Tools for High Performance on the Web
JavaScript has become the mainstay language of the web. There is no extra runtime needed, and there is no compilation process required to run an application in JavaScript. Any user can open up a web browser and start typing in the console to learn the language. In addition to this, there have been many advancements in the language along with the Document Object Model (DOM). All of this has led to a rich environment for developers to take and create.
On top of this, we can see the web as a build once, deploy anywhere environment. The code that works on one operating system will work on another. There is some variation that will need to happen if we want to target all browsers, but it can be seen as a develop once, deploy anywhere platform. However, all of this has led to applications that have become bloated, with expensive frameworks and unnecessary polyfills. The necessity for these frameworks can be seen in most job postings, but sometimes we don't need them to create rich applications.
This chapter focuses on the tools that we will use to help us build and profile high-performance web applications. We will take a look at the different modern browsers and their unique contributions. We will then take a deep dive into the Chrome developer tools. Overall, we will learn the following:
- The different development tools embedded in each browser
- An in depth look at the following Chrome tools:
- The Performance tab
- The Memory tab
- The Renderer tab
- jsPerf and benchmarking code
Technical requirements
The following are prerequisites for this chapter:
- A web browser, preferably Chrome.
- An editor; VS Code is preferred.
- Knowledge of JavaScript and some of the DOM APIs.
- The relevant code can be found at https://github.com/PacktPublishing/Hands-On-High-Performance-Web-Development-with-JavaScript/tree/master/Chapter01.
DevTools for different environments
There are four browsers that are considered modern browsers. These are Edge, Chrome, Firefox, and Safari. These browsers uphold the latest in standards and are being actively developed. We will take a look at how each is developing and some of their unique features.
Note
Internet Explorer is getting close to the end of its life cycle. The only development that will be happening with the browser is critical security fixes. New applications should try to deprecate this browser, but if there is a client base still utilizing it, then we may need to develop for it. We will not be focusing on polyfills for it in this book.
Edge
Microsoft's Edge browser was their take on the modern web. With the EdgeHTML renderer and the Chakra JavaScript engine, it performs well in many benchmarks. While the Chakra engine does have different optimizations for it than Chrome or Firefox, it is an interesting browser to look at from a pure JavaScript perspective.
Note
As of the time of writing of this book, Microsoft was changing the rendering engine of Edge to the Chromium system. This has many implications for web developers. First, this means that more browsers will be running the Chromium system. This means less to worry about in terms of cross-browser development. While support for the current form of Edge is required, it may disappear in the coming year.
In terms of features, Edge is light compared to the other browsers. If we need to perform any type of performance testing for it, the best bet is to profile code with jsPerf or others instead of the built-in tools. On top of this, the Chakra engine utilizes different optimization techniques, so what may work with Chrome or Safari may be less optimized for Edge. To get to the developer tools on Windows, we can press F12. This will pull up the usual console dialog, shown as follows:

We will not be going through any interesting features specific to Edge since most, if not all, of the features in their developer tools are the same as those found in other browsers.
Note
With the latest Edge browser based on Chromium, OS X users will be happy to note that the browser is supposed to be supported. This means cross-browser development will get easier for those on OS X versus Windows or Linux.
Safari
Apple's Safari browser is based on the WebKit rendering engine and the JavaScriptCore engine. The WebKit engine is what Chrome's Blink engine is based on, and the JavaScriptCore engine is used in a few places for the OS X operating system. An interesting point regarding Safari is the fact that if we are running Windows or Linux, we will not be able to access it directly.
To get access to Safari, we will need to utilize an online service. BrowserStack or LambdaTest, along with a host of others, can do this job for us. With any of these, we now have access to browsers that we may not otherwise have had. Thanks to LambdaTest, we will utilize their free service to take a brief look at Safari.
Again, we will notice that there is not too much to the Safari browser development tools. All of the same tools are also available in the other browsers and they are usually more powerful in these other browsers. Getting familiar with each of the interfaces can help when debugging in that specific browser, but not a lot of time needs to be dedicated to looking at the browsers that do not have any specific features unique to them.
Firefox
Mozilla's Firefox utilizes the SpiderMonkey JavaScript engine and the enhanced Gecko engine. The Gecko engine got some nice improvements when they added parts of their project Servo code base to it to give a nice multithreaded renderer. Mozilla has been at the forefront of the latest web technologies. They were one of the first to implement WebGL and they have been one of the first to implement WebAssembly and the WebAssembly System Interface (WASI) standard.
Note
What follows is a fairly technical discussion about shaders and the shader language, OpenGL Shading Language (GLSL). It is recommended that you read on to find out more about this, but for those of you who are lost, it may be helpful to visit the documentation to learn more about this technology, at https://developer.mozilla.org/en-US/docs/Games/Techniques/3D_on_the_web/GLSL_Shaders.
If we open the DevTools, F12 in Windows, we may see the Shader Editor tab already. If not, go to the triple-dot menu on the right and open up Settings. On the left-hand side, there should be a list of checkboxes with a heading of Default Developer Tools. Go ahead and select the Shader Editor option. Now, if we head into this tab, we should get something that looks like the following:

The tab is asking for a canvas context. Essentially, the tool is looking for a few items:
- A canvas element
- A 3D-enabled context
- Vertex and fragment shaders
A file in our repository called shader_editor.html has the necessary code to get the canvas set up and also has the shaders set up so we can utilize them with the shader editor. These shaders are the way to programmatically use the GPU on the web. They utilize a version of the OpenGL specification called OpenGL ES 3.0. This allows us to use almost everything in that specification, specifically, the vertex and fragment shaders.
To program with these shaders, we use a language called GL Shading Language (GLSL). This is a C-like language that has a bunch of features that are specific to it, such as swizzling. Swizzling is the ability to utilize the vector components (up to four) and combine them in any shape or form that we choose. An example of this looks like the following:
vec2 item = vec2(1.0, 1.0);vec4 other_item = item.xyxx;This creates a four-element vector and sets the x, y, z, and w components to the x, y, x, and x items, respectively, from the two-element vector. The nomenclature can take a while to get used to, but it makes certain things a lot easier. An example is shown above, where we need to create a four-element vector from a two-element vector. In basic JavaScript, we would have to do the following:
const item = [1.0, 1.0];const other_item = [item[0], item[1], item[0], item[0]];Instead of writing the preceding, we are able to utilize the shorthand syntax of swizzling. There are other features in the GLSL system that we will look at in later chapters, but this should give a taste of how different the languages are.
Now, if we open up the shader_editor.html file and reload the page, we should be greeted with what looks like a white page. If we look at the Shader Editor, we can see on the right-hand side that we are setting a variable called gl_FragColor to a four-element vector, all of which are set to 1.0. What happens if we set it to vec4(0.0, 0.0, 0.0, 1.0)? We should now see a black box in the top-left corner. This showcases the fact that the four components of the vector are the red, green, blue, and alpha components of color, ranging from 0.0 to 1.0, just like the rgba system for CSS.
