Setting the Scene
Section 1: What is Clean Code Anyway?
In this section, we'll discuss the purpose of code and the tenets of it, such as clarity and maintainability. We'll also cover the very broad challenge of naming things, as well as some of the valuable questions and hazards to watch out for.
This section contains the following chapters:
- Chapter 1, Setting the Scene
- Chapter 2, The Tenets of Clean Code
- Chapter 3, The Enemies of Clean Code
- Chapter 4, SOLID and Other Principles
- Chapter 5, Naming Things Is Hard
Setting the Scene
JavaScript was created by Brendan Eich in 1995, with the goal of being a glue language. It was intended to help web designers and amateurs easily manipulate and derive behavior from their HTML. JavaScript was able to do this via the DOM API, a set of interfaces provided by the browser that would give access to the parsed representation of HTML. Soon after this, DHTML became the popular term, referring to the more dynamic user interfaces that JavaScript enabled: everything from animated rollover button states to client-side form validation. Eventually came the rise of Ajax, which enabled communication between the client and the server. This opened up a considerable fountain of potential applications. The web, previously purely the domain of documents, was now on the way to becoming a powerhouse of processor- and memory-intensive applications:

In 1995, nobody could have predicted that JavaScript would one day be used to build complex web applications, program robots, query databases, write plugins for photo manipulation software, and be behind one of the most popular server runtimes in existence, Node.js.
In 1997, not long after its creation, JavaScript was standardized by Ecma International under the name ECMAScript, and it is still undergoing frequent changes under the TC39 committee. Most recent versions of the language have been named according to the year of their release, such as ECMAScript 2020 (ES2020).
Due to its burgeoning capabilities, JavaScript has attracted a passionate community that drives its growth and ubiquity. And due to its considerable popularity, there are now countless different ways to do the same thing in JavaScript. There are thousands of popular frameworks, libraries, and utilities. The language too is changing on a near-constant basis in reaction to the increasing demands of its applications. This creates a great challenge: among all of this change, while being pushed and pulled in different directions, how can we know how to write the best possible code? Which frameworks should we use? What conventions should we employ? How should we test our code? How should we craft sensible abstractions?
To answer these questions, we need to briefly go back to basics. And that is the purpose of this chapter. We'll be discussing the following:
- What the true purpose of the code is
- Who our users are and what problems they have
- What it means to write code for humans
Why we write code
At its simplest, we know that programming is about instructing computers, but what are we instructing them to do? And to what end? And what other purposes does code serve?
We can broadly say that code is a way of solving problems. By writing code, we are expressing a complex task or series of actions, distilling them into a singular process that can be easily utilized by a user. So we can say that the code is an expression of a problem domain. We can even say it is a form of communication, a way to relay information and intent. Understanding that code is a complex thing with many complementary purposes, such as problem-solving and communication, will enable us to use it to its fullest potential. Let's delve further into this complexity by exploring what we mean when we speak of code as a method of relaying intent.
Code as intent
We often think of code as simply a series of instructions that are executed by a computer. But in many ways, this misses the true magic of what we're doing when we write code. When we convey instructions, we are expressing our intent to the world; we are saying These are the things that I want to occur.
Humans have been conveying instructions for as long as they've been around. One example of this is a simple cooking recipe:
Cut about three hundred grams of butter (small cubes!)
Take 185 grams dark chocolate
Melt it with butter over a saucepan
Break half dozen eggs, ideally large ones
Mix them together with a few cups of sugar
Instructions like these are quite easy to understand for a human, but you'll notice they follow no strict specification. The measuring units are inconsistent, as is the punctuation and the wording. And some of the instructions are quite ambiguous and therefore open to misinterpretation by someone who hasn't cooked before:
- What constitutes a large egg?
- When should I consider the butter fully melted?
- How dark should the dark chocolate be?
- How small is a small cube of butter?
- What does over a saucepan mean?
Humans can usually muddle through such ambiguities with their initiative and experience, but machines aren't so adept. A machine must be instructed with enough specificity to carry out every step. What we wish to communicate to a machine is our intent, that is, please do this thing, but due to the nature of machines, we must be utterly specific. Thankfully, how we choose to write these instructions is up to us; there are many programming languages and approaches, and almost all of them were created with the goal of making it easier for humans to communicate their intent in a less burdensome way.
The distance between human capability and computing capability is quickly narrowing. The advent of machine learning, natural language processing, and highly specialized programs means that machines are far more flexible in the types of instructions they can carry out. However, code will continue to be useful for some time, as it allows us to communicate in a highly specific and standardized way. With this high level of specificity and consistency, we can have more faith that our instructions will be executed as intended, every time.
