The Standard Library
The C++ standard library consists of many components. This chapter serves two purposes. It should give you a quick overview of the features and a first idea of how to use them.
The History
C++ and, therefore, the standard library have a long history. C++ started in the 1980s of the last millennium and ended now in 2020. Anyone who knows about software development knows how fast our domain evolves. So 30 years is a very long period. You may not be so astonished that the first components of C++, like I/O streams, were designed with a different mindset than the modern Standard Template Library (STL). This evolution in the area of software development in the last 30 years, which you can observe in the C++ standard library, is also an evolution in the way software problems are solved. C++ started as an object-oriented language, then incorporated generic programming with the STL, and now has adopted many functional programming ideas.
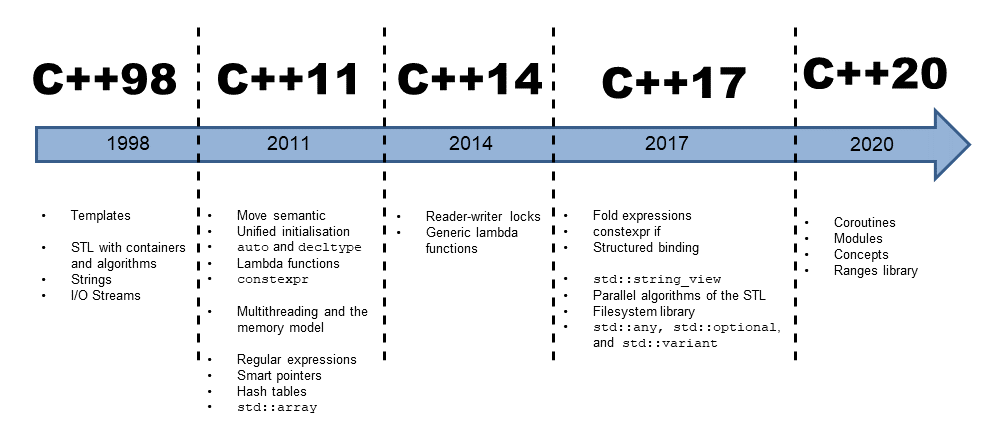
C++ timeline
The first C++ standard library from 1998 had three components. Those were the previously mentioned I/O streams, mainly for file handling, the string library, and the Standard Template Library. The Standard Template Library facilitates the transparent application of algorithms on containers.
The history continues in the year 2005 with Technical Report 1 (TR1). The extension to the C++ library ISO/IEC TR 19768 was not an official standard, but almost all of the components became part of C++11. These were, for example, the libraries for regular expressions, smart pointers, hash tables, random numbers, and time, based on the boost libraries (http://www.boost.org/).
In addition to the standardization of TR1, C++11 got one new component: the multithreading library.
C++14 was only a minor update to the C++11 standard. Therefore C++14 added only a few improvements to the already existing libraries for smart pointers, tuples, type traits, and multithreading.
C++17 includes libraries for the file system and the two new data types std::any and std::optional.
C++20 has four outstanding features: concepts, ranges, coroutines, modules
Overview
As C++11 has many libraries, it is often not so easy to find the convenient one for each use case.
Utilities
Utilities are libraries with a general focus and therefore can be applied in many contexts.
Examples of utilities are functions to calculate the minimum or maximum of values or functions, the midpoint of two values, or to swap or move values.
Thanks to save comparison of integers, integral promotion does not kick in.
Other utilities are std::function, std::bind, or std:bind_front With std::bind or std::bind_front you can easily create new functions from existing ones. To bind them to a variable and invoke them later, you have std::function.
With std::pair and it’s generalisation std::tuple you can create heterogeneous pairs and tuples of arbitrary length.
The reference wrappers std::ref and std::cref are pretty handy. One can use them to create a reference wrapper for a variable, which for std::cref is const.
