

The simplest online database that could possibly work.
–Ward Cunningham
Different people have different ideas about what a wiki really is, but whatever angle you look at it, a wiki is software that handles complex problems with simple solutions.
Cunningham and Bo Leuf designed WikiWikiWeb, the first wiki in 1995, to be an open, collaborative community Website where anyone can contribute. Since then, programmers have created many wiki-inspired programs and wiki Websites. Most of these stay true to the goal of simplicity. Wikis can be used for a large variety of tasks, from personal note-taking to collaborating online, creating an internal knowledge base, assembling an online community, and managing a traditional website. The possibilities might make wikis seem like a daunting system, but commitment to simplicity makes wiki tools a breeze.
Key Takeaways
- Wikis are simple software solutions designed for complex problem-solving, allowing for easy editing and content management on websites.
- The first wiki, WikiWikiWeb, was created in 1995 to support open, collaborative community websites where anyone can contribute, emphasizing simplicity in design.
- Wikis feature straightforward markup rules, document history tracking, and automatic link creation, making them user-friendly for non-technical users.
- They are versatile tools for various tasks including personal note-taking, online collaboration, and managing traditional websites, with a structure that can grow organically based on content and user interaction.
- Advanced wikis, like Wikipedia, offer comprehensive features such as tracking of page edits, displaying recent changes, and managing contributions from a large community.
- Wikis support a democratic approach to content management where users can easily edit and revert changes, promoting a collaborative environment with minimal barriers to entry.
What’s so Good About Wikis?
- Wikis Simplify Editing Your Website: Each page on a wiki has an Edit link. If you want to change something on the page, click the link, and the wiki will display a simple editing screen. When you finish making changes, submit them by clicking a button, and, Voila! Your changes show up on the Website.
- Wikis Use Simple Markup: Even for geeky types like me, thinking about HTML and formatting gets in the way of good, clear writing. Wikis solve this problem by writing the HTML for you — you only need to learn a few simple markup rules. These rules are designed to make wiki markup easy to write and read by real people.
- Wikis Record Document Histories: If you make a mistake, don’t worry. A good wiki will save plenty of old copies of your pages and will let you revert to an older version of a page. In fact, many Wikis will display a comparison, called a diffˆ, which shows you the exact changes you have made to your page over time.
- Creating Links Is Simple With Wikis: Wikis store all your Website’s content in an internal hypertext database. The wiki knows about every page you have and about every link you make. If you use a wiki, you don’t have to worry about the location of files or the format of your tags. Simply name the page, and the wiki will automatically create a link for you.
- Creating New Pages Is Simple With Wikis: Wikis let you link to pages that don’t yet exist. Click on a link that points to a nonexistent page, and the wiki will ask you for initial content to put in the page. If you submit some initial content, the wiki will create the page. All links to that page (not just the one you clicked) will now point to the newly-created page.
- Wikis Simplify Site Organization: As wikis work like hypertext databases, you can organize your page however you want. Many content management systems require you to plan classifications for your content before you actually create it. This can be helpful, but only if what you want to convey fits a rigid mould. With a wiki, you can organize your page into categories if you want, but you can also try other things. Instead of designing the site structure, many wiki site creators just let the structure grow with the content and the links inside their content. But you don’t have to have it either way. I do all three on my own site. Visitors can navigate the site by following a storyline, drilling down through a hierarchy, or they can just browse with the natural flow of the internal links. Without the wiki, such complexity would be a nightmare. Now that I use a wiki, I also find my site structure easier to manage than when I used a template system and a set of categories.
- Wikis Keep Track of All Your Stuff: Because a wiki stores everything in an internal hypertext database, it knows about all your links and all your pages. So it’s easy for the wiki to show back links, a list of all the pages that linking to the current page. Since the wiki stores your document history, it can also list recent changes. Advanced wikis like the Wikipedia can even show a list of recent changes to pages that link to the current page.
- Many Wikis are Collaborative Communities: The original wiki allows anyone to click the Edit button and change the Website. While this may seem odd, many wikis are able to do this successfully without major issues in terms of vandalism. Remember, the wiki stores the history of each page. For each vandal, there are probably ten people who actually need the information that was there before, and who will take the time to click the button and reset the page to its former contents. Many of the wikis handle this challenge differently. Some are completely open, some restrict access, and one even has a democratic error/vandalism reporting system. How you deal with this challenge depends on what you plan to use the Wiki for, as we’ll see.