Who is the user?
No meaningful conversation about programming can occur without considering the user. The user, whether they are a fellow programmer or the end user of a UI, is at the core of what we do.
Let's imagine that we are tasked with validating user-inputted shipping addresses on a website. This particular website sells medication to hospitals around the world. We're in a bit of a rush and would prefer to use something that someone else has implemented. We find a publicly available package called shipping_address_validator and decide to use it.
If we had taken the time to check the code within the package, in its postal code validation file, we would have seen this:
function validatePostalCode(code) { return /^[0-9]{5}(?:-[0-9]{4})?$/.test(code);}Note
This validatePostalCode function happens to be using regular expressions (also known as RegExp and regex), delimited by forward slashes, to define a pattern of characters to match a string against. You can read more about these constructs in Chapter 6, Primitive and Built-In Types.
Unfortunately, due to our haste, we didn't question the functionality of the shipping_address_validator package. We assumed it did what it says on the tin. One week after releasing our code to production we get a bug report saying that some users are unable to enter their address information. We look at the code and realize, to our horror, that it only validates US ZIP codes, not all countries' postal codes (for example, it doesn't work on UK postcodes, such as GR82 5JY).
Through this unfortunate series of events, this piece of code is now responsible for blocking the shipment of vital medication to customers all over the world, numbering in the thousands. Fortunately, fixing it doesn't take too long.
Forgetting for a moment who is responsible for this mishap, I'd like to pose the following question: who are the users of this code?
- We, the programmers, who decided to use the
shipping_address_validatorpackage? - The unwitting customers who are attempting to enter their addresses?
- The patients in the hospitals who are left waiting for their medication?
There isn't a clear-cut answer to this question. When bugs appear in the code, we can see how there can be massive unfortunate downstream effects. Should the original programmer of the package be concerned with all these downstream dependencies? When a plumber is hired to fix a tap on a sink, should they only consider the function of the tap itself, or the sink into which it pours?
When we write code, we are defining an implicit specification. This specification is communicated by its name, its configuration options, its inputs, and its outputs. Anyone who uses our code has the right to expect it to work according to its specifications, so the more explicit we can be, the better. If we're writing code that only validates US ZIP codes, then we should name it accordingly. When people create software atop our code, we can't have any control over how they use it. But we can communicate explicitly about it, ensuring that its functionality is clear and expected.
It's important to consider all use cases of our code, to imagine how it might be used and what expectations humans will have about it, programmers and end users alike. What we are responsible or accountable for is up for debate, and is as much a legal question as a technical one. But the question of who our users are is entirely up to us. In my experience, the better programmers consider the full gamut of users, aware that the software they write does not exist in a vacuum.
What is the problem?
We've spoken about the importance of the user in programming, and how we must first understand what it is they wish to do if we are to have any hope of helping them.
Only by understanding the problem can we begin to assemble requirements that our code will have to fulfill. In the exploration of the problem, it's useful to ask yourself the following questions:
- What problem is the user encountering?
- How do they currently carry out this task?
- What existing solutions are there and how do they work?
When we have assembled a complete understanding of the problem, we can then begin ideating, planning, and writing code to solve it. At each step, often without realizing it, we will be modeling the problem in a way that makes sense to us. The way we think about the problem will have a drastic effect on the solution we end up creating. The model of the problem we create will dictate the code we end up writing.
Note
What is the model of a problem?
A model or conceptual model is a schematic or representation that describes how something works. We create and adapt models all the time without realizing it. Over time, as you gain more information about a problem domain, your model will improve to better match reality.
Let's imagine for a moment that we are responsible for a note-taking application for students and are tasked with creating a solution to the following problem that a user has expressed:
"I have many notes for my studies and so am finding it hard to organize them. Specifically, when trying to find a note on a given topic, I'll try to use the Search feature but I rarely find what I'm looking for since I can't always recall the specific text I wrote."
We've decided that this warrants changes to the software because we've heard similar things from other users. So, we sit down and try to come up with various ideas for how we could improve the organization of notes. There are a few options we could explore:
- Categories: There would be a hierarchical folder structure for categories. A note on Giraffes might exist under studies/zoology. Categories can be easily navigated manually or via search.
- Tags: There would be the ability to tag a note with one or more words or phrases. A note on Giraffes might be tagged with mammal and long neck. Tags can then be easily navigated manually or via search.