Are there other color combinations besides a single flat color? Well, each shader comes with a few global variables that are defined ahead of time. One of these, in the fragment shader, is called gl_FragCoord. This is the lower left-hand coordinate in the window space ranging from 0.0 to 1.0 (there should be a theme developing here for what values are considered good in GLSL). If we set the four-vector x element to the x element of gl_FragCoord, and the y element to the y element of gl_FragCoord, we should get a simple white box, but with a single-pixel border on the left, and one on the bottom.
Besides swizzling and global variables, we also get other mathematical functions that we can use in these shaders. Let's wrap these x and y elements in a sin function. If we do this, we should get a nice plaid pattern on the screen. This should give a hint as to what the fragment shader is actually doing. It is trying to paint that location in the 3D space, based on various inputs, one being the location from the vertex shader.
It is then trying to draw every single pixel that makes up the inside of the mesh that we declared with the vertex shader. Also, these fragments are calculated all at the same time (or as much as the graphics card is capable of), so this is a highly parallelized operation.
This should give a nice sneak peek into the world of GLSL programming, and the possibilities besides 3D work that the GLSL language can provide for us. For now, we can play a bit more with these concepts and move onto the last browser, Chrome.
Chrome
Google's Chrome browser utilizes the Blink engine and uses the famous V8 JavaScript runtime. This is the same runtime that is used inside Node.js, so getting familiar with the development tools will help us in a lot of ways.
Chrome has been at the forefront of web technologies, just like Firefox. They have been the first to implement various ideas, such as the QUIC protocol, which the HTTP/3 standard is loosely based on. They created the Native Plugin Interface (NaCL) that helped, alongside asm.js, to create the standard for WebAssembly. They have even been pioneers in making web applications start to become more native-like by giving us APIs such as the Bluetooth, Gamepad, and Notifications APIs.
We will be specifically looking at the Lighthouse feature that comes with Chrome. The Lighthouse feature can be accessed from the Audits tab in the Chrome browser. Once we are here, we can set up our audit with a myriad of settings:
- First, we can audit our page based on it running from a mobile device or desktop. We can then audit various features of our site.
- If we are developing a progressive web application, we may decide that SEO is not needed. On the other hand, if we are developing a marketing site, we could decide that the progressive web app check is not needed. We can simulate a throttled connection.
- Finally, we can start off with clean storage. This is especially helpful if our application utilizes caching systems that are built into browsers, such as session storage or local storage.
As an example, let's look at an external site and see how well it stacks up in the audit application. The site we will be looking at is Amazon, located at https://www.amazon.com. The site should be a good example for us to follow. We are going to look at it as a desktop application, without any throttling. If we run the audit, we should get something that looks like the following:

As we can see, the main page does well in performance and best practices, but Chrome is warning us about accessibility and SEO performance. In terms of accessibility, it seems that images do not have alt attributes, which means screen readers are not going to work well. Also, it seems that the developers have tabindexes higher than 0, possibly causing the tab order to not follow the normal page flow.
If we wanted to set up our own system to test, we would need to host our pages locally. There are many great static site hosting solutions (we will be building one later in the book), but if we needed to host content, one of the easiest methods would be to download Node.js and install the static-server module. We will go into depth later on how to get Node.js up and running and how to create our own servers, but for now, this is the best bet.
We have looked at the main modern web browsers that are out there and that we should target. Each of them has its own capabilities and limitations, which means we should be testing our applications on all of them. However, the focus of this book will be the Chrome browser and the developer tools that come with it. Since Node.js is built with the V8 engine, and with many other new browsers being based on the Chromium engine, such as Brave, it would make sense to utilize this. We are going to go into detail regarding three specific features that the Chrome developer tools give us.
Chrome – an in-depth look at the Performance tab
As stated before, except for a select few tools inside Firefox, Chrome has become widely ubiquitous as the browser of choice for users and developers. For developers, this can be in large part thanks to its wonderful developer tools. The following sections are going to take a look at three critical tools that are important to any developer when designing web applications. We will start with the performance tool.
This tool allows us to run performance tests while our application is running. This is great if we want to see how our application behaves when certain things are done. For example, we can profile our application's launch state and see where possible bottlenecks are located. Or, when user interaction happens, such as a submit on a form, we can see the call hierarchy that we go through to post the information and return it back to the user. On top of this, it can even help profile code when we use a web worker and how the data transfer works between our application contexts.
Following is a screenshot of the Performance tab from the latest version of Chrome at the time of writing:
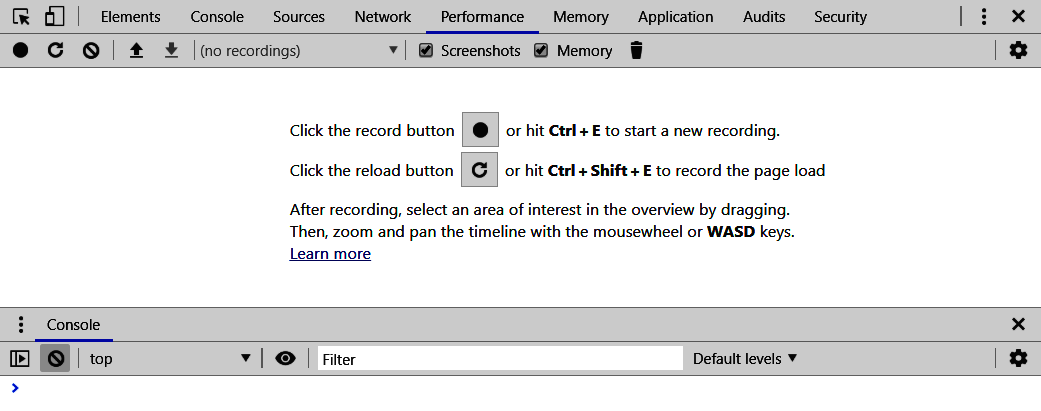
There are a couple of sections that are of interest. First, the bar below our developer tool tabs is our main toolbar. The left two buttons are probably the most important, the record and the record on reload tools. These will allow us to profile our application and see what happens at critical junctures in our code. After these come selection tools to grab profiles that you may have run before.
Next up are two options that I usually have turned on at all times:
- First, the screenshot capability will grab screenshots for us when it sees something critical happening with the application, such as memory growth or a new document being added.
- The next option is the memory profiler. It will tell us how much memory is being consumed at that time.
Finally, there is the delete action. As many would surmise, this deletes the profile that you are currently on.
Let's do a test run on a simple test application. Grab the chrome_performance.html file from the repository. This file showcases a standard Todo application, but it is written with a very basic templating system and no libraries. No libraries will become a standard throughout this book.
