Introducing Machine Learning with TensorFlow
IN THIS CHAPTER
- Looking at machine learning over time
- Exploring machine learning frameworks
TensorFlow is Google’s powerful framework for developing applications that perform machine learning. Much of this book delves into the gritty details of coding TensorFlow modules, but this chapter provides a gentle introduction. I provide an overview of the subject and then discuss the developments that led to the creation of TensorFlow and similar machine learning frameworks.
Understanding Machine Learning
Like most normal, well-adjusted people, I consider The Terminator to be one of the finest films ever made. I first saw it at a birthday party when I was 13, and though most of the story went over my head, one scene affected me deeply: The heroine calls her mother and thinks she’s having a warm conversation, but she’s really talking to an evil robot from the future!
The robot wasn’t programmed in advance with the mother’s voice or the right sequence of phrases. It had to figure these things out on its own. That is, it had to analyze the voice of the real mother, examine the rules of English grammar, and generate acceptable sentences for the conversation. When a computer obtains information from data without receiving precise instructions, it’s performing machine learning.
The Terminator served as my first exposure to machine learning, but it wouldn’t be my last. As I write this book, machine learning is everywhere. My email provider knows that messages involving an “online pharmacy” are spam, but messages about “cheap mescaline” are important. Google Maps always provides the best route to my local Elvis cult, and Amazon.com always knows when I need a new horse head mask. Is it magic? No, it’s machine learning!
Machine learning applications achieve this power by discovering patterns in vast amounts of data. Unlike regular programs, machine learning applications deal with uncertainties and probabilities. It should come as no surprise that the process of coding a machine learning application is completely different than that of coding a regular application. Developers need to be familiar with an entirely new set of concepts and data structures.
Thankfully, many frameworks have been developed to simplify development. At the time of this writing, the most popular is TensorFlow, an open-source toolset released by Google. In writing this book, my goal is to show you how to harness TensorFlow to develop your own machine learning applications.
Although this book doesn’t cover the topic of ethics, I feel compelled to remind readers that programming evil robots is wrong. Yes, you’ll impress your professor, and it will look great on a resume. But society frowns on such behavior, and your friends will shun you. Still, if you absolutely have to program an evil robot, TensorFlow is the framework to use.
The Development of Machine Learning
In my opinion, machine learning is the most exciting topic in modern software development, and TensorFlow is the best framework to use. To convince you of TensorFlow’s greatness, I’d like to present some of the developments that led to its creation. Figure 1-1 presents an abbreviated timeline of machine learning and related software development.
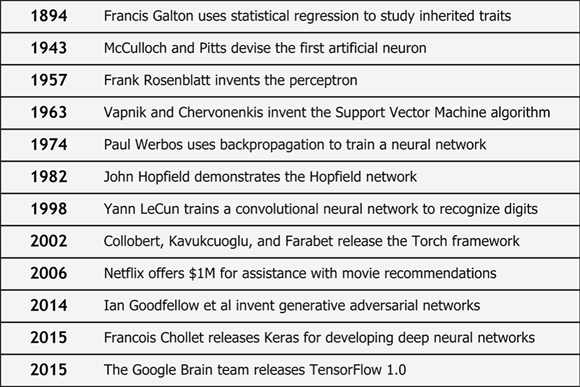
FIGURE 1-1: Developments in machine learning extend from academia to corporations.
Once you understand why researchers and corporations have spent so much time developing the technology, you’ll better appreciate why studying TensorFlow is worth your own time.
Statistical regression
Just as petroleum companies drill into the ground to obtain oil, machine learning applications analyze data to obtain information and insight. The formal term for this process is statistical inference, and its first historical record comes from ancient Greece. But for this purpose, the story begins with a nineteenth-century scientist named Francis Galton. Though his primary interest was anthropology, he devised many of the concepts and tools used by modern statisticians and machine learning applications.
Galton was obsessed with inherited traits, and while studying dogs, he noticed that the offspring of exceptional dogs tend to acquire average characteristics over time. He referred to this as the regression to mediocrity. Galton observed this phenomenon in humans and sweet peas, and while analyzing his data, he employed modern statistical concepts like the normal curve, correlation, variance, and standard deviation.
To illustrate the relationship between a child’s height and the average height of the parents, Galton developed a method for determining which line best fits a series of data points. Figure 1-2 shows what this looks like. (Galton’s data is provided by the University of Alabama.)
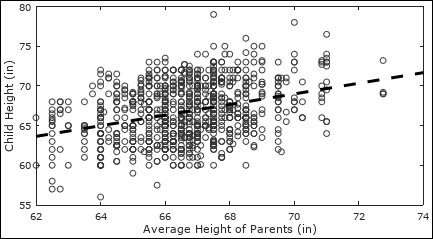
FIGURE 1-2: Linear regression identifies a clear trend amidst unclear data points.