- Links: Introduce a linking feature so notes can link to other notes that are related. A note on Giraffes might be linked to from another note, such as the one on Animals with long necks.
Each solution has its pros and cons, and there is also the possibility of implementing a combination of them. One thing that becomes immediately obvious is that each of these will quite drastically affect how users end up using the application. We can imagine how users exposed to these respective solutions would hold the model of note-taking in their minds:
- Categories: Notes I write have their place in my categorical hierarchy
- Tags: Notes I write are about many different things
- Links: Notes I write are related to other notes I write
In this example, we're developing a UI, so we are sitting very close to the end user of the application. However, the modeling of problems is applicable to all of the work we do. If we were creating a pure REST API for note-keeping, exactly the same considerations would need to be made. Web programmers play a key part in deciding what models other people end up employing. We should not take this responsibility lightly.
Truly understanding the problem domain
The first point of failure is typically misunderstanding the problem. If we don't understand what users are truly trying to accomplish, and we have not received all requirements, then we will inevitably retain a bad model of the problem and thus end up implementing the wrong solutions.
Imagine that this scenario occurs at some point before the invention of the kettle:
- Susanne (engineer): Matt, we've been asked to design a vessel that users can boil water with
- Matthew (engineer): Understood; I will create a vessel that does exactly that
Matthew asks no questions and immediately gets to work, excited at the prospect of putting his creativity to use. One day later he comes up with the following contraption:

We can see, quite obviously, that Matthew has forgotten one key component. In his haste, he did not stop to ask Susanne for more information about the user, or about their problem, and so did not consider the eventuality that a user would need to pick up the boiling-hot vessel somehow. After receiving feedback, naturally, he designed and introduced a handle to the kettle:
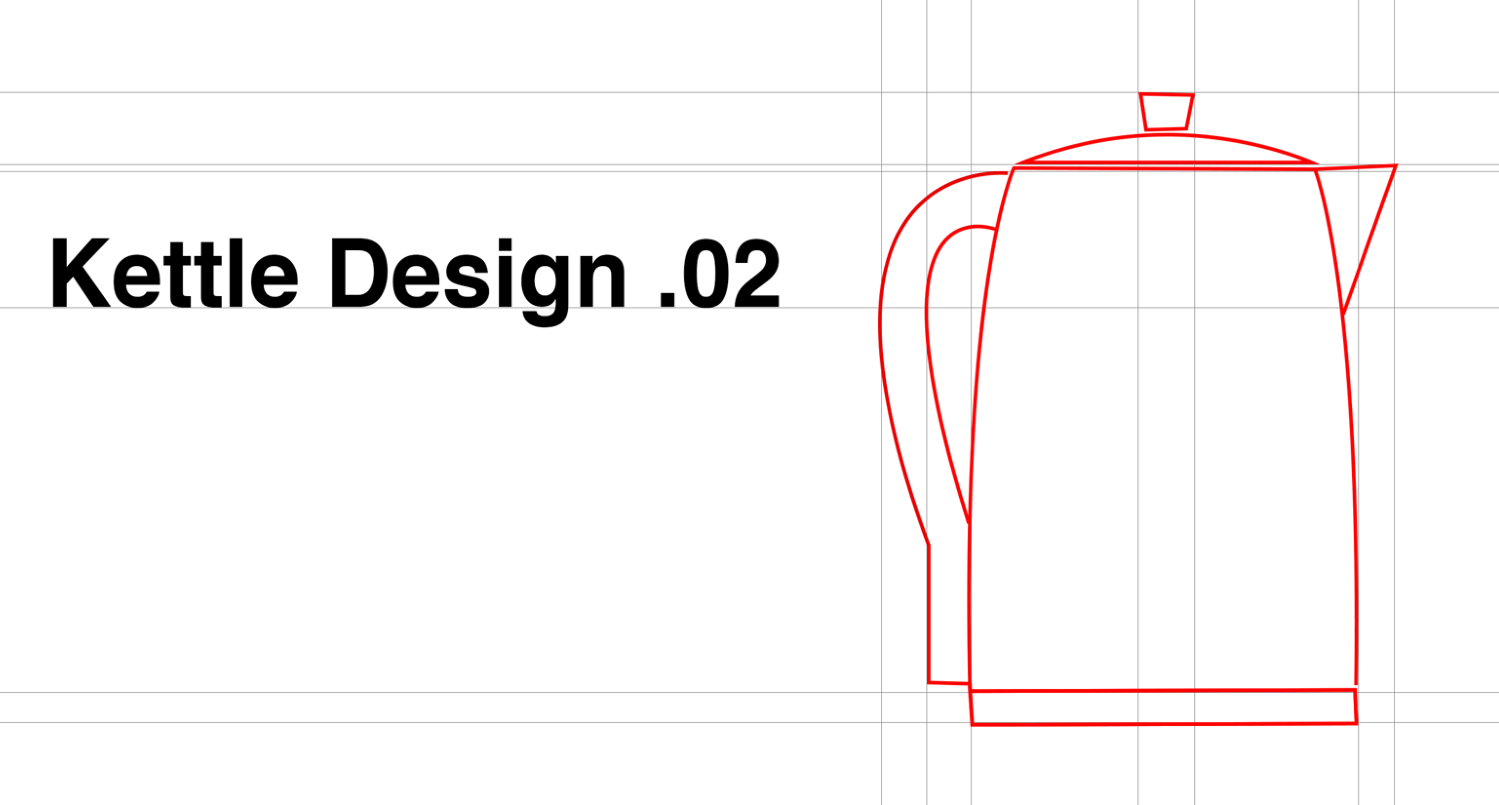
This needn't have occurred at all, though. Imagine this kettle scenario extrapolated to the complexity and length of a large software project spanning multiple months. Imagine the headaches and needless pain involved in such a misunderstanding. The key to designing a good solution to a problem requires, first and foremost, a correct and complete model of the problem. Without this, we'll fail before we even begin. This matters in the design of massive projects but also in the implementation of the smallest JavaScript utilities and components. In every line of code we write, in fact, we are utterly liable to failure if we do not first understand the problem domain.
The problem domain encapsulates not only the problem being encountered by the user but also the problem of meeting their needs via the technologies we have available. And so, the problem domain of writing JavaScript in the browser, for example, includes the complexity of HTTP, the browser object model, the DOM, CSS, and a litany of other details. A good JavaScript programmer has to be adept not only in these technologies but also in understanding new domains of problems encountered by their users.