If we run this application and run a performance test from reload, we should get something that looks like the following:
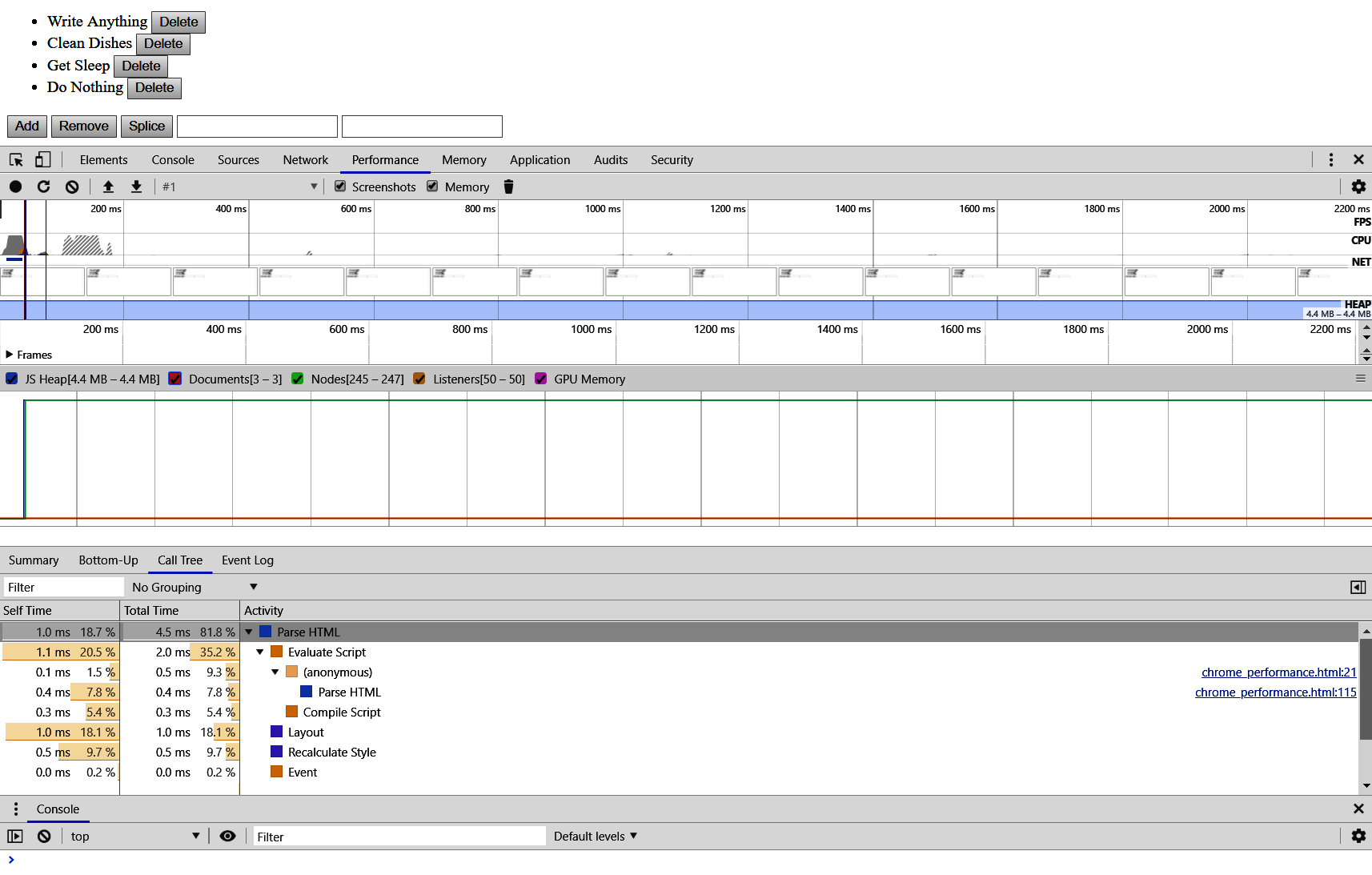
The page should be almost instant to load, but we still get some useful information here. Going from top to bottom, we get the following information:
- A timeline of pictures, along with graphing for FPS, CPU usage, network usage, and heap usage.
- A line graph of different statistics, such as JavaScript heap usage, the number of documents, the number of document nodes, the number of listeners, and the GPU memory that we are utilizing.
- Finally, we get a tabbed section that gives us all of the information about timings and a breakdown of where the time is allocated.
Note
Make sure you let the profiler run its course. It should automatically shut down after all operations are done on the page. This should ensure that you are getting as close to the correct information as possible on how your application is doing. The profiler may have to be run a couple of times to get an accurate picture also. The internal garbage collector is trying to hold onto some objects so that it can reuse them later, so getting an accurate picture means seeing what the low point is since that is most likely where the application baseline is following Garbage Collection (GC). A good indicator of this is seeing a major GC and/or a DOM GC. This means we are starting afresh again.
In this basic example, we can see that most of the time was spent in the HTML. If we open this up, we will then see that evaluating our script took the majority of that time. Since most of our time was spent in evaluating the script and inserting our templated Todo application into the DOM, let's see what the statistics would look like if we did not have this behavior.
Comment out everything except for our basic tags, such as the html, head, and body tags. There are a few interesting elements regarding this run. First, the number of documents should have stayed the same or decreased. This will be touched upon later. Second, the number of nodes decreased dramatically and likely went down to around 12. Our JavaScript heap went down a little bit, and the number of listeners went down significantly.
Let's bring a single div tag back in. The number of documents, heap space, and listeners stayed the same, but the number of nodes increased again. Let's add in another div element and see how that affects the number of nodes. It should increase by four. One last time, let's add in another div element. Again, we should notice an increase of four DOM nodes being added. This gives us a bit of a clue into how the DOM is running and how we can make sure our profiling is correct.
First, the number of nodes is not directly equal to the number of DOM elements that are on the screen. DOM nodes are made up of several underlying basic nodes. As an example, if we add an element such as an input element, we may notice that the number of nodes increases by more than four. Second, the number of documents that are available is almost always going to be higher than a single document.
While some of this behavior can be attributed to bugs in the profiler, it also showcases the fact that there are things happening behind the scenes that are not available to the developer. When we touch on the Memory tab and look at call hierarchies, we will see how internal systems are creating and destroying nodes that a developer does not have full control of, along with documents that are invisible to the developer but are optimizations for the browser.
Let's add in our code block again and get back to what the original document was. If need be, go ahead and revert the Git branch (if this was pulled down from the repository) and run the profiler again. We specifically want to look at the Call Tree tab and the Parse HTML dropdown. There should be a hierarchy that looks something like the following: Parse HTML > Evaluate Script > (anonymous) > runTemplate > runTemplate.