- Wikis Encourage Good Hypertext: In my recent article, Caffeinate Your Hypertext, I wrote that wikis are the purest form of hypertext available on the Web today. Many wikis sport features that make hypertext geeks drool, but the features aren’t the real reason wikis make great hypertext tools. They succeed because they make writing hypertext elegantly and easy. Effective Wiki writers don’t have to be geeks. They just need to be able to type.
It might be difficult to imagine a simple product that does everything I describe. So why not try it for yourself? Start out on your own computer; you don’t even need to install a Web server in order to play with a wiki. Notebook, which acts like a personal wiki for keeping track of notes and other ideas, runs as a regular computer application, and is available on multiple operating systems. It’s great for managing your brain.
Managing Your Brain by Wiki
Databases have been around ever since 1900, when the US Government commissioned a mechanical Census database. The creators of this machine started IBM a few years later. But before the invention of relational databases, Vannevar Bush was proposing something even wilder, something much more freeform: a hypertext database.
“A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.”
“The process of tying two items together is the important thing.”
–Vannevar Bush, in “As We May Think”, Atlantic Monthly, 1945
Hypertext theory was developed by people who wanted to use it to keep track of their own brains. Ted Nelson, who was inspired by Vannevar Bush’s vision of the future, coined the term “hypertext” while trying to build “a note-keeping program for preserving his every thought” (The Daring Proposal The Economist (London), 23 Aug 1986).
The same was true about the creation of the Web, as Tim-Berners-Lee’s online biography notes:
“he [Tim Berners-Lee, in 1980] wrote for his own private use his first program for storing information including using random associations. Named “Enquire”, and never published, this program formed the conceptual basis for the future development of the World Wide Web.”
–Tim Berners-Lee’s biography on W3.org
Wikis, which can be thought of as simple interfaces to a hypertext database, work well for keeping track of notes and interlinked information. In fact, I first ran into Wikis while looking for something to help my father take class notes in grad school. He chose to use Notebook, a personal Wiki, to do the job.
Notebook: Personal Hypertext Manager
While not geared toward Web publishing, Notebook is a perfect example of how wiki technology can work well in other settings. Its author describes it as a “personal Website.” Notebook was my first wiki, and I suggest you use it to familiarize yourself with the mechanics of creating pages, formatting them, and interlinking them. With Notebook, it’s fun to play around with the possibilities of hypertext. Notebook is a serious tool as well; I now use Notebook to keep track of research, ideas, and ToDo lists.
Notebook runs on GNU/Linux, MacOS X, Windows, and any other platform with TCL/TK support. Windows and MacOS X installation is a breeze — just download the program and run it. On GNU/Linux, things aren’t quite as smooth. Since version 1.1, Notebook depends on the Starkit software package, which is not included in most GNU/Linux distributions. Although I had to compile Starkit for GNU/Linux on my iBook, it’s much easier to install Starkit’s standalone tclKit binary.
When you run Notebook, you will be greeted with an un-editable, blank page. This confused me at first, until I read the documentation. To start using Notebook, you need to select New Notebook from the File menu. A dialog box then prompts you for a filename so it can create your wiki file.
In Notebook, new wikis automatically contain help information and a great tutorial (you can turn this off later in the preferences dialog). After you have created a wiki file, you’ll be greeted with Notebook’s Home page:
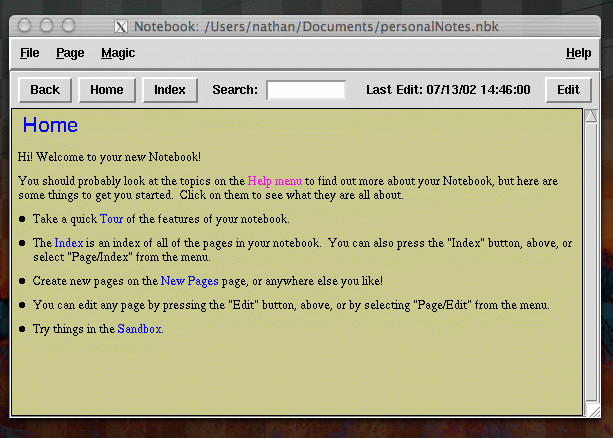
Notebook, a Personal Wiki
Notebook’s tour feature gives an excellent interactive tutorial on how to use a wiki. It describes many of Notebook’s features in detail and guides you through using Notebook effectively.
