

Key Takeaways
- Nick Quaranto revolutionized gem authoring in 2009 by launching a new gem repository called Gemcutter.org, which later became RubyGems.org, the Ruby community’s default gem repository. This allowed any Ruby developer to publish a new gem simply by running “gem push my_awesome_gem.”
- When a new gem is pushed to RubyGems.org, a four-step process is initiated to verify the gem and the person pushing it. Once verified, the gem and the gemspec are sent to S3, and a job is kicked off to refresh the gem indexes.
- RubyGems.org uses CloudFront to serve the gems and gemspecs because they do not change often. CloudFront, a CDN, has nodes all over the world, ensuring quick and efficient downloads for users.
- RubyGems.org is an open-source project that welcomes contributions from the community. This can range from reporting bugs, suggesting new features, improving documentation, or submitting code changes. The platform also has a help site and a “guides” site for tutorials and resources.
 |
| RubyGems.org has made it much easier for all of us to contribute Ruby gems |
Nick Quaranto (@qrush) revolutionized gem authoring in 2009 by launching a new gem repository called Gemcutter.org. Suddenly, for the first time, any Ruby developer could publish a new gem simply by running “gem push my_awesome_gem.” The speed and simplicity of this new process caused an explosion of Ruby gem development and publishing. Gemcutter.org was later moved to RubyGems.org and became the Ruby community’s default gem repository.
I enjoyed listening to Nick chat with the RubyRogues about RubyGems.org a couple of weeks ago, especially the stories about how Nick got started developing Gemcutter and its early history. Then last week I had the opportunity to chat with Nick about how RubyGems.org actually works. I was curious to know more about what happens on the server when I push a new gem file, how it serves gems to everyone so quickly, and how it works with the new Bundler 1.1 dependency API. Here are a few highlights of our conversation…
Q: Hi Nick, thanks for your time… I really appreciate it!
Heyo – no problem.
Q: I was thinking of writing about how RubyGems.org works internally, and I decided… why not ask you first? So today I have a bunch of technical questions for you, and a few diagrams as well. You can set me straight and correct the mistakes in my diagrams :)
Sure!
Pushing a New Gem to RubyGems.org
Q: What happens on the RubyGems.org server when someone runs “gem push”?
That’s a really good question. I’ve actually considered doing a talk on this subject. First, a controller picks it up the request and then we need to figure out what the client gave us. I think it’s the Pusher class that handles most of that. Using a four step process, it figures out:
- What did you give us?
- Have we seen it before?
- Are you someone who’s allowed to mess with this gem?
- Then we actually save it.
Given all of those things are cool: we’ve found the gem, it’s valid, you’re on the owners list, we then need to send both the gem and the gemspec out to S3, and kick off a job to refresh the gem indexes.
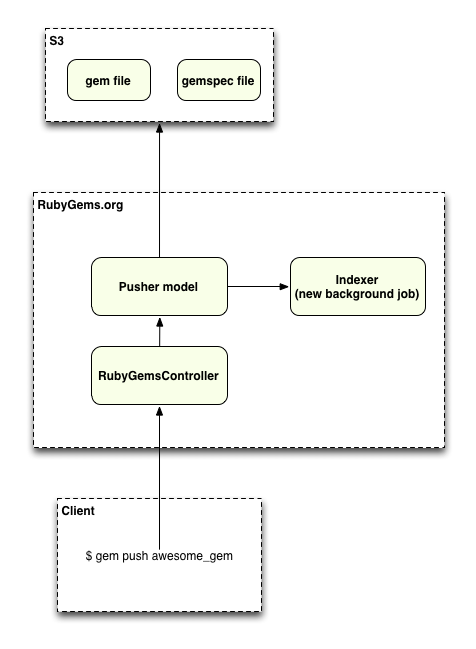
Gem Indexes
Q: You just mentioned “gem indexes” – what are the gem index files and why does RubyGems need them?
The index is what gem fetch, gem install, and gem list use to figure out what’s available. Refreshing that index takes a while, because there are almost 200,000 gems now.