Of course, the highlights of the utilities are the smart pointers. They allow explicit automatic memory management in C++. You can model the concept of explicit ownership with std::unique_ptr and model shared ownership with std::shared_ptr. std::shared_ptr uses reference counting for taking care of its resource. The third one, std::weak_ptr, helps to break the cyclic dependencies among std::shared_ptr s, the classic problem of reference counting.
The type traits library is used to check, compare and manipulate type information at compile time.
The time library is an import addition of the new multithreading capabilities of C++. But it is also quite handy to make performance measurements and includes support for calender and time zone.
With std::any, std::optional, and std::variant, we get with C++17 three special datatypes that can have any, an optional value, or a variant of values.
The Standard Template Library
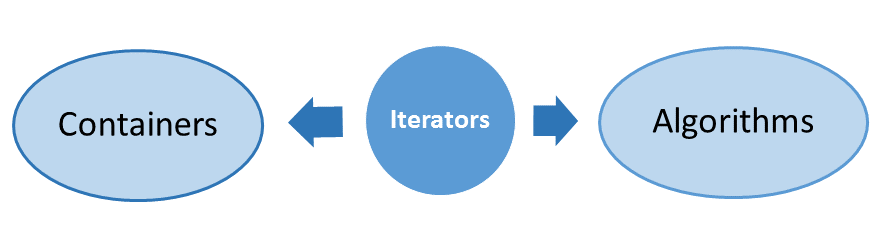
The three components of the STL
The Standard Template Library (STL) consists of three components from a bird’s-eye view. Those are containers, algorithms that run on the containers, and iterators that connect both of them. This abstraction of generic programming enables you to combine algorithms and containers uniquely. The containers have only minimal requirements for their elements.
The C++ Standard Library has a rich collection of containers. From a bird’s eye we have sequence and associative containers. Associative containers can be classified as ordered or unordered associative containers.
Each of the sequence containers has a unique domain. Still, in 95 % of the use cases, std::vector is the right choice. std::vector can dynamically adjust its size, automatically manages its memory, and provides you with outstanding performance. In contrast, std::array is the only sequence container that cannot adjust its size at runtime. It is optimized for minimal memory and performance overhead. While std::vector is good at putting new elements at its end, you should use std::deque to put an element also at the beginning. With std::list being a doubly-linked list and std::forward_list as a singly linked list, we have two additional containers optimized for operations at arbitrary positions in the container, with high performance.
Associative containers are containers of key-value pairs. They provide their values by their respective key. A typical use case for an associative container is a phone book, where you use the key family name to retrieve the value phone number. C++ has eight different associative containers. On one side there are the associative containers with ordered keys: std::set, std::map, std::multiset and std::multimap. On the other side there are the unordered associative containers: std::unordered_set, std::unordered_map, std::unordered_multiset and std::unordered_multimap.
Let’s look first at the ordered associative containers. The difference between std::set and std::map is that the former has no associated value. The difference between std::map and std::multimap is that the latter can have more than one identical key. These naming conventions also hold for the unordered associative containers, which have a lot in common with the ordered ones. The key difference is the performance. While the ordered associative containers have a logarithmic access time, the unordered associative containers allow constant access time. Therefore the access time of the unordered associative containers is independent of their size. The same rule holds true for std::map as it does for std::vector. In 95 % of all use cases, std::map should be your first choice for an associative container because the keys are sorted.
Container adapters provide a simplified interface to the sequence containers. C++ has std::stack, std::queue and std::priority_queue.
std::span is a view on a contiguous sequence of elements. C-array, std::array, std::vector, or std::string support views. A view is never an owner.
Iterators are the glue between the containers and the algorithms. The container creates them. As generalized pointers, you can use them to iterate forward and backward or jump to an arbitrary position in the container. The type of iterator you get depends on the container. If you use an iterator adapter, you can directly access a stream.
The STL gives you more than 100 algorithms. By specifying the execution policy, you can run most of the algorithms sequential, parallel, or parallel and vectorised. Algorithms operate on elements or a range of elements. Two iterators define a range. The first one defines the beginning, the second one, called end iterator, defines the end of the range. It’s important to know that the end iterator points to one element past the end of the range.