Notebook works much like a Web browser, with a few nice features. To follow a link, just click it. If you want to see what pages link to the page you’re on, click on the title. The “cycle” feature on Notebook works as the opposite of “back”. It lets you jump back to the home page and cycle through, following the exact path you used to get to the page from which you clicked “cycle.” If you want to edit a page at any time, just click the “Edit” button, and Notebook will bring up an editable text box of the page’s contents.
As with all wikis, the formatting rules are easier than most HTML, letting you focus on your primary task: content creation. Unlike most wikis, Notebook does borrow some ideas from HTML. Bold, italics, underline, and strike-through are marked with the HTML-like tags <b>, <i>, <u>, and <x>.
The rest of Notebook’s formatting system keeps closely to the rest of the wikis.
Wiki Formatting
While HTML likes to scrunch your words together no matter how the lines are broken up, lines are more important in wiki formatting. To create a new paragraph, just put a blank line between your paragraphs. For example, if you type the following text into the edit window…
In another moment down went Alice after it, never once
considering how in the world she was to get out again.
The rabbit-hole went straight on like a tunnel for some way,
and then dipped suddenly down, so suddenly that Alice had not a
moment to think about stopping herself before she found herself
falling down a very deep well.
…this shows up in the wiki as:
“In another moment down went Alice after it, never once considering how in the world she was to get out again.
The rabbit-hole went straight on like a tunnel for some way, and then dipped suddenly down, so suddenly that Alice had not a moment to think about stopping herself before she found herself falling down a very deep well.”
As you can see, blank spaces are important to the flow of a paragraph, but where you end your lines doesn’t matter to Notebook. Wiki formatting simplicity also carries over to the creation of bulleted lists.
Creating Links and Pages in Wiki
When creating links and pages, Notebook works just like a wiki, except it works offline. To link to the page, just put the page title in brackets. This keeps wiki markup very readable:
The [rabbit-hole] went straight on like a [tunnel] for some way,
and then dipped suddenly down, so suddenly that [Alice] had not a
moment to think about stopping herself before she found herself
falling down a very deep [well].
In the previous example, the word “rabbit-hole” would link to a page entitled “rabbit-hole,” the word “tunnel” would link to a page entitled “tunnel,” etc. Many online wikis, such as Wikipedia, also support an extended version of the link format. The extended version ([[pagename text]]) allows the editor to specify the link text. Here’s an example:
The [[rabbit-hole]] went straight on like a [[rabbit-hole tunnel]] for some way,
and then dipped suddenly down, so suddenly that [[characterlist Alice]] had not a
moment to think about stopping herself before she found herself
falling down a very deep [[rabbit-hole well]].
In this case, the words “rabbit-hole”, “tunnel”, and “well” all point to the “rabbit hole” page, and rightly so. They all refer to the rabbit hole. The word “Alice” now links to a central list of characters. The extended markup, which isn’t supported by Notebook, comes in handy on other wikis.
The original wiki uses a different method to link pages, called JoinCapitalizedWords or CamelCase, and is still used in many Wikis. This eliminates the need for brackets, but reading a PageWithMany JoinCapitalizedWords can be tiring.
If you create a link and the page does not yet exist, clicking on the link will automatically create the page and bring up an edit window for the new page. Here’s what happens in notebook when you click a link to a nonexistent page:
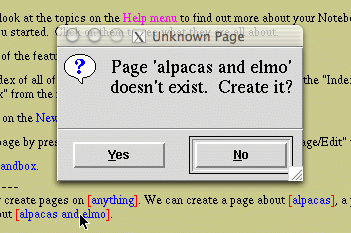
Create a new page in Notebook by clicking a link to a nonexistent page
As it’s an offline application, Notebook also sports many advanced features that aren’t found in ordinary Wikis, such as embeddable TCL code, which can collect information from other pages, perform statistical analyses, or autogenerate information. These “magic” features allow users to create handy plugins as well.
Unfortunately, Notebook cannot yet publish to an online wiki. If you want that feature, you may want to try WiKit, the Tcl’ers Wiki. It sports interfaces for both the Web and an os-independent client application similar to Notebook. Although the client application for the Tcl’ers Wiki isn’t as nice as Notebook, it can publish to the online wiki, which makes it a very useful wiki interface application.
Notebook is a great application for keeping track of notes, thoughts, and other bits of information. My father, who is not particularly geeky, uses it to record his notes for grad school. But Wikis are most powerful when you put them on the Web.
Wiki as Web Community Software
Ward Cunningham and Bo Leuf designed the first wiki because they wanted to make their hypertext database collaborative.