Even though we can put each gem in a place where everyone can download it immediately, it’s still important that we update the index frequently. This is because actually the RubyGem clients don’t know how to download new gems until they appear in the index.
Q: How do you create the index files?
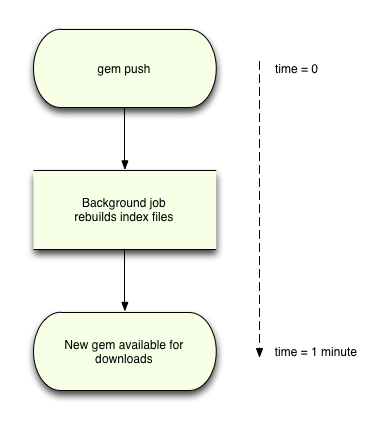
I used to rebuild the index immediately when you pushed, and it would take about a minute, and the user would just have to wait while it was churning away on the server. So, when I moved it to Heroku, they told me this was a bad idea since Heroku kills requests after 30 seconds. I had to figure out a better way to do it. So that’s how I learned about delayed_job.
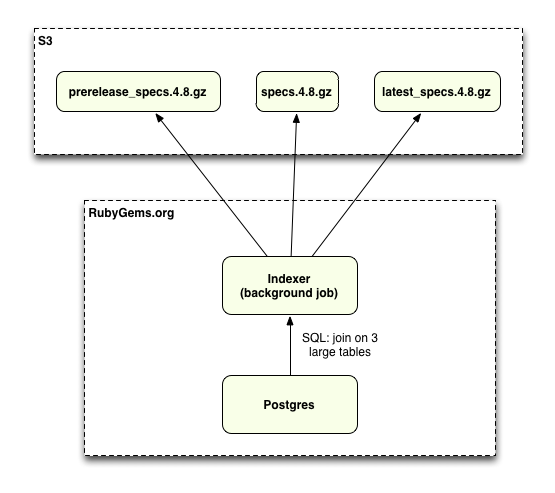
Q: How many gems are there now? How long does it take the delayed_job background job to rebuild the index?
Right now there are 177,000 indexed gems, and it takes around a minute or so to generate the entire index. This is how long you have to wait for your gem to be installed. And that’s basically the whole process.
I think most people just assume that, once you push, it’s done – but it’s actually not. I don’t think we do a good job right now of telling them: “Hey you’ve got at least a minute to wait.” I think people are used to the instantaneousness of it now.
Serving Gems
Q: How does RubyGems.org serve the actual gem files when developers run “gem install” or “bundle install?”
The app actually started out as two little Sinatra apps. One was for reimplementing the gem server; that’s on everyone’s RubyGems install and that’s how you can serve gems off of your own machine. I had to reimplement it because it had to be backed by a database and because it had to work outside of a file system. And the other Sinatra app was the UI. Although eventually I got to the point where I needed Rails, not Sinatra, for the UI.
I couldn’t call the Sinatra app “Gem Server” so I thought: What the closest thing to a server in a restaurant… and I said oh: “Hostess!” The “Hostess” is still in there, and that’s still Sinatra. And I think it’s fine for a Sinatra app, because the routes are really weird, because you’re sitting on a file system serving up actual files, because that’s how it was built, originally. And I think if they were Rails routes, and they certainly could be, they would be weird and gross.
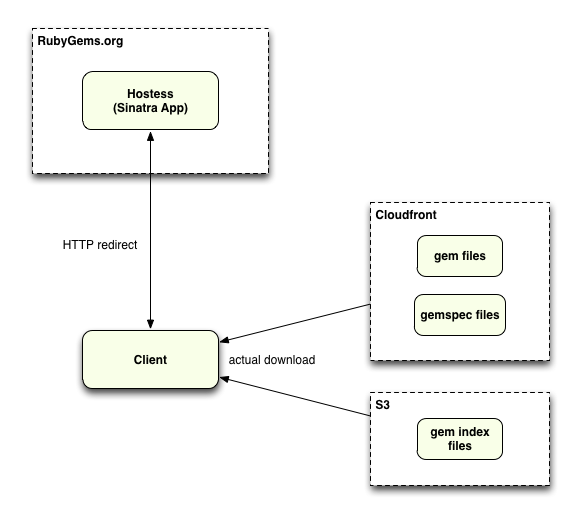
Here’s one of the routes from the Hostess Sinatra app that Nick was talking about, which redirects clients to download the gem index files from S3:
[gist id=”1700219″]
Q: What is CloudFront? Why does RubyGems.org use that?