The algorithms can be used in a wide range of applications. You can find elements or count them, find ranges, compare or transform them. There are algorithms to generate, replace or remove elements from a container. Of course, you can sort, permute or partition a container or determine the minimum or maximum element of it. Many algorithms can be further customized by callables like functions, function objects, or lambda-functions. The callables provide special criteria for search or elements transformation. They highly increase the power of the algorithm.
The algorithms of the ranges library are lazy, can work directly on the container and can easily be composed. They extend C++ with functional ideas.
Numeric
There are two libraries for numerics in C++: the random numbers library and the mathematical functions, which C++ inherited from C.
The random numbers library consists of two parts. On one side, there is the random number generator; on the other side, the generated random numbers distribution. The random number generator generates a stream of numbers between a minimum and a maximum value, which the random number distribution maps onto the concrete distribution.
Because of C, C++ has a lot of mathematical standard functions. For example there are logarithmic, exponential and trigonometric functions.
C++ supports basic and advanced mathematical constants such as ![]() ,
, ![]() , or
, or ![]() .
.
Text Processing
With strings and regular expressions, C++ has two powerful libraries to process text.
std::string possesses a rich collection of methods to analyze and modify its text. Because it has a lot in common with a std::vector of characters, the algorithms of the STL can be used for std::string. std::string is the successor of the C string but a lot easier and safer to use. C++ strings manage their own memory.
In contrast to a std::string a std::string_view is quite cheap to copy. A std::string_view is a non-owning reference to a std::string.
Regular expression is a language for describing text patterns. You can use regular expressions to determine whether a text pattern is present once or more times in a text. But that’s not all. Regular expressions can be used to replace the content of the matched patterns with a text.
Input and Output
I/O streams library is a library, present from the start of C++, that allows communication with the outside world.
Communication means in this concrete case that the extraction operator (>>) enables it to read formatted or unformatted data from the input stream, and the insertion operator (<<) enables it to write the data on the output stream. Data can be formatted using manipulators.
The stream classes have an elaborate class hierarchy. Two stream classes are significant: First, string streams allow you to interact with strings and streams. Second, file streams allow you to read and write files easily. The state of streams is kept in flags, which you can read and manipulate.
By overloading the input operator and output operator, your class can interact with the outside world like a fundamental data type.
The formatting library provides a safe and extensible alternative to the printf family and extends the I/O streams library.
In contrast to the I/O streams library, filesystem library was added to the C++-Standard with C++17. The library is based on the three concepts file, file name and path. Files can be directories, hard links, symbolic links or regular files. Paths can be absolute or relative.
The filesystem library supports a powerful interface for reading and manipulating the filesystem.
Multithreading
C++ gets with the 2011 published C++ standard a multithreading library. This library has basic building blocks like atomic variables, threads, locks, and condition variables. That’s the base on which future C++ standards can build higher abstractions. But C++11 already knows tasks, which provide a higher abstraction than the cited basic building blocks.
At a low level, C++11 provides for the first time a memory model and atomic variables. Both components are the foundation for well-defined behavior in multithreading programming.
A new thread in C++ will immediately start its work. It can run in the foreground or background and gets its data by copy or reference. Thanks to the stop token, you can interrupt the improved thread std::jthread.
The access of shared variables between threads has to be coordinated. This coordination can be done in different ways with mutexes or locks. But often, it’s sufficient to protect the initialization of the data as it will be immutable during its lifetime.
Declaring a variable as thread-local ensures that a thread get its own copy, so there is no conflict.
Condition variables are a classic solution to implement sender-receiver workflows. The key idea is that the sender notifies the receiver when it’s done with its work, so the receiver can start.
Semaphores are a synchronization mechanism used to control concurrent access to a shared resource. A semaphore has a counter that is bigger than zero. Acquiring the semaphore decreases the counter, and releasing the semaphore increases the counter. A thread can only acquire the resource when the counter is greater than zero.
