

Just about every type of datastore has some form of indexing. A typical relational database, such as MySQL or PostreSQL, can index fields for efficient querying. Most document databases, like MongoDB, contain indexing as well. Indexing in a relational database is almost always done for one reason: speed. However, sometimes you need more than just speed, you need flexibility. That’s where Solr comes in.
In this article, I want to outline how Solr can benefit your project’s indexing capabilities. I’ll start by introducing indexing and expand to show how Solr can be used within a Rails application.
Key Takeaways
- Solr, a mature technology used by companies like Netflix, can augment existing relational databases to provide enhanced querying capabilities and flexibility, making it an effective solution for indexing needs that go beyond the capabilities of relational databases.
- Sunspot, a Ruby library, facilitates integration between Ruby and Solr, providing a clean Domain Specific Language (DSL) to define how relational data should be indexed with Solr.
- Solr’s configuration can be customized to handle complex search scenarios, such as using the SynonymFilterFactory to treat certain words as synonyms, improving the search results’ relevance and accuracy.
- Sunspot’s DSL provides a readable and flexible way to define search queries, making it possible to handle complex search requirements with ease, while also offering features like faceting, which allows for hierarchical categorization of search results.
What is an Index?
Indexing data is a very old concept. It far predates relational databases and computers entirely. Index cards have been used in a wide variety of situations, especially in library catalogs. Librarians index their books using a number of techniques, one of which is alphabetization. A simple index could be contrived by listing all the books that begin with A, then all the books that begin with B, and so on. When searching for a book, say “A Tale of Two Cities”, you look at the first letter of the title, “A”, and then jump directly to the “A” section in your library index.
The purpose of indexing, no matter where it’s applied, always pertains to organizing data so it can be extracted quickly. You can imagine organizing the library catalog by genres, in which case “A Tale of Two Cities” might fall into “Fiction”. The librarian would then jump directly to the “Fiction” section.
Relational Database Indexing
All production-ready relational database systems contain indices. Frequently you want to index by a foreign key so that querying for that foreign key can be done efficiently. This can dramatically increase performance when performing joins, for instance. Both MySQL and PostgreSQL support “full-text indexing” which allows you to query against a large block of text for bits and pieces contained therein.
If you’re just looking to have a simple search box on your site, full-text indexing using your already-existing relational database might be the way to go. It has two major advantages: you’re working within the same tool and your indices are always up-to-date. It has one major drawback: it’s not flexible enough to handle “outside the box” indexing situations.
Solr – When Your Relational Database Isn’t Enough
If you stick to a relational database for all your searching needs, you’ll often find yourself creating awkward and inefficient queries. This is a good sign that you’ve reached the limits of what the database can provide. That’s where Solr comes in. It’s designed to augment your existing relational database and provide additional means of querying the data.
Solr is a very mature technology, originally created in 2004 and used by Big Dogs like Netflix and the Internet Archive. Built on Lucene, Solr provides you with a different way to define your indices. Effectively, Solr helps redefine your relational data into a more document-oriented structure efficient for querying.
Here’s how Solr fits into your Rails application:
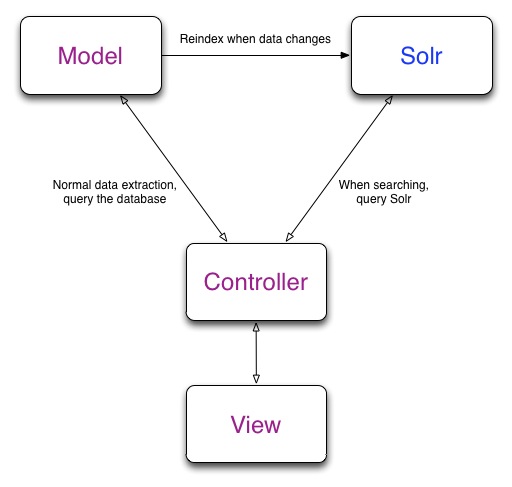
Sunspot – The Ruby/Solr Love Child
Sunspot is the king of integration between Ruby and Solr. It provides a clean DSL (Domain Specific Language) to define how you want your relational data indexed with Solr. Let’s contrive an example.