Let's change the code and turn our inner for loop into an array map function like this:
const tempFun = runTemplate.bind(null, loopTemp);loopEls = data.items.map(tempFun);Comment out both the loopEls array initialization and also the for loop. Run the profiler again and let's take a look at what this call stack looks like. We will notice that it is still profiling the runTemplate function as itself even though we bound it to a new function called tempFun. This is another piece that we have to keep in mind when we are looking at the call hierarchy. We may bind, call, or apply functions, but the development tools will still try to maintain the original definition of the function.
Finally, let's add a lot of items to our data list and see how this affects our profiling. Put the following code below the data section:
for(let i = 0; i < 10000; i++) { data.items.push({text : `Another item ${i}`});}We should now get a bit of a different picture than what we had before:
- First, where our time was close to being evenly split between layout by the GPU and the evaluation of our script, it now looks like we are spending most of our time running the layout engine. This makes sense since we are forcing the DOM to figure out the layout for each item when it gets added at the end of our script.
- Second, the Evaluate Script section should now contain quite a few more pieces than the simple call hierarchy that we saw before.
- We will also start to see different parts of the function being registered in the profiler. What this shows is that if something is below a certain threshold (it really depends on the machine and even the build of Chrome), it will not show that the function was considered important enough to be profiled.
Garbage collection is the process of our environment cleaning up unused items that we are no longer using. Since JavaScript is a memory-managed environment, meaning developers are not allocating/deallocating memory themselves like in languages such as C++ and Rust, we have a program that does this for us. V8, in particular, has two GCs, a minor GC called Scavenger, and a major one called Mark-Compact.
The scavenger goes through newly allocated objects and sees whether there are any objects that are ready to be cleaned up. Most of the time, our code is going to be written to use a lot of temporary variables for a short time span. This means that they are not going to be needed within a couple of statements of the variables being initialized. Take the following piece of code:
const markedEls = [];for(let i = 0; i < 10000; i++) { const obj = els[i]; if( obj.marked ) { markedEls.push(Object.assign({}, obj)); }}In this hypothetical example, we want to get objects and clone them if they are marked for some procedure. We gather the ones that we want and the rest are now unused. The scavenger would notice a couple of things. First, it would seem that we are no longer using the old list, so it would automatically collect this memory. Second, it would notice that we have a bunch of unused object pointers (except for primitive types in JavaScript, everything is passed by reference) and it can clean these up.
This is a quick process and it gets either intertwined in our runtime, known as stop-and-go garbage collection, or it will run in parallel to our code, meaning that it will run at the exact same time in another thread of execution.
The Mark-Compact garbage collection runs for much longer but collects a lot more memory. It will go through the list of items that are currently still in the heap and see whether there are zero references to these items. If there are no more references, it will remove these objects from the heap. It will then try to compact all of the holes that are in the heap so that way, we do not have highly fragmented memory. This is especially useful for things such as arrays.
Arrays are contiguous in memory, so if the V8 engine can find a hole big enough for the array, then it will stick it there. Otherwise, it may have to grow the heap and allocate more memory for our runtime. This is what the Mark-Compact GC is trying to prevent from happening.
While a full understanding of how the garbage collector works is not needed in order to write highly performant JavaScript, a good understanding will go a long way into writing code that is not only easy to read but also performs well in the environment that you are using.
Note
If you want to understand more about the V8 garbage collector, I would recommend going to the site at https://v8.dev/blog. It is always interesting to see how the V8 engine is working and how new optimizations lead to certain coding styles being more performant than they may have been in the past, such as the map function for arrays.
We did not go into full detail regarding the Performance tab, but this should give a good overview of how to utilize it when testing code. It should also showcase some of the internal workings of Chrome and the garbage collector.
There will be more discussion in the next section on memory, but it is highly recommended to run some tests against a current code base and notice what the performance is like when running these applications.
Chrome – an in-depth look at the Memory tab
As we move from the performance section to the memory section, we will revisit a good number of concepts from the performance tool. The V8 engine provides a great amount of support for developing applications that are both efficient in terms of CPU usage and also memory usage. A great way to test your memory usage and where it is being allocated is the memory profiling tool.
With the latest version of Chrome at the time of writing, the memory profiler appears as follows:
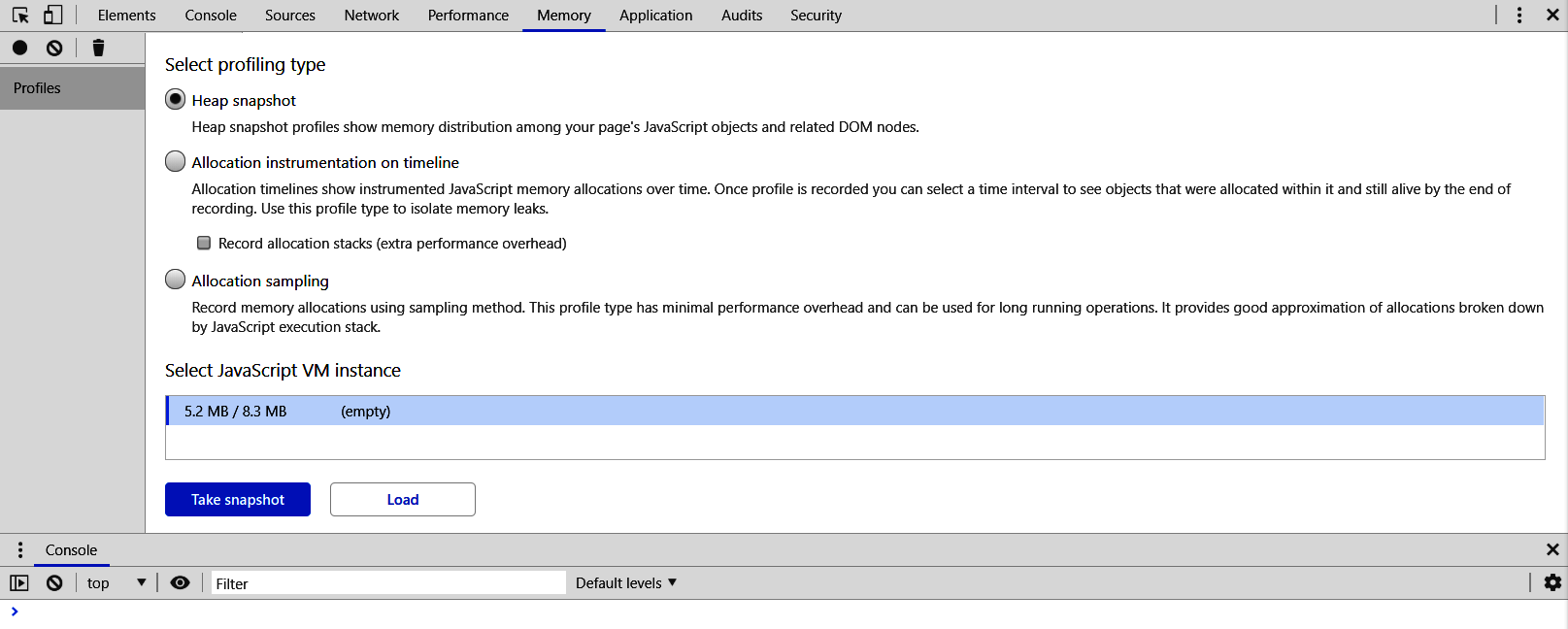
We will mainly be focusing on the first option that is selected, the Heap snapshot tool. The Allocation instrumentation on timeline tool is a great way to visualize and playback how the heap was being allocated and which objects were causing the allocations to occur. Finally, the Allocation sampling tool takes periodic snapshots instead of providing a continuous look, making it much lighter and able to perform memory tests while cumbersome operations are conducted.