Similar to semaphores, std::latch and std::barrier are coordination types which enable some threads to block until a counter becomes zero. In constrast to a std::barrier, you can resue a std::latch for a new iteration and adjust its counter for this new iteration.
Tasks have a lot in common with threads. But while a programmer explicitly creates a thread, a task will be implicitly created by the C++ runtime. Tasks are like data channels. The promise puts data into the data channel, the future picks the value up. The data can be a value, an exception, or simply a notification.
Coroutines are functions that can suspend and resume their execution while keeping their state. Coroutines are the usual way to write event-driven applications. The event-driven application can be simulations, games, servers, user interfaces, or even algorithms. Coroutines are typically used for cooperative multitasking. The key to cooperative multitasking is that each task takes as much time as it needs.
Application of Libraries
To use a library in a file, you have to perform three steps. At first, you have to include the header files with the #include statement so the compiler knows the library’s names. Because the C++ standard library names are in the namespace std, you can use them in the second step fully qualified, or you have to import them in the global namespace. The third and final step is to specify the libraries for the linker to get an executable. This third step is often not necessary. The three steps are explained below.
Include Header Files
The preprocessor includes the file, following the #include statement. That is, most of the time, a header file. The header files will be enclosed in angle brackets:
#include <iostream>#include <vector>Specify all necessary header files
The compiler is free to add additional headers to the header files. So your program may have all the necessary headers, although you didn’t specify all of them. It’s not recommended to rely on this feature. All needed headers should always be explicitly specified, otherwise a compiler upgrade or code porting may provoke a compilation error.
Usage of Namespaces
If you use qualified names, you have to use them exactly as defined. For each namespace you must put the scope resolution operator ::. More libraries of the C++ standard library use nested namespaces.
#include <iostream>#include <chrono>...std::cout << "Hello world:" << std::endl;auto timeNow= std::chrono::system_clock::now();Unqualified Use of Names
You can use names in C++ with the using declaration and the using directive.
Using Declaration
A using declaration adds a name to the visibility scope, in which you applied the using declaration:
#include <iostream>#include <chrono>...using std::cout;using std::endl;using std::chrono::system_clock;...cout << "Hello world:" << endl; // unqualified nameauto timeNow= now(); // unqualified nameThe application of a using declaration has the following consequences:
- An ambiguous lookup and, therefore, a compiler error occurs if the same name was declared in the same visibility scope.
- If the same name was declared in a surrounding visibility scope, it will be hidden by the
usingdeclaration.
Using Directive
The using directive permits it to use all names of a namespace without qualification.
#include <iostream>#include <chrono>...using namespace std;...cout << "Hello world:" << endl; // unqualified nameauto timeNow= chrono::system_clock::now(); // partially qualified nameA using directive adds no name to the current visibility scope, it only makes the name accessible. That implies:
- An ambiguous lookup and, therefore, a compiler error occur if the same name was declared in the same visibility scope.
- A name in the local namespace hides a name declared in a surrounding namespace.
- An ambiguous lookup and, therefore, a compiler error occurs if the same name get visible from different namespaces or if a name in the namespace hides a name in the global scope.
Use using directives with great care in source files
using directives should be used with great care in source files, because by the directive using namespace std all names from std becomes visible. That includes names, which accidentally hide names in the local or surrounding namespace.
Don’t use using directives in header files. If you include a header with using namespace std directive, all names from std become visible.
Namespace Alias
A namespace alias defines a synonym for a namespace. It’s often convenient to use an alias for a long namespace or nested namespaces:
#include <chrono>...namespace sysClock= std::chrono::system_clock;auto nowFirst= sysClock::now();auto nowSecond= std::chrono::system_clock::now();Because of the namespace alias, you can address the now function qualified and with the alias. A namespace alias must not hide a name.
Build an Executable
It is only seldom necessary to link explicitly against a library. That sentence is platform-dependent. For example, with the current g++ or clang++ compiler, you have to link against the pthread library to get the multithreading functionality.
g++ -std=c++14 thread.cpp -o thread -pthread