CloudFront is used to serve the gems and gemspecs because they never really change. CloudFront is a CDN so there are nodes all over the world: there’s some in Japan, 1 or 2 in Europe, a few in the US, China and I think there’s one in South America. Those serve the big downloads for us: the gems and the gemspecs. The nice thing is that when you push those they are atomic and never change, you never need to update one.
Redis and the Bundler 1.1 API
One of the most exciting new features of RubyGems.org is the fast API it provides to obtain gem dependency information. To learn more about the API and how Bundler 1.1 uses it, see my article from October: Why Bundler 1.1 will be much faster.
Q: I heard once that you used Redis to help implement the dependency API that Bundler 1.1 uses. Why did you use Redis for this?
We wanted it to be really fast, and I think when Matt Mongeau from Thoughtbot and I were originally playing with it, we may have tried to do it inside of Postgres first and the queries were looking really gross and long. And we knew the data wasn’t going to change – well I guess “the data isn’t going to change that much” isn’t a good argument. I really enjoy Redis and I like messing around with it and we were using it pretty heavily for counting downloads, I think I wanted to just try it out and see how fast it would be, and it ended up being really damn quick to resolve that first tree for the dependencies.
If we were to use Postgres for this, it would be a big join across three tables. And they’re big tables too, especially the dependency table. We wanted this to be fast – I don’t know maybe when Bundler 1.1 comes out it will all burn down.

Some Code Details
Q: Let’s take a closer look at the Pusher class, which you mentioned earlier, [Pusher] is the code that catches new gems and pushes them to S3 and CloudFront. I noticed that it’s not based on ActiveRecord and does not correspond to a database table. Is this a good idea in general?
I think it’s OK to have models that are ActiveRecord-ish. However, when I wrote this, it was before ActiveModel was around, so I would love for it to use validations and it kind of already uses “save”.
Here’s a small part of the Pusher class that we are discussing; this is the code that processes gems that are pushed to RubyGems.org:
[gist id=”1700233″]
Q: What about the “process” method – why did you decide to write it that way, calling out to 4 other methods? Is that a pattern that other people should learn from and emulate?
I see this kind of thing a lot – you split methods into discrete steps and call them one at a time, instead of having one giant method. I think that’s a fairly common pattern. I think the difference here is that I need them to be chained together. If I remember they used to be logical ANDs and not binary ANDs. I needed this to be a chain of things that happened and nothing with ActiveRecord kind of fits that.
Other Contributors
Q: Who else helped you out on RubyGems.org? Are there any other contributors?
The first two people to mention are Tom Copeland (github twitter) and Evan Phoenix (github twitter). They’ve been helping out a lot! Evan’s on the RubyGems core team, so he knows a lot about what’s going on in the client side that I have no idea about. Tom’s been our sysadmin for a while; he’s been the sysadmin for RubyForge as well.
Those two guys have helped out a lot. Beyond that, pretty recently I put out a call for committers, and three guys have stepped up to help me:
- Erik Michaels-Ober (github twitter),
- Gabriel Horner (github twitter) and
- Christopher Meiklejohn (github twitter).
They’ve been helping out a lot; Erik wrote a command line wrapper for the API called “gems” and he basically got inside of my brain when implementing the API and needed to discuss things with me that resolve the mental issues he was having with my brain :) So I decided: if you want to fix all these things then you might as well help me out with this! He’s been helping out a lot with pull requests and keeping the site updated.
Gabe is a Boston guy; he’s helped out a bunch with pull requests and such, and I’ve bounced a lot of ideas off of him. I’m not a sysadmin at all; I know how to do some things, but not when it comes to actual hardware and machines.