Galton’s technique for fitting lines to data became known as linear regression, and the term regression has come to be used for a variety of statistical methods. Regression plays a critical role in machine learning, and Chapter 6 discusses the topic in detail.
Reverse engineering the brain
In 1905, Ramón y Cajal examined tissue from a chicken’s brain and studied the interconnections between the cells, later called neurons. Cajal’s findings fascinated scientists throughout the world, and in 1943, Warren McCulloch and Walter Pitts devised a mathematical model for the neuron. They demonstrated that their artificial neurons could implement the common Boolean AND and OR operations.
While researching statistics, a psychologist named Frank Rosenblatt developed another model for a neuron that expanded on the work of McCulloch and Pitts. He called his model the perceptron, and by connecting perceptrons into layers, he created a circuit capable of recognizing images. These interconnections of perceptrons became known as neural networks.
Rosenblatt followed his demonstrations with grand predictions about the future of perceptron computing. His predictions deeply influenced the Office of Naval Research, which funded the development of a custom computer based on perceptrons. This computer was called the Mark 1 Perceptron, and Figure 1-3 shows what it looks like.

Credit: Cornell Aeronautical Laboratory.
FIGURE 1-3: The Mark 1 Perceptron was the first computer created for machine learning.
The future of perceptron-based computing seemed bright, but in 1969, calamity struck. Marvin Minsky and Seymour Papert presented a deeply critical view of Rosenblatt’s technology in their book, Perceptrons (MIT Press). They mathematically proved many limitations of two-layer feed-forward neural networks, such as the inability to learn nonlinear functions or implement the Boolean Exclusive OR (XOR) operation.
Neural networks have progressed dramatically since the 1960s, and in hindsight, modern readers can see how narrow-minded Minsky and Papert were in their research. But at the time, their findings caused many, including the Navy and other large organizations, to lose interest in neural networks.
Steady progress
Despite the loss of popular acclaim, researchers and academics continued to investigate machine learning. Their work led to many crucial developments, including the following:
- In 1965, Ivakhnenko and Lapa demonstrated multilayer perceptrons with nonlinear activation functions.
- In 1974, Paul Werbos used backpropagation to train a neural network.
- In 1980, Kunihiko Fukushima proposed the neocognitron, a multilayer neural network for image recognition.
- In 1982, John Hopfield developed a type of recurrent neural network known as the Hopfield network.
- In 1986, Sejnowski and Rosenberg developed NETtalk, a neural network that learned how to pronounce words.
These developments expanded the breadth and capabilities of machine learning, but none of them excited the world’s imagination. The problem was that computers lacked the speed and memory needed to perform real-world machine learning in a reasonable amount of time. That was about to change.
The computing revolution
As the 1980s progressed into the 1990s, improved semiconductor designs led to dramatic leaps in computing power. Researchers harnessed this new power to execute machine learning routines. Finally, machine learning could tackle real-world problems instead of simple proofs of concept.
As the Cold War intensified, military experts grew interested in recognizing targets automatically. Inspired by Fukushima’s neocognitron, researchers focused on neural networks specially designed for image recognition, called convolutional neural networks (CNNs). One major step forward took place in 1994, when Yann LeCun successfully demonstrated handwriting recognition with his CNN-based LeNet5 architecture.
But there was a problem. Researchers used similar theories in their applications, but they wrote all their code from scratch. This meant researchers couldn’t reproduce the results of their peers, and they couldn’t re-use one another’s code. If a researcher’s funding ran out, it was likely that the entire codebase would vanish.
In the late 1990s, my job involved programming convolutional neural networks to recognize faces. I loved the theory behind neural networks, but I found them deeply frustrating in practice. Machine learning applications require careful tuning and tweaking to get acceptable results. But each change to the code required a new training run, and training a CNN could take days. Even then, I still didn’t have enough training data to ensure accurate recognition.
One problem facing me and other researchers was that, while machine learning theory was mature, the process of software development was still in its infancy. Programmers needed frameworks and standard libraries so that they weren’t coding everything by themselves. Also, despite Intel’s best efforts, practical machine learning still required faster processors that could access larger amounts of data.
The rise of big data and deep learning
As the 21st century dawned, the Internet’s popularity skyrocketed, and the price of data storage plummeted. Large corporations could now access terabytes of data about potential consumers. These corporations developed improved tools for analyzing their data, and this revolution in data storage and analysis has become known as the big data revolution.
Now CEOs were faced with a difficult question: How could they use their wealth of data to create wealth for their corporations? One major priority was advertising — companies make more money if they know which advertisements to show to their customers. But there were no clear rules for associating customers with products.