From the very start, they decided that anyone should be able to edit any page from a simple Web form. While this may seem to invite vandalism, they overcame this problem by storing the history of each document. If vandalism does occur, anyone can roll the site back to how it was before the vandalism.
Making the site easily editable gives it numerous advantages. First, it encourages many people to participate to create the Website together, which is why wikis make great knowledgebases. On both public and internal Websites, wikis allow writers and editors direct access to the Website, reducing the load on IT staff. The following is a list of some public wiki knowledgebases:
- Wikipedia: an extensive online encyclopedia. The Wikipedia is one of the largest knowledgebase wikis. It has now come under a nonprofit organization, the Wikimedia Foundation. The Wikipedia is a good example of a wiki that stays very professional, and very on-task with its professional goals, even though the contributors are random volunteers from around the world. It has a number of very interesting features. The Wikipedia:
- The Tcl’ers Wiki: a one stop shop for anything relating the Tcl programming language. This also is a publicly editable wiki that manages to provide a mindblowing amount of useful information. However, it has more of a community feel to it than does the Wikipedia. This more laid-back style of wiki doesn’t diminish the quality of its content in the least. Their “welcome visitors” page gives a good insight into what makes The Tcl’ers Wiki special.
- The Emacs Wiki: Like the Tcl’ers Wiki, the Emacs Wiki is geared toward users of a particular piece of software. On the Emacs Wiki, users of emacs can swap ideas, documentation, and plugin code with each other. While serious in nature, the Emacs Wiki has built a community that enjoys a bit of humor as well.
Many companies and universities use wiki software to create internal knowledgebases, connect their employees/students, and provide a place for employees/students to share ideas and brainstorm:
- British Telecom: BT maintains numerous wikis internally to help employees collaborate. They also have set up TWiki as a B2B site to provide documentation on information standards and foster discussion with their customers.
- Colorado State University, USA: maintains numerous FAQs for students. If someone encounters and solves a problem, they can post the solution easily. IT staff just need a browser to edit the page. This wiki saves the University time and money, since they don’t need specialized software to maintain an internal computer services Website.
- TWiki has been used by many top companies to connect people and manage information. Disney, Motorola, SAP, Secure Works, and Wind River all use TWiki. TWiki is even used in a mission critical role at Hammarskjold Information to manage the creation of a bi-monthly magazine. More success stories are available on the TWiki site.
Wikis make great community sites, as well. Many wiki software packages allow users to register for usernames, putting a face to all the changes a particular person makes. The MeatballWiki is a hub for such online communities. Wiki-ers from all over use to MeatballWiki to come together and link their wikis with each other. The MeatballWiki members have even created a clever, creative tour bus trip of wikis. Another great community Wiki is GreenCheese, which is a wiki dedicated to humorous writing. More ideas can be found at the Practical Wiki Applications FAQ. One author used a wiki to collaborate with several other authors and write a 120 page book in three days (read toward the bottom). When creating a community wiki, be creative!
Choosing Wiki Software
I purposely saved this discussion until now, because there are so many different pieces of software available. Here are some of the programs I’ve tried:
- Wiki Wiki Web (very nice): the original wiki, this one’s plain and simple. WikiWikiWeb is written in Perl and requires no special database features on your Web host. One great feature of this wiki is the ability to autogenerate maps of the interlinked connections with surrounding pages. You can get WikiWikiWeb from the Running Your Own Wiki FAQ and the WikiBase page.
- UseMod (simple, excellent): a very simple-to-install Wiki — the entire program is just a single Perl script. While it may seem like overkill to throw an entire Web application into a single script, UseMod is very compact, yet extremely powerful. The Meatball Wiki uses UseMod. Configurations are made through a convenient configuration file. UseMod has many features, including an RSS feed, but it manages to stay simple and easy to use. UseMod contains as many of the concepts of pure hypertext as can be implemented simply on the Web, including the handy ability to include bits of wiki content from other pages, a technique called Transclusion.
- TWiki (many features but somewhat confusing): the most complex wiki I’ve set up. Twiki is great because it has so many features, but at the same time, the amazing number of features also makes it confusing. If you have a lot of time, Twiki is immensely rewarding; if you don’t, you will likely get lost. Twiki is often used by companies and workgroups because it has permissions systems, categorizing features, and even progress bars on TODO lists. Twiki is written in Perl as well; you can download it from Twiki’s release page.
- Moin Moin (excellent, if you have Python): a simple to set up, powerful Wiki, if your Web host has Python support. MoinMoin also has user management support. The MoinMoin Wiki has more information on installing MoinMoin on the Install Documentation page.