Writing code for humans
This entire book is concerned with teaching you how to write clean code in JavaScript. In the following chapters, we'll go into a lot of detail, with discussions of almost every construct within the language. Firstly, we need to establish a few key perspectives that'll be important when we think about what it means to write clean code for humans.
Communicating intent
We can say that writing code for humans is broadly about the clarity of intent. And writing code for machines is broadly about functionality. These needs do cross over, of course, but it's vital to discern the difference. We can see the difference if we were writing code only for the machine, focusing purely on function, and forgetting the human audience. Here's an example:
function chb(d,m,y) { return new Date(y,m-1,d)-new Date / 6e4 * 70;}Do you understand what this code is doing? You may be able to decipher what's going on in this code, but it is intent—its true meaning—will be almost impossible to discern.
If we clearly express our intent then the preceding code would look something like this:
const AVG_HEART_RATE_PER_MILLISECOND = 70 / 60000;
function calculateHeartBeatsSinceBirth(birthDay, birthMonth, birthYear) {
const birthMonthIndex = birthMonth - 1; const birthDate = new Date(birthYear, birthMonthIndex, birthDay); const currentDate = new Date();
return (currentDate - birthDate) / AVG_HEART_RATE_PER_MILLISECOND;
}From the preceding code, we can discern that this function is intended to calculate the number of times a heart has beaten since birth. There is no functional difference between these two pieces of code. However, the latter code better communicates the programmer's intentions, and thus is easier to understand and to maintain.
The code we write is primarily for people. You may be building a brochure website, programming a web application, or crafting a complex utility function for a framework. All of these things are for people: people who are the end users of GUIs driven by our code or people who are the programmers making use of our abstractions and interfaces. Programmers are in the business of helping these people.
Even if you're writing code only for yourself, with no possibility of it being used in any way by anyone else, your future self will thank you if you write clear code.
Readability
When we write code, it's essential to consider how human brains will consume it. Fellow programmers will scan over your code, reading the pertinent parts, attempting to gain a running comprehension of its inner workings. Readability is the first hurdle that they must overcome. If they are unable to read and cognitively navigate the code you've written then they'll be less able to use it. This will drastically limit the utility and value of your code.
Programmers, in my experience, don't tend to like thinking of code in terms of aesthetic design, but the best programmers will appreciate that these concepts are intrinsically intertwined. The design of our code in a presentational or visual sense is as vital to its comprehensibility as its architectural design. Design, in the end, is about creating something in a way that optimally delivers a purpose for its users. For our fellow programmers, that purpose is comprehension. And so we must design our code to deliver that purpose.