The heap snapshot tool will allow us to see where memory is being allocated on the heap. From our previous example, let's run the heap snapshot tool (if you have not commented out the for loop that allocated 10,000 more DOM nodes, comment it out now). After the snapshot has run, you should get a table with a tree view on the left-hand side. Let's go looking for one of the global items that we are able to get to in the console.
We currently have items grouped by what they are or who they belong to. If we open up the (closure) list, we can find the runTemplate() function being held there. If we go into the (string) list, we can find the strings that were used to create our list. A question that may be raised is why some of these items are still being held on the heap even though we no longer need them. Well, this goes back to how the garbage collector works and who is currently referencing these items.
Take a look at the list items that are currently being held in memory. If you click on each of them, it shows us they are being referenced by loopEls. If we head back into our code, it can be noted that the only line of code that we use, loopEls, is in the following:
const tempFun = runTemplate.bind(null, loopTemp);loopEls = data.items.map(tempFun);Take this out and put the basic for loop back in. Run the heap snapshot and go back into the (strings) section. These strings are no longer there! Let's change the code one more time using the map function, but this time let's not use the bind function to create a new function. The code should look like the following:
const loopEls = data.items.map((item) => { return runTemplate(loopTemp, item);});Again, run a heap snapshot after changing out the code and we will notice that those strings are no longer there. An astute reader will notice that there is an error in the code from the first run; the loopEls variable does not have any variable type prefix added to it. This has caused the loopEls variable to go onto the global scope, which means that the garbage collector cannot collect it, since the garbage collector thinks that the variable is still in use.
Now, if we turn our attention to the first item in this list, we should observe that the entire template string is still being held. If we click on that element, we will notice that it is being held by the template variable. However, we may state that since the variable is a constant, it should automatically be collected. Again, the V8 compiler does not know this and has put it on the global scope for us.
There are two ways that we can fix this issue. First, we can use the old-school technique and wrap it in an Immediately Invoked Function Expression (IIFE), which would look like the following:
(function() { })();Or, if we wanted to and were writing our application only for browsers that support it, we could change the script type to a type of module. Both of these solutions make sure that our code is not now globally scoped. Let's put our entire code base in an IIFE since that is supported across all browsers. If we run a heap dump, we will see that that string is no longer there.
Finally, the last area that should be touched on is the working set of heap space and the amount it actually has allocated. Add the following line to the top of the HTML file:
<script type="text/javascript" src="./fake_library.js"></script>This is a simple file that adds itself to the window to act as a library. Then, we are going to test two scenarios. First, run the following code:
for(let i = 0; i < 100000; i++) { const j = Library.outerFun(true); const k = Library.outerFun(true); const l = Library.outerFun(true); const m = Library.outerFun(true); const n = Library.outerFun(true);}Now, go to the performance section and check out the two numbers that are being displayed. If need be, go ahead and hit the garbage can. This causes the major garbage collector to run. It should be noted that the left-hand number is what is currently being used, and the right-hand number is what has been allocated. This means that the V8 engine has allocated around 6-6.5 MB of space for the heap.
Now, let's run the code in a similar fashion, but let's break each of these runs into their own loops, like the following:
for(let i = 0; i < 100000; i++) { const j = Library.outerFun(true);}Check the Performance tab again. The memory should be around 7 MB. Go ahead and click the trash can and it should drop back down to 5.8 MB, or around where the baseline heap should be at. What did this show us? Well, since it had to allocate items for each of those variables in the first for loop, it had to increase its heap space. Even though it only ran it once and the minor garbage collector should have collected it, it is going to keep that heap space due to heuristics built into the garbage collector. Since we decided to do that, the garbage collector will keep more memory in the heap because we are more than likely going to keep repeating that behavior in the short term.
Now, with the second set of code, we decided to use a bunch of for loops and only allocate a single variable at a time. While this may be slower, V8 saw that we were only allocating small chunks of space and that it could decrease the size of the main heap because we are more than likely to keep up the same behavior in the near future. The V8 system has a bunch of heuristics built into the system and it will try and guess what we are going to do based on what we have done in the past. The heap allocator can help show us what the V8 compiler is going to do and what our coding pattern is most like in terms of memory usage.
Go ahead and keep playing with the memory tab and add code in. Take a look at popular libraries (try to keep them small so you can track the memory allocations) and notice how they decided to write their code and how that causes the heap allocator to retain objects in memory and even keep a larger heap size around.
Note
It is generally good practice for a multitude of reasons, but writing small functions that do one thing very well is also great for the garbage collector. It will base its heuristics on the fact that a coder is writing these tiny functions and will decrease the overall heap space it will keep around. This, in turn, will cause the memory footprint of the application to also go down. Remember, it is not the working set size (the left-hand number) but the total heap space (the right-hand number) that is our memory usage.
Chrome – an in-depth look at the Rendering tab
The last section that we will look at in the developer tools is going to be the rendering section. This is usually not a default tab that is available. In the toolbar, you will notice a three-dot button next to the Close button. Click that, go to More tools, and click the Rendering option.