And Chris, who works at Swipely.com in Providence, has been great with not only fixing bugs but he wanted to help out making our infrastructure better. I’d say that those 5 have helped out a ton.
What Else Do You Need Help With?
Q: Aside from mirroring and the download graph API, both of which you mentioned on the RubyRogues podcast, what else do you need help with?
Anything on the issues list is open, if you want to work on it, we have plenty of people who will merge your stuff. If you’re looking for more “soft” things to do, things that don’t involve code, we have a help site (help.rubygems.org) that is filled with a lot of issues that can often be answered without having someone with server access involved. There are also a lot of questions on StackOverflow.
Another thing is that we have a “guides” site (guides.rubygems.org) This has tutorials – how would I do certain things? If you think there are things that people are running into a lot, you can throw that kind of thing here. For example, I have a little list going of talks I’ve found, tutorials and whatnot on a Resources page there.
Don’t be afraid to bug any of the contributors, especially if you’re looking for something to do. I’m more than happy to help people get contributing!
Thanks!
Thanks for all your time Nick – it was a real pleasure looking at your code and trying to get some understanding of what’s going on. Thanks a lot Nick! Bye…
I’m glad you didn’t run away screaming! That’s a good sign… thanks dude.
Frequently Asked Questions (FAQs) about RubyGems.org Internals
What is the main purpose of RubyGems.org?
RubyGems.org is the Ruby community’s gem hosting service. It allows users to publish and install gems, which are packages containing Ruby applications or libraries. The platform provides a standardized format for distributing Ruby programs and libraries, making it easier for developers to manage and install code.
How does RubyGems.org differ from other gem hosting services?
RubyGems.org is a public repository that hosts a vast number of gems. It is the default package manager for the Ruby programming language, meaning that any gem published on RubyGems.org is instantly installable by any Ruby developer around the world. This is not necessarily the case with other gem hosting services, which may be private or have a more limited selection of gems.
How can I publish my own gem on RubyGems.org?
To publish your own gem on RubyGems.org, you first need to create a gem using the ‘gem’ command in Ruby. Once your gem is created, you can publish it on RubyGems.org by using the ‘gem push’ command, followed by the name of your gem file. You will need to have an account on RubyGems.org to do this.
What is the role of the RubyGems software?
The RubyGems software is a package manager for the Ruby programming language. It provides a standard format for distributing Ruby programs and libraries, and a tool for managing the installation of gem packages. The software interacts with the RubyGems.org repository to find and install gems.
How does RubyGems.org ensure the security of gems?
RubyGems.org has several measures in place to ensure the security of gems. It uses Secure Sockets Layer (SSL) to encrypt communications between the user and the site. Additionally, each gem has a cryptographic signature that can be used to verify its integrity.
Can I use RubyGems.org if I’m not a Ruby developer?
While RubyGems.org is primarily designed for Ruby developers, it can also be useful for those who are not. The site hosts a wide variety of gems that can be used for various purposes, such as web development, data analysis, and automation. Even if you’re not a Ruby developer, you may find a gem that suits your needs.
How can I contribute to RubyGems.org?
RubyGems.org is an open-source project, and contributions are welcome. You can contribute by reporting bugs, suggesting new features, improving documentation, or submitting code changes. To get started, you can visit the project’s GitHub page.
What is the relationship between RubyGems.org and RubyGems software?
RubyGems.org and RubyGems software work together to provide a complete package management solution for Ruby. The RubyGems software is used to create, install, and manage gems, while RubyGems.org is the repository where these gems are hosted and shared with the Ruby community.
Can I host my own private gems on RubyGems.org?
RubyGems.org is a public repository, meaning that any gem published on the site is available to all users. If you want to host private gems, you will need to use a private gem server or a service that offers private gem hosting.
How can I find a specific gem on RubyGems.org?
You can find a specific gem on RubyGems.org by using the search function on the site. Simply enter the name of the gem you’re looking for in the search bar, and the site will display a list of matching results. You can also browse the site’s directories to discover new gems.