Machines care purely about specifications and will parse valid code into its parts with little effort. Humans, however, are more complex. We are less capable in areas where machines excel, hence their existence, but we are also skillful in areas where machines may falter. Our highly evolved brains, among their many talents, have become incredibly skilled at spotting patterns and inconsistencies. We rely on difference, or contrast, to focus our attention. If a pattern is not being followed then it creates more work for our brains. For an example of such inconsistency, have a look at this code:
var TheName='James' ; var City = 'London'var hobby = 'Photography',job='Programming'You probably don't enjoy looking at this code. Its messiness is distracting and it appears to follow no particular pattern. The naming and spacing are inconsistent. Our brains struggle with this, and so reading the code, and building a full understanding of it, becomes more cognitively expensive.
We might refactor the preceding code to be more consistent, like so:
var name = 'James';var city = 'London';var hobby = 'Photography';var job = 'Programming';Here, we've used a single naming pattern and have employed consistent syntax and spacing in every statement.
Alternatively, perhaps we would like to declare all variables within a single var declaration and align the assignment (=) operators so that all values start along the same vertical axis:
var name = 'James', city = 'London', hobby = 'Photography', job = 'Programming';You'll notice that these different styles are very subjective. Some people prefer one way. Other people prefer another way. And that's okay. I am not stating which approach is superior. Instead, I am pointing out that if we care about writing code for humans, then we should care, first and foremost, about its readability and presentation, and consistency is a key part of that.
Meaningful abstractions
As we write code, we use and create abstractions constantly. Abstraction is what occurs when we take a piece of complexity and then present access to that complexity in a simpler way. By doing this, we enable people to have leverage over that complexity without having to wield a full understanding of it. This idea underpins most modern technology:

JavaScript, like many other high-level languages, presents an abstraction that enables us not to have to worry about the details of how a computer operates. We can, for example, ignore the problem of memory allocation. Even though we must be sensitive to the constraints of hardware, especially on mobile devices, we'll rarely ever think about it. The language doesn't require us to.
The browser, too, is a famous abstraction. It provides a GUI that abstracts away, among many other things, the details of HTTP communication and HTML rendering. Users can easily browse the internet without ever having to worry about these mechanisms.
In the following chapters of this book, we'll learn more about what it takes to craft a good abstraction. For now, it's enough to say this: in every line of code you write, you are using, creating, and communicating abstractions.
The tower of abstraction
The tower of abstraction is a way of looking at the complexity of technology. At the base layer, we have the hardware mechanisms depended upon in computation, such as transistors in the CPU and memory cells in RAM. Above that, we have integrated circuits. Above that, you have machine code, assembly, and the operating system. And above that, several layers up, you have the browser, and its JavaScript runtime. Each layer abstracts away complexity so that the layer above can leverage that complexity without too much effort:

When we write JavaScript for the browser, we are already operating on a very tall tower of abstraction. The higher this tower gets, the more precariously it operates. We are dependent on every individual part working as expected. It's a fragile system.
The tower of abstraction is a useful analogy when thinking about our users as well. When we write code, we are adding to this tower, building upon it layer by layer. Our users will always be situated above us on this tower, using the machinery we've crafted to drive their own ends. These users may be other programmers that utilize our code, building yet more layers of abstraction into the system. Alternatively, our users may be the end users of the software, typically sitting atop the tower and leveraging its vast complexity by a simplified GUI.
The layers of clean code
In the next part of the book, we will take the foundational concepts we've talked about in this chapter and build atop them with our own abstractions; these abstractions are the ones we, in the software industry, use to talk about what it means to write clean code.
If we say that our software is reliable or usable, then we are employing abstract concepts. And these concepts must be delved into. We will also be unpicking the innards of JavaScript in later chapters, seeing what it means to deal with the individual pieces of syntax that power our programs. By the end of the book, we should be able to say that we have complete knowledge of multiple layers of clean code, from individually readable lines of code to well-designed and reliable architectures.
Summary
In this chapter, we have built ourselves a great foundation, exploring the very fundamentals that underpin all of the code we write. We have discussed how our code is an expression of intent, and how, in order to build that intent, we must have a sound understanding of what the user requires and the problem domain we are engaging in. We have also explored how we can write code that is clear and readable to humans, and how we can create clear abstractions that provide users with the ability to leverage complexity.
In the next chapter, we will build on this foundation with the specific tenets of clean code: reliability, efficiency, maintainability, and usability. These tenets will be lending us a vital perspective as we go on to study the many facets of JavaScript and how we can wield it in the service of clean code.