There should now be a tabbed item next to the Console tab that looks like the following:
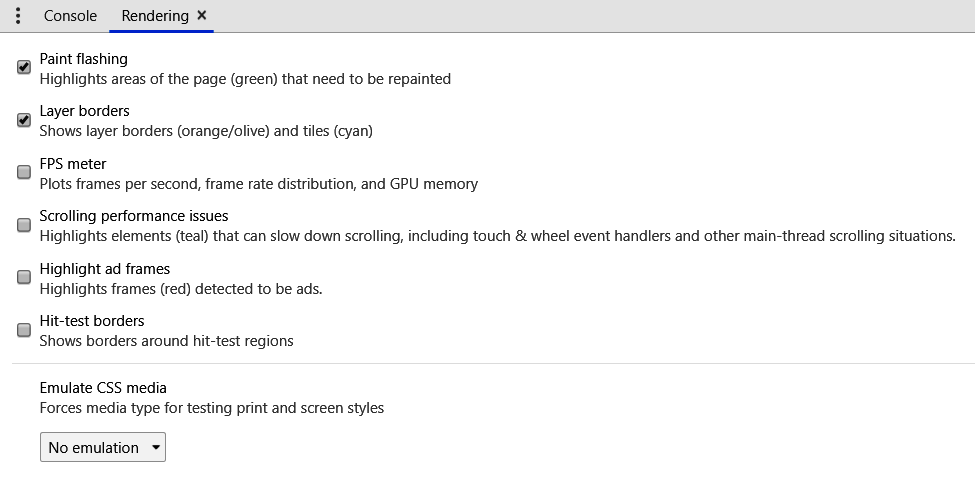
This tab can showcase a few items that we will be interested in when we are developing applications:
- First, when developing an application that is going to have a lot of data or a lot of eventing, it is suggested having the FPS meter turned on. This will not only let us know if our GPU is being utilized, but it will also show us if we are dropping frames due to constant repainting.
- Second, if we are developing an application that has a lot of scrolling (think of the infinite scrolling applications), then we will want to turn on the Scrolling performance issues section. This can notify us if there is an item or items in our application that can make the scrolling experience unresponsive.
- Finally, the Paint flashing option is great to see when there is a lot of dynamic content in our application. It will flash when a paint event has occurred and it will highlight the section that had to be repainted.
We are going to go through an application that is going to cause problems for most of these settings and see how we can improve the performance to make the user experience better. Open up the following file: chrome_rendering.html.
We should see a box in the top-left corner switching colors. If we turn on the Paint flashing option, we should now see a green box appearing whenever the box color changes.
This makes sense. Every time we recolor something, this means that the renderer has to repaint that location. Now, uncomment the following lines:
let appendCount = 0;const append = function() { if( appendCount >= 100 ) { return clearInterval(append); } const temp = document.createElement('p'); temp.textContent = `We are element ${appendCount}`; appendEl.appendChild(temp); appendCount += 1;};setInterval(append, 1000);We should see elements being added at an interval of around 1 second. A couple of things are interesting. First, we still see that we are getting repainting done on the box that colors itself every second or so. But, on top of this, we will notice that the scrollbar is repainting itself. This means that the scrollbar is part of the rendering surface (some of you may know this since you can target scrollbars with CSS). But, what is also interesting is that when each element is added, it is not having to repaint the entire parent element; it is only painting where the child is being added.
So, a good question now would be: What happens if we prepend an element to our document? Comment out the lines of code that are changing the DOM and uncomment the following lines of code to see this in action:
setTimeout(() => { const prependElement = document.createElement('p'); prependElement.textContent = 'we are being prepended to the entire DOM'; document.body.prepend(prependElement);}, 5000);We can see that around five seconds into the lifetime of the document, both the element that we added and the red box that is sitting there have been repainted. Again, this makes sense. Chrome has to repaint anything that has changed when an update occurred. In terms of what our window looks like, this means it had to change the location of the box, and add in the text we added at the top, causing a repaint of both items.
Now, an interesting thing that we can look at is what happens if we make the element absolutely positioned with CSS. This would mean, in terms of what we see, that only the top portion of the rectangle and our text element should need a repaint. But, if we do this by making the position absolute, we will still see that Chrome had to repaint both elements.
Even if we change the line document.body.prepend to document.body.append, it will still paint both objects. Chrome has to do this because the box is one DOM object. It cannot repaint only parts of objects; it has to repaint the entire object.
A good thing to always remember is that when changing something in the document, what is it causing to reflow or repaint? Is adding a list item also causing other elements to move, change color, and so on? If it does, we may have to rethink our content hierarchy so we can ensure that we are causing the minimum amount of repainting in our document.
A final note on painting. We should see how painting works with the canvas element. The canvas element allows us to create 2D and 3D imagery through the 2D rendering context, or through the WebGL context. We will specifically focus on the 2D rendering context, but it should be noted that these rules also apply with the WebGL context.
Go ahead and comment out all of the code we have added so far and uncomment the following lines:
const context = canvasEl.getContext('2d');context.fillStyle = 'green';context.fillRect(10, 10, 10, 10);context.fillStyle = 'red';context.fillRect(20, 20, 10, 10);setTimeout(() => { context.fillStyle = 'green'; context.fillRect(30, 30, 10, 10);}, 2000);After about two seconds, we should see the addition of a green box to our little diagonal group of squares. What is interesting about this paint is that it only showed us a repaint for that little green square. Let's comment out that piece of code and add in the following code:
const fillStyles = ['green', 'red'];const numOfRunsX = 15;const numOfRunsY = 10;const totalRuns = numOfRunsX * numOfRunsY;let currX = 0;let currY = 0;let count = 0;const paint = function() { context.fillStyle = fillStyles[count % 2]; context.fillRect(currX, currY, 10, 10); if(!currX ) { currY += 10; } if( count === totalRuns ) { clearInterval(paint); }}setInterval(paint, 1000);At intervals of about 1 second, we will see that it is truly only repainting where we say to paint. This can have huge implications for applications that need to be constantly changing the information that is on the page. If we find that we need to have something constantly update, it can actually be better to have it done in a canvas than to have it in the DOM. While the canvas API may not lend itself to being a rich environment, there are libraries out there that help with this.
Note
It is not suggested that every application out there is going to need the repainting capabilities of the canvas; it should be noted that most will not. However, every piece of technology that we talk through in this book is not going to solve 100% of the issues found in applications. One such issue is repainting problems and this can be solved with canvas-based solutions. Areas that the canvas is especially useful for are graphing and grid-based applications.
We will now look at the scroll option. This can help us when we have a long list of items. This may be in a tree-view, in an infinite scrolling application, or even in a grid-based application. At some point, we are going to run into serious slowdowns due to trying to render thousands of elements at a single time.
First, let's render 1,000,000 paragraph elements into our application with the following code:
for(let i = 0; i < 1000000; i++) { const temp = document.createElement('p'); temp.textContent = `We are element ${i}`; appendEl.appendChild(temp);}While this may not seem like a real-world scenario, it does showcase how unfeasible infinitely loaded applications would be to run if we had to add everything to the DOM right away. So how would we handle this scenario? We would use something called deferred rendering. Essentially, we will have all of our objects in memory (in this case; for other use cases, we would continually make rest requests for more data) and we will add them as they should appear on the screen. We will need some code to do this.
Note
The following example is by no means a foolproof way of implementing deferred rendering. As with most of the code in this book, it takes a simple view to try to showcase a point. It can easily be built upon to create a real-world system for deferred rendering, but it is not something that should be copied and pasted.