Say we have a Product model which has the following attributes:

We have a normal ActiveRecord model to define our database with Ruby:
[gist id=”1990156″]
If we wanted to search for products with a name containing “cities” and expect to see “A Tale of Two Cities”, we might construct the following query:
[gist id=”1990666″]
This isn’t nearly flexible enough in most cases. What if we wanted a search for “cities” to also include “New York: A Big City”? This technique wouldn’t provide us with the results we desire. Let’s introduce Sunspot.
To get started with Sunspot, put it in your Gemfile:
[gist id=”1990681″]
Grab the gems:
[gist id=”1990684″]
Generate a Sunspot configuration file so your Rails app knows where to find the server:
[gist id=”1990690″]
By including the ‘sunspot_solr’ gem in your Gemfile, Sunspot will provide you with a copy of Solr. Start the Solr server by running:
[gist id=”1990692″]
At this point, you should be up and running with Solr. Let’s redefine our Product model. I won’t include validations again, I’ll just pretend they still exist.
[gist id=”1990160″]
What we’ve done in the above model is tell Solr how we want it to index our Product model. We’ve told it to treat the name and color fields as text and the used field as a boolean. Defining something as “text” in Sunspot means that it’s full-text searchable. In other words, when you search against the name and color fields, it will find partial matches (ie a search for “bread” will return “bread and butter”). We’ve also told Sunspot that we want the name field to have twice (2.0) the prevalence as the color field. If a search brings up results by both name and color, the results matching against the name field will be more relevant.
Searching for data in a Solr index usually happens at the controller level. Let’s take a look at how we can query Solr for products matching “cities” that are not used:
[gist id=”1990659″]
This search would return new copies of “A Tale of Two Cities” and any other books with “cities”. The search is case-insensitive by default. Searches can also contain ranges, date comparisons, set includes, greater than and less than queries, and more.
As you can see from the model and search definition, Sunspot provides us with a clean and readable DSL. This is one of my favorite aspects of the library.
Digging Deeper – Solr Configuration
You can accomplish a lot without ever touching the Solr configuration. By default, Solr will break down text fields into their individual words and then convert them to lowercase. This allows the full-text queries to be case-insensitive. The ‘sunspot_solr’ gem gives us a default schema.xml file to use. schema.xml is usually the place you’ll go when you want to configure Solr at a lower level (you might also touch solrconfig.xml). This file usually lives at {RAILS ROOT}/solr/conf/schema.xml. Let’s take a look at how our text fields are being defined:
[gist id=”1990169″]
We have three interesting definitions in the default Solr configuration shipped with Sunspot. Here’s what they do:
- StandardTokenizerFactory tokenizes our text. In other words, it breaks down our text field into its individual words.
- StandardFilterFactory provides Solr a means of searching the data by the tokenized text.
- LowerCaseFilterFactory converts all the tokenized words into their lowercase form.
New filters can be appended to the end of this text field definition. The filters happen sequentially, so filters appended to the end of the list will cascade from the filters before it.
If we wanted our search for “cities” to return the book titled “New York: A Big City”, we would use a stemmer. The goal of any stemmer is to break apart a word into its “stem”. So, then stem of “walked”, “walking” and “walker” would be “walk”. Let’s make our search more robust by defining a Solr stemmer on our text fields:
[gist id=”1990171″]
We’ve now told Solr that we want to stem any text we index after it’s first been tokenized and then converted to lowercase. We have a problem, however. Not all stemmers are intelligent enough to replace the “ies” with a “y” in the case of stemming “cities”. In fact, this job is usually left to a lemmatizer. Stemmers and lemmatizers are both language specific. That is, stemming an English word is much different than stemming a Romanian word, for obvious reasons.
If we tried to stem the word “cities”, what we would actually get is the word “citi”, which is clearly incorrect. Try stemming some different words on this online stemmer. It feels like we’ve hit a rough spot with Solr, and we truely have. Solr doesn’t have a lemmatizer built-in. We could write such a filter but it would be a painstaking task. Possibly, a better option is to use the SynonymFilterFactory.
Digging Even Deeper – Solr Synonyms
Solr has an understanding of synonyms and allows us to define our own. You can configure Solr to return matches on different words, based on its synonyms. Such synonyms are defined in a synonyms.txt file like so:
[gist id=”1990671″]
The above synonyms.txt file tells Solr that we would like to treat the word “citi” as though it is the word “city” and the word “copi” as “copy”.