Many corporations launched in-house research initiatives to determine how best to analyze their data. But in 2006, Netflix tried something different. They released a large part of their database online and offered one million dollars to whoever developed the best recommendation engine. The winner, BellKor’s Pragmatic Chaos, combined a number of machine learning algorithms to improve Netflix’s algorithm by 10 percent.
Netflix wasn’t the only high-profile corporation using machine learning. Google’s AdSense used machine learning to determine which advertisements to display on its search engine. Google and Tesla demonstrated self-driving cars that used machine learning to follow roads and join traffic.
Across the world, large organizations sat up and paid notice. Machine learning had left the realm of wooly-headed science fiction and had become a practical business tool. Entrepreneurs continue to wonder what other benefits can be gained by applying machine learning to big data.
Researchers paid notice as well. A major priority involved distinguishing modern machine learning, with its high complexity and vast data processing, from earlier machine learning, which was simple and rarely effective. They agreed on the term deep learning for this new machine learning paradigm. Chapter 7 goes into greater detail regarding the technical meaning of deep learning.
Machine Learning Frameworks
One of the most important advances in practical machine learning involved the creation of frameworks. Frameworks automate many aspects of developing machine learning applications, and they allow developers to re-use code and take advantage of best practices. This discussion introduces five of the most popular frameworks: Torch, Theano, Caffe, Keras, and TensorFlow.
Torch
Torch is the first machine learning framework to attract a significant following. Originally released in 2002 by Ronan Collobert, it began as a toolset for numeric computing. Torch’s computations involve multidimensional arrays called tensors, which can be processed with regular vector/matrix operations. Over time, Torch acquired routines for building, training, and evaluating neural networks.
Torch garnered a great deal of interest from academics and corporations like IBM and Facebook. But its adoption has been limited by its reliance on Lua as its interface language. The other frameworks in this discussion —Theano, Caffe, Keras, and TensorFlow — can be interfaced through Python, which has emerged as the language of choice in the machine learning domain.
Theano
In 2010, a machine learning group at the University of Montreal released Theano, a library for numeric computation. Like NumPy, Theano provides a wide range of Python routines for operating on multidimensional arrays. Unlike NumPy, Theano stores operations in a data structure called a graph, which it compiles into high-performance code. Theano also supports symbolic differentiation, which makes it possible to find derivatives of functions automatically.
Because of its high performance and symbolic differentiation, many machine learning developers have adopted Theano as their numeric computation toolset of choice. Developers particularly appreciate Theano’s ability to execute graphs on graphics processing units (GPUs) as well as central processing units (CPUs).
Caffe
As part of his PhD dissertation at UC Berkeley, Yangqing Jia created Caffe, a framework for developing image recognition applications. As others joined in the development, Caffe expanded to support other machine learning algorithms and many different types of neural networks.
Caffe is written in C++, and like Theano, it supports GPU acceleration. This emphasis on performance has endeared Caffe to many academic and corporate developers. Facebook has become particularly interested in Caffe, and in 2007 it released a reworked version called Caffe2. This version improves Caffe’s performance and makes executing applications on smartphones possible.
Keras
While other offerings focus on performance and breadth of capabilities, Keras is concerned with modularity and simplicity of development. François Chollet created Keras as an interface to other machine learning frameworks, and many developers access Theano through Keras to combine Keras’s simplicity with Theano’s performance.
Keras’s simplicity stems from its small API and intuitive set of functions. These functions focus on accomplishing standard tasks in machine learning, which makes Keras ideal for newcomers to the field but of limited value for those who want to customize their operations.
François Chollet released Keras under the MIT License, and Google has incorporated his interface into TensorFlow. For this reason, many TensorFlow developers prefer to code their neural networks using Keras.
TensorFlow
As the title implies, this book centers on TensorFlow, Google’s gift to the world of machine learning. The Google Brain team released TensorFlow 1.0 in 2015, and as of the time of this writing, the current version is 1.4. It’s provided under the Apache 2.0 open source license, which means you’re free to use it, modify it, and distribute your modifications.
TensorFlow’s primary interface is Python, but like Caffe, its core functionality is written in C++ for improved performance. Like Theano, TensorFlow stores operations in a graph that can be deployed to a GPU, a remote system, or a network of remote systems. In addition, TensorFlow provides a utility called TensorBoard, which makes visualizing graphs and their operations possible.
Like other frameworks, TensorFlow supports execution on CPUs and GPUs. In addition, TensorFlow applications can be executed on the Google Cloud Platform (GCP). The GCP provides world-class processing power at relatively low cost, and in my opinion, GCP processing is TensorFlow’s most important advantage. Chapter 13 discusses this important topic in detail.