A good way to start deferred rendering is to know how many elements we are going to have, or at least want to showcase in our list. For this, we are going to use a height of 460 pixels. On top of this, we are going to set our list elements to have a padding of 5 pixels and to be a height of 12 pixels with a 1-pixel border on the bottom. This means that each element will have a total height of 23 pixels. This would also mean that the number of elements that can be seen at one time is 20 (460 / 23).
Next, we set the height of our list by multiplying the number of items we have by the height of each item. This can be seen in the following code:
list.style.height = `${itemHeight * items.length}px`;Now, we need to hold our index that we are currently at (the current 20 items on the screen) and measure when we get a scroll event. If we notice that we are above the threshold, we move to a new index and reset our list to hold that group of 20 elements. Finally, we set the top padding of our unordered list to the total height of the list minus what we have already scrolled by.
All of this can be seen in the following code:
const checkForNewIndex = function(loc) { let tIndex = Math.floor(Math.abs(loc) / ( itemHeight * numItemsOnScreen )); if( tIndex !== currIndex ) { currIndex = tIndex; const fragment = document.createDocumentFragment(); fragment.append(...items.slice(currIndex * numItemsOnScreen, (currIndex + 2) * numItemsOnScreen)); list.style.paddingTop = `${currIndex * containerHeight}px`; list.style.height = `${(itemHeight * items.length) - (currIndex * containerHeight)}px`; list.innerHTML = ''; list.appendChild(fragment); }}So now that we have all of this, what do we put this function inside of? Well, since we are scrolling, logically, it would make sense to put it in the scroll handler of the list. Let's do that with the following code:
list.onwheel = function(ev) { checkForNewIndex(list.getBoundingClientRect().y);}Now, let's turn on the Scrolling performance issues option. If we reload the page, we will notice that it is highlighting our list and stating that the mousewheel event could be a potential bottleneck. This makes sense. Chrome notices that we are attaching a non-trivial piece of code to run on each wheel event so it shows us that we are going to potentially have issues.
Now, if we are on a regular desktop, we will most likely not have any issues, but if we add the following code, we can easily see what Chrome is trying to tell us:
const start = Date.now();while( Date.now() < start + 1000 ) {; }With that piece of code inside the wheel event, we can see the stuttering happen. Since we can now see stuttering and it being a potential bottleneck for scrolling, what's the next best option? Putting it in a setInterval, using requestAnimationFrame, or even using requestIdleCallback, with the last being the least optimal solution.
The Rendering tab can help flesh out quite a few issues that can crop up inside our applications and should become a regular tool for developers to figure out what is causing stuttering or performance problems in their applications.
These three tabs can help diagnose most problems and should be used quite frequently when developing an application.
jsPerf and benchmarking
We have come to the last section regarding high performance for the web and how we can easily assess whether our application is performing at peak efficiency. However, there are times when we are going to want to actually do true benchmarking, even if this may not give the best picture. jsPerf is one of these tools.
Now, great care has to be taken when creating a jsPerf test. First, we can run into optimizations that the browser does and that may skew results in favor of one implementation versus another. Next, we have to make sure that we run these tests in multiple browsers. As explained in a previous section, every browser runs a different JavaScript engine and this means that the creators have implemented them all differently. Finally, we need to make sure that we do not have any extraneous code in our tests, otherwise, the results can be skewed.
Let's look at a couple of scripts and see how they turn out based on running them inside jsPerf. So, let's begin:
- Head on over to https://jsperf.com. If we want to create our own tests, we will have to sign in with our GitHub account, so go ahead and do this now.
- Next, let's create our first performance test. The system is self-explanatory, but we will go over a couple of areas:
- First, if we needed to add in some HTML code so that we could perform DOM manipulation, we would put this in the preparation code HTML section.
- Next, we will put in any variables that we will need in all of our tests.
- Finally, we can incorporate our test cases. Let's run a test.
- The first test we will look at is utilizing a loop versus utilizing the
filterfunction. We will not require any HTML for this, so we can leave this section blank. - Next, we will input the following code that will be needed by all of our test cases:
const arr = new Array(10000);for(let i = 0; i < arr.length; i++) { arr[i] = i % 2 ? i : -1;}- Then, we will add in two different test cases, the
forloop and thefilterfunction. They should look like the following:
In the case of the loop:
const nArr = [];for(let i = 0; i < arr.length; i++) { if( Math.abs(arr[i]) === arr[i]) { nArr.push(arr[i]); }}In the case of the filter:
const nArr = arr.filter(item => Math.abs(item) === item);- Now, we can save the test case and run the performance tester. Go ahead and hit the Run button and watch as the test runner goes over each piece of code multiple times. We should see something like the following:
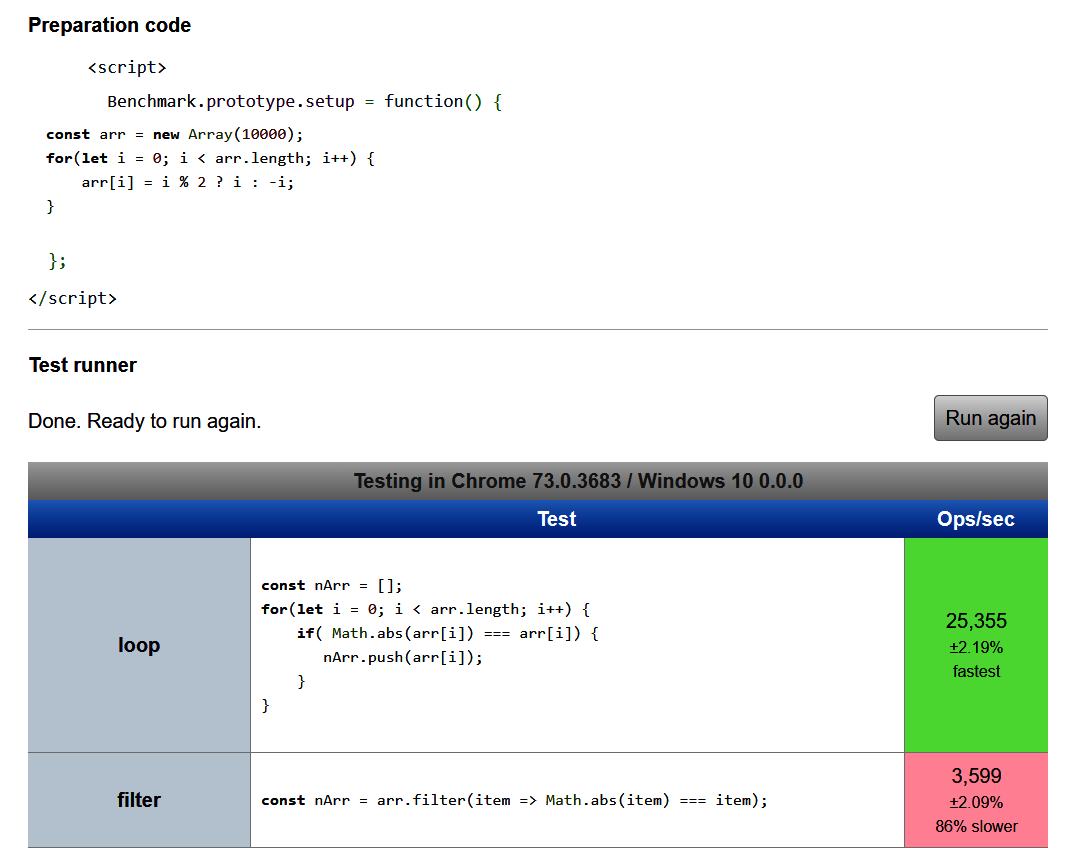
Well, as expected, the for loop performed better than the filter function. The breakdown of those three numbers on the right is as follows:
- The number of operations per second, or how many basic instructions the system could run in a single second.
