser and relevant rules.
const eslintResult = await runCommand('npx', [
'eslint', '--no-eslintrc',
'--rule', '{"no-undef":"error","no-unused-vars":"warn"}',
filePath
], { cwd: workDir });
if (eslintResult.status === 0) {
results.eslint = { passed: true, errors: [] };
} else {
results.eslint = { passed: false, errors: eslintResult.stdout || eslintResult.stderr || 'unknown error' };
}
if (safeFileName.includes('.test.')) {
const jestResult = await runCommand('npx', [
'jest', '--passWithNoTests', filePath
], { cwd: workDir });
if (jestResult.status === 0) {
results.jest = { passed: true, errors: [] };
} else {
results.jest = { passed: false, errors: jestResult.stdout || jestResult.stderr || 'unknown error' };
}
}
results.passed = results.eslint?.passed && (results.jest?.passed ?? true);
results.feedbackPrompt = results.passed ? null :
`The generated code had validation errors:
${JSON.stringify(results, null, 2)}
Please fix the issues and regenerate.`;
return results;
} finally {
await rm(workDir, { recursive: true, force: true }); // always clean up
}
}Step 3: Build an Abstraction Layer Over Model Selection
Hardcoding model IDs creates brittle integrations that break when models are suspended, deprecated, or upgraded. A model router that selects based on task characteristics and falls back gracefully is essential infrastructure.
Hardcoding model IDs creates brittle integrations that break when models are suspended, deprecated, or upgraded.
// Verify all model IDs via: curl https://api.anthropic.com/v1/models -H "x-api-key: $ANTHROPIC_API_KEY" -H "anthropic-version: 2023-06-01"
interface TaskProfile {
type: 'quick-edit' | 'full-generation' | 'codebase-analysis';
estimatedInputTokens: number;
requiredOutputTokens: number;
}
interface ModelConfig {
id: string;
contextLimit: number;
outputLimit: number;
available: boolean;
costTier: 'low' | 'medium' | 'high' | 'premium';
}
const MODEL_REGISTRY: ReadonlyArray<ModelConfig> = Object.freeze([
{ id: 'claude-haiku-3-20250414', contextLimit: 200000, outputLimit: 8192, available: true, costTier: 'low' }, // Verify model ID at docs.anthropic.com/models
{ id: 'claude-sonnet-4-20250514', contextLimit: 200000, outputLimit: 8192, available: true, costTier: 'medium' }, // Verify outputLimit via API
{ id: 'claude-opus-4-20250514', contextLimit: 200000, outputLimit: 32000, available: true, costTier: 'high' }, // Verify outputLimit via API
{ id: 'PLACEHOLDER_FABLE5_ID', // Replace with official model ID when Anthropic announces it
contextLimit: 1000000, outputLimit: 128000, available: false, costTier: 'premium' }
] as const);
function selectModel(task: TaskProfile): ModelConfig {
const candidates = (MODEL_REGISTRY as readonly ModelConfig[])
.filter(m => m.available)
.filter(m => m.contextLimit >= task.estimatedInputTokens)
.filter(m => m.outputLimit >= task.requiredOutputTokens);
if (candidates.length === 0) {
throw new Error(
`No available model supports input=${task.estimatedInputTokens} output=${task.requiredOutputTokens}`
);
}
const preference: Record<TaskProfile['type'], ModelConfig['costTier'][]> = {
'quick-edit': ['low', 'medium'],
'full-generation': ['medium', 'high', 'premium'],
'codebase-analysis': ['high', 'premium']
};
const preferred = preference[task.type];
return [...candidates].sort((a, b) => {
const aIdx = preferred.indexOf(a.costTier);
const bIdx = preferred.indexOf(b.costTier);
const aRank = aIdx === -1 ? preferred.length : aIdx;
const bRank = bIdx === -1 ? preferred.length : bIdx;
if (aRank !== bRank) return aRank - bRank;
return b.outputLimit - a.outputLimit; // tiebreak: prefer larger output capacity
})[0];
}Step 4: Prepare Your Codebase for AI-Assisted Analysis
The quality of AI-assisted analysis depends directly on codebase legibility. Adding structured comments at module boundaries, maintaining architecture decision records (ADRs), and documenting module responsibilities in standardized formats all improve the signal-to-noise ratio when a codebase is injected into a large context window. Teams that have adopted these practices report measurably better results from AI-assisted code review; treating AI legibility as a code quality metric alongside human readability is worth the investment.
The Reported Mythos 5 / Project Glasswing Angle for Enterprise Teams
What Enterprise Developers Should Watch For
If Project Glasswing exists as reported, it would offer dedicated deployment environments with compliance and data residency guarantees. Enterprise teams should watch for official announcements and evaluate how such access fits within existing procurement processes. Positioning an internal business case early, before general availability, gives procurement cycles time to complete.
Enterprise vs. Startup Strategy Divergence
Enterprises with regulatory requirements and procurement budgets should monitor for official enterprise tier announcements and begin internal evaluation processes. Startups face a different calculus: build on the abstraction layer pattern, stay model-agnostic, and adopt higher-capability models the moment they become available without architectural changes.
Implementation Checklist: Your Forward-Compatibility Readiness Plan
Prompt Architecture
- Convert monolithic prompts to modular, composable segments
- Implement scalable context assembly with file delimiters and metadata
- Define explicit output format specifications for every prompt type
- Add self-validation instructions to generation prompts
Workflow Infrastructure
- Deploy model abstraction layer with fallback routing
- Build automated output validation pipeline (linting, testing, AST parsing)
- Implement token budget estimation for input and output
- Configure graceful degradation when preferred models are unavailable
Codebase Preparation
- Add structured comments at module boundaries
- Create and maintain architecture decision records (ADRs)
- Document module responsibilities and dependency relationships
Organizational Readiness
- Evaluate current API tier and potential upgrade paths
- Establish budget allocation for premium model usage
- For enterprise: monitor for official enterprise tier announcements
{
"forwardCompatibilityConfig": {
"models": {
"default": "claude-sonnet-4-20250514",
"preferred": "PLACEHOLDER_FABLE5_ID",
"fallback": "claude-opus-4-20250514"
},
"contextAssembly": {
"fileDelimiter": "===FILE: {{path}}===",
"includeMetadata": true,
"metadataFields": ["lineCount", "imports", "exports"],
"contextReserve": 0.15
},
"validation": {
"eslint": true,
"jest": true,
"astParse": true,
"autoFeedback": true,
"maxRetries": 2
},
"tokenBudgets": {
"quickEdit": { "maxInput": 50000, "maxOutput": 4000 },
"fullGeneration": { "maxInput": 100000, "maxOutput": 32000 },
"codebaseAnalysis": { "maxInput": 800000, "maxOutput": 16000 }
}
}
}Next Steps
The suspension of Fable 5 access, if temporary as reported, does not change the trajectory. The capabilities it reportedly represents (million-token context, six-figure output limits, adaptive reasoning) are the direction AI-assisted development is heading. Every preparation step outlined here improves developer workflows regardless of which specific model is currently available. The abstraction layer prevents lock-in. The validation pipeline catches errors from any model. The prompt architecture scales up or down.
Start with the model router and validation pipeline this week. When a higher-capability model ships, update the placeholder model ID to the official API identifier and set available: true.