We now need to put the correct filter in our schema.xml file:
[gist id=”1990175″]
We’ve now told Solr that we would like to consider the stems “citi” and “copi” as their rightful lemmatization, “city” and “copy”. At this point, when a book with a name of “New York: A Big City” is indexed, the following steps happen:
- “New York: A Big City” is broken into its tokens: [“New”, “York”, “A”, “Big”, “City”]
- Each token is converted to lowercase: [“new”, “york”, “a”, “big”, “city”]
When a search for “cities” is performed, the following steps happen:
- “cities” is broken into tokens (only one token in this case): [“cities”]
- Each token is converted to lowercase (no effect in this case): [“cities”]
- Books matching “cities” are found
- Each token is stemmed: [“citi”]
- Books matching “citi” are found
- Each token is checked or synonyms: [“city”]
- Books matching “city” are found – returning “New York: A Big City”
Wrapping Up
Solr is a phenomenal technology that provides powerful search capabilities. We’ve touched on some history behind indexing and the painpoints of relational database searching. We’ve also looked at how we can utilize Solr in a Rails app using Sunspot and dug deep into Solr configuration to show how to handle a tough edgecase. But we’ve only scratched the surface. One of the most powerful features of Solr is faceting, the concept of breaking apart your index into hierarchical chunks for which you can drill into to find relevant results. Usually, as you drill into a category (facet), more categories are exposed to show deeper layers of facets. Sunspot handles faceting with finesse. Newegg and Amazon both exhibit great uses of faceting when exploring categories on the left navigation.
I hope this article has intrigued you by exposing some of the deeper features of Solr. There’s a lot to learn and taking it step-by-step is always the best approach. I encourage you to get comfortable with Solr so you can handle complex search queries with ease.
Frequently Asked Questions (FAQs) about Flexible Searching with Solr and Sunspot
What is the main difference between Solr and Sunspot?
Solr is a standalone, enterprise-grade search platform built on Apache Lucene. It provides powerful search and indexing capabilities, and it’s highly scalable and customizable. On the other hand, Sunspot is a Ruby library that provides a powerful and flexible interface for Solr. It uses the power of Solr under the hood, but provides a Ruby-friendly API, making it easier for Ruby developers to integrate Solr into their applications.
How do I install and configure Sunspot in my Ruby application?
To install Sunspot, you need to add the gem to your Gemfile and run the bundle install command. After that, you can generate a configuration file using the rails generate sunspot_rails:install command. This will create a sunspot.yml file in your config directory, where you can specify your Solr server settings.
How can I index my data with Sunspot?
Sunspot provides a DSL for defining how your Ruby objects should be indexed. You can specify which fields to index and how they should be treated by Solr. Once you’ve defined your indexing rules, you can use the Sunspot.index method to index your objects.
How do I perform a search with Sunspot?
Sunspot provides a search method that you can use to perform a search. You can pass a block to this method to specify your search criteria. The search method returns a Sunspot::Search object, which you can use to access the search results and other information about the search.
Can I use Sunspot with Rails?
Yes, Sunspot is designed to work seamlessly with Rails. It provides a set of Rails-specific features, such as integration with ActiveRecord and ActionView. You can use Sunspot in your Rails controllers and views just like you would use any other Rails component.
How can I customize the search results returned by Sunspot?
Sunspot provides several ways to customize your search results. You can sort the results, paginate them, or limit them to a certain number. You can also specify which fields to return in the results, or boost certain fields to make them more relevant.
How do I handle errors and exceptions with Sunspot?
Sunspot raises specific exceptions for different types of errors, such as connection errors or indexing errors. You can catch these exceptions in your code and handle them appropriately. Sunspot also provides a retry mechanism for transient errors.
Can I use Sunspot with other Ruby frameworks or libraries?
Yes, while Sunspot provides specific features for Rails, it can be used with any Ruby framework or library. You just need to configure Sunspot to use the correct Solr server and define your indexing rules.
How do I debug issues with Sunspot?
Sunspot provides several debugging tools. You can log the raw Solr requests and responses, or inspect the Sunspot::Search object to see the generated Solr query. You can also use the Sunspot.session method to access the current Sunspot session and inspect its state.
How can I contribute to the Sunspot project?
Sunspot is an open-source project, and contributions are welcome. You can contribute by reporting bugs, suggesting new features, improving the documentation, or submitting pull requests with code changes.