- The variance in each test run for that specific test case. In the case of the
forloop, it was plus or minus 2 percent. - Finally, it will say whether it was the fastest, or how much slower than that it was. In the case of the filter, it was 86 percent slower.
Wow, that is quite significantly slower! In this case, we might think of a way for the filter to run more optimally. One way is that we might create the function ahead of time instead of creating an anonymous function. Near the bottom of our results, we will see a link for us to be able to add more tests. Let's head back into the test cases and add one for our new test.
Head near the bottom and there should be an Add code snippet button. Let's press this and fill in the details. We will call this new code snippet filterFunctionDefined and it should look something like the following:
const reducer = function(item) { return Math.abs(item) === item;}const nArr = arr.filter(reducer);We can save this test case and rerun our results. The results seem to be almost exactly like the regular filter function. Some of this is due to our browsers optimizing our code for us. We can test these results in all of the browsers so we can get a better picture of how our code would function in each. But, even if we did run this elsewhere, we will see that the results are the same; the filter function is slower than a regular for loop.
Note
This is true for pretty much every array-based function. Helper functions are great, but they are also slower than regular loops. We will go into greater detail in the next chapter, but just realize ahead of time that most of the convenience that the browser gives us is going to be slower than just writing the function in a more straightforward manner .
Let's set up another test just to make sure we understand jsPerf.
First, create a new test. Let's perform a test on objects and see the difference between using a for-in loop versus a loop utilizing the Object.keys() method. Again, we will not need to utilize the DOM so we don't need to fill anything out for the HTML portion.
For our test setup, let's create a blank object and then fill it with a bunch of useless data utilizing the following code:
const obj = {};for(let i = 0; i < 10000; i++) { obj[`item${i}`] = i;}Next, let's create two test cases, the first being call for in, which should appear as follows:
const results = [];for(let key in obj) { results.push([key, obj[key]]);}The second test case is the Object.keys() version, which appears as follows:
const results = [];const keys = Object.keys(obj);for(let i = 0; i < keys.length; i++) { results.push([keys[i], obj[keys[i]]);}Now, if we run our test, we will notice that the keys version is able to do around 600 operations per second, while the fo..in version is able to do around 550. This one is fairly close so browser difference may actually come into play. When we start to get into minor differences, it is best to choose whichever was implemented later or is most likely to get optimizations.
Note
Most of the time, if something is just being implemented and the browser vendors agree to something being added, then it is probably in the early stages of development. If the performance results are within a tolerance that is allowed (usually around 5-10% difference), then it is best to go with the newer option. It is more likely to be optimized in the future.
All of this testing is amazing, and if we find something that we truly want to share with people, this is a great solution. But, what if we wanted to run these tests ourselves and not have to worry about an external site? Well, we can utilize the underlying library that jsPerf is using. It is called Benchmark.js and it is a great utility when we need to set up our own system for debugging code. We can find it at https://benchmarkjs.com/.
Let's grab the source code and set it as an external script in our HTML file. We will also need to add Lodash as a dependency. Next, let's write the same tests that we wrote before, but we are going to write them in our internal script and have it display the results on our screen. We will also only have it display the title of our script along with these results.
We can obviously make this a little fancier, but the focus will be on getting the library to properly benchmark for us.
We will have some setup code that will have an array of objects. These objects will have only two properties, the name of the test and the function that we want to run. In the case of our for loop versus our filter test, it would look like the following:
const forTest = Object.assign({}, testBaseObj);forTest.title = 'for loop';forTest.fun = function() { const arr = []; for(let i = 0; i < startup.length; i++) { if( Math.abs(startup[i]) === startup[i] ) { arr.push(startup[i]); } }}const filterTest = Object.assign({}, testBaseObj);filterTest.title = 'filter';filterTest.fun = function() { const arr = startup.filter((item) => Math.abs(item) === item);}const tests = [forTest, filterTest];From here, we set up a benchmark suite and loop through our tests, adding them to the suite. We then add two listeners, one for a complete cycle so we can display it in our list, and the other on completion, so we can highlight the fastest running entry. It should look like the following:
const suite = new Benchmark.Suite;for(let i = 0; i < tests.length; i++) { suite.add(tests[i].title, tests[i].fun);}suite.on('cycle', function(event) { const el = document.createElement('li'); el.textContent = event.target; el.id = event.target.name; appendEl.appendChild(el);}).on('complete', function() { const fastest = this.filter('fastest').map('name'); document.getElementById(fastest[0]).style.backgroundColor = 'green';}).run({ 'async' : true });If we set all of this up, or if we run benchmark.html, we will see the output. There are many other cool statistics that we can get from the benchmark library. One of these is the standard deviation for each test. In the case of the for loop test that was run in Edge, it came out to around 0.004. Another interesting note is that we can look at each run and see the amount of time it took. Again, taking the for loop example, the Edge browser is slowly optimizing our code and also likely putting it into cache since the time keeps decreasing.
Summary
This chapter introduced many concepts for profiling and debugging our code. It took into account the various modern browsers that are out there and even the special features that each of them may or may not have. We specifically looked at the Chrome browser, since a good many developers use it as their main development browser. In addition to this, the V8 engine is used in Node.js, which means all of our Node.js code will use the V8 debugger. Finally, we took a look at utilizing jsPerf to find out what may be the best implementation of some piece of code. We even looked at the possibilities of running it in our own system and how we can implement this.
Looking forward, the remainder of the book will not specifically talk about any of these topics in such detail again, but these tools should be used when developing the code for the rest of the book. On top of this, we will be running almost all of the code in the Chrome browser, except for when we write GLSL, since Firefox has one of the best components for actually testing this code out. In the next chapter, we will be looking at immutability and when we should utilize it in development.