- PHP Wiki (nice, if you have a database server, but complex): If you want a PHP Wiki, then PHP Wiki may be just what you want. It requires a SQL-based relational database server like MySQL or PostgreSQL to run. It has many features, including user authentication. Like TWiki, PHP Wiki has many features and can seem a bit complicated if you just want a simple wiki. Unlike most wikis, PHP Wiki has template support. Templates are hard to create and require a good understanding of PHP object oriented programming.
- PHP Wiki Processor (what can I say? I use it!): Why not use a Wiki in the role of a regular content management system? I decided to try it out, and am very pleased with the result. PHP Wiki Processor keeps track of my pages and links at my site. Since it’s my personal site, I want to remain the sole creator — I can’t have anyone change my Resume, for example. So I set up PHP Wiki Processor to generate a set of static PHP pages from all my wiki pages. I can still edit my page online through a secure connection, but I decide who gets to change content on the site. When I load the site, I see an administrative wiki interface. Everyone else sees just a Website, which is how I want it. PHP Wiki Processor has simple, easy-to-use template support, and I was able to transfer my previous site header and footer easily. My knowledge of PHP did help, since I tend to tweak things endlessly. A thorough knowledge of PHP, however, is not necessary to use PHP Wiki Processor effectively.
Conclusion
Wikis are great hypertext tools that let one person or a group of people manage content easily. They are used to create static Websites, manage online communities, connect businesses with their customers, and even write magazines and books. Remember, the Wiki is “the simplest online database that could possibly work.” The possibilities are endless!
Frequently Asked Questions (FAQs) about Wikis
What is the history of wikis?
The concept of wikis was first introduced by Ward Cunningham in 1995. He created the first wiki, WikiWikiWeb, to facilitate the exchange of ideas, information, and experience among programmers. The term “wiki” comes from the Hawaiian phrase, “wiki wiki,” which means “super fast.” Over the years, wikis have evolved and are now used in various fields, including education, business, and more.
How does a wiki differ from a blog?
While both wikis and blogs are tools for online collaboration and information sharing, they serve different purposes. A blog is typically managed by an individual or a small group, with posts appearing in reverse chronological order. On the other hand, a wiki is a collaborative platform where multiple users can contribute and edit content. The information in a wiki is organized in a non-linear, interconnected way.
What are the benefits of using a wiki?
Wikis offer numerous benefits. They promote collaboration, as multiple users can contribute and edit content. They also provide a centralized location for information, making it easier to manage and retrieve. Additionally, wikis have a version control system, allowing users to track changes, revert edits, and maintain the integrity of the information.
How secure are wikis?
The security of a wiki depends on its settings. Some wikis are open to the public for viewing and editing, while others are private and require user authentication. Most wikis have a version control system, allowing administrators to track changes and revert any unwanted edits. However, like any online platform, wikis are susceptible to cyber threats, so it’s essential to follow best practices for online security.
Can I use a wiki for project management?
Yes, wikis can be an effective tool for project management. They provide a centralized location for project documentation, task lists, and collaboration. Team members can easily access and update project information, improving communication and efficiency.
How do I start a wiki?
Starting a wiki involves several steps. First, you need to choose a wiki software or platform. Then, you need to set up the structure of your wiki, including its main categories and pages. After that, you can start adding content and inviting others to contribute.
What are some popular wiki platforms?
There are numerous wiki platforms available, each with its own features and benefits. Some of the most popular ones include MediaWiki, the software behind Wikipedia; DokuWiki, a simple and lightweight platform; and Tiki Wiki, a robust platform with a wide range of features.
Can I use a wiki for personal use?
Absolutely! Wikis can be used for a variety of personal purposes, such as organizing information, planning events, or documenting personal projects. You can choose to keep your wiki private or share it with others.
How do I edit a wiki page?
Editing a wiki page is usually straightforward. Most wikis have an “edit” button or link on each page. Clicking this will open an editor where you can modify the text, add links, insert images, and more. Once you’re done, you can save your changes and they will be immediately visible on the page.
What is the future of wikis?
The future of wikis looks promising. As collaborative tools, they are becoming increasingly important in a world where remote work and online learning are becoming the norm. We can expect to see more advanced features, improved usability, and wider adoption of wikis in various fields.
Nathan, also known as The Rubber Paw, programmed his first game of Pong in 1994. A web professional since 1998, Nathan likes tech writing so much, he's studying English at Elizabethtown College.
