
Key Takeaways
- Ruby doesn’t include support for linked lists but Matz included features you would normally associate with linked lists in the Ruby Array class, such as Array#push and Array#unshift to add an element to an array, or Array#pop and Array#shift to remove an element from an array.
- Ruby arrays can function as linked lists, providing methods to add or remove elements from a list. However, the performance may slow down if you need to add or remove elements to the head of the list or somewhere in the middle, due to the shifting of remaining elements.
- Ruby arrays are not functional data structures by default but they can be used as such. Functional programming languages discourage the use of mutable values and instead use pure functions and immutable values, which can increase reliability and robustness of your code.
- Ruby uses a series of tricks known as “copy on write optimization,” to share values across different arrays, maintaining a single copy of the larger array with all the data values, and creating the second array using a simple pointer or reference to the middle of larger array.
- If you need to repeatedly insert, remove and reorder elements in a large list, a real linked list might be what you need to avoid the performance penalties associated with array resizing and shifting. One simple way to create a linked list in Ruby would be to use the Struct object to represent a cons cell.

Have you ever noticed Ruby doesn’t include support for linked lists? Most computer science textbooks are filled with algorithms, examples and exercises based on linked lists: inserting or removing elements, sorting lists, reversing lists, etc. Strangely, however, there is no linked list object in Ruby.
Recently after studying Haskell and Lisp for a couple of months, I returned to Ruby and tried to use some of the functional programming ideas I had learned about. But how do I create a list in Ruby? How do I add or remove an element from a list in Ruby? Ruby contains fast, internal C implementations of the Array and Hash classes, and in the standard library you can find Ruby code implementing the Set, Matrix, and Vector classes among many other things. But no linked lists – why?
The answer is simple: Matz included features you would normally associate with linked lists in the Ruby Array class. For example, you can use Array#push and Array#unshift to add an element to an array, or Array#pop and Array#shift to remove an element from an array.
Today I’m going to look at a few common operations you would normally use a linked list for, and then take a look at how you would implement them using an array. We’ll also get some insight into how Ruby’s array object works internally.
Using an Array as a Linked List
When I think of linked lists, I think of the Lisp programming language, short for “List Processor.” In his classic article, Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I, Lisp inventor John McCarthy defined the “cons cell” as the basic building block of linked lists, and a corresponding “(cons …)” Lisp function to create these cons cells.
For example, to create a list (2, 3) in Lisp you would call:
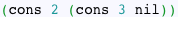
Internally Lisp would create a linked list that looks like this:
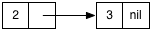
In Ruby, since we don’t have a “List” object, we can achieve the same thing using an array and the Array#unshift method like this:

Internally, Ruby will create an array like this:

Superficially, it appears that the unshift method on the Array class is equivalent to the cons function in Lisp. Both of them add a new element to the beginning or head of a list.
Adding New Elements to a List – Shifting Array Elements
However, arrays and lists are very different things. Arrays are designed for random access of data across a large set, while linked lists instead work well inserting, removing or reordering elements.
Let’s imagine that I want to add a third value to my list – in Lisp I just call “cons” again:

Internally, Lisp just creates a new “cons cell” and sets the pointer to point to the original list:

In Ruby I would just call unshift again:

But remember, in an array there are no pointers and Ruby instead needs to shift all of the existing elements over one position – hence the method name unshift:
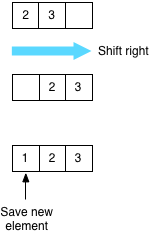
This means that using unshift means you pay a performance penalty every time you add a new element to the head of a list. As you might guess, adding elements to the end of the list is cheaper, since no shifting is necessary – a better way to create a list in Ruby would be to use the push or << method instead:

Adding new elements to the middle of a list works largely the same way as adding a new element to the head of the list. If you call the Array#insert method, Ruby first needs to move the remaining elements to the right to make space for the new value.
Adding More Elements to a List – Resizing Array Capacity
Now suppose I add a fourth element. In Lisp, I could continue to just call the “cons” function, adding more and more elements in precisely the same way. In Ruby, however, notice that my array has filled up and there’s no room for a fourth element:

It turns out that I didn’t choose to show three boxes in my imaginary array diagram just to make the diagram simpler. Internally, Ruby keeps track of two separate values in each array: “size” and “capacity:”
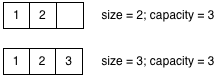
The size indicates the actual size of the array. As I repeatedly called unshift in my example above, the size of the array increased from 1 to 2 to 3.
When Ruby creates an array internally it allocates some extra memory since you are likely to add more elements to the array soon. Whenever you create a new array object, Ruby initially sets the capacity to 3; this means that it can save three values into the array without having to ask for more space. Once you add a fourth element, however, Ruby has to stop and get some new memory from the garbage collection system before saving the fourth value. This might trigger a GC operation if no memory is available.

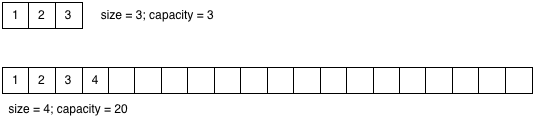
As you add more and more elements, Ruby repeatedly increases the size of the array’s capacity in chunks whenever you cross certain array sizes: 3, 20, 37, 56, 85 elements, etc. The exact thresholds are determined by the ary_double_capa C function inside of array.c. More or less the array capacity increases by 50% each time, although the first increase, from 3 to 20, is a special case. You pay an extra performance penalty each time this happens.
Whenever you remove an element from an array, using shift or pop for example, Ruby may also reduce the capacity of the array along with the size. This means it might stop and free unused memory from the array back to the GC system, causing an additional delay.
The Linked List as a Functional Data Structure
So far, we’ve seen that Ruby arrays can function as linked lists. Ruby provides the push, unshift and insert methods to add a new element to a list, and the pop or shift methods to remove an element from a list. Not only that, with an array you also get direct, random access to all of the elements of the array, which a pure linked list structure can’t offer.
The only downside with using an array as a linked list seems to be performance: if you had many 1000s of elements Ruby would theoretically slow down repeatedly resizing the array to accommodate all of the elements as you added them.
Also, if you needed to add or remove elements to the head of the list or somewhere in the middle, then Ruby would also slow down shifting the remaining elements to the right or left. But remember, since Ruby is implemented with C internally, it is able to use very efficient C functions to move the elements around. Memmove and similar low level C functions are often implemented directly by the microprocessor hardware and work very, very quickly.
However, there’s another important feature of linked lists which isn’t immediately apparent: they work nicely as functional data structures. What does this mean? In functional programming language such as Lisp, you specify your program as a series of “pure functions;” these are bits of code that always return the same output given the same input.
Functional programming languages also discourage the use of “mutable values” – variables or objects that can change from one value to another in place. The primary benefit of using pure functions and immutable values is to allow your software to run more reliably and robustly since your code will have no side effects. Functional languages also work well in multithreaded environments since there’s no need to synchronize or lock code that modifies data – you just don’t modify data at all.
Data structures that exclusively use immutable values are known as “functional data structures.” Aside from the large benefits of robustness and removing the need to synchronize access different threads, functional data structures also allow for data to be easily shared. Since you never modify data in place, it’s easy for many different functional data structures to use the same copy of data internally.
The linked list is a great example of this: different lists can share the same “cons” cells or data values internally. For example, suppose in Lisp I create one list:

And then create a second list by adding another element to the first list:
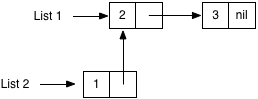
Now I have two linked lists, which share the same cons cells for 2 and 3. As long as you never actually change one of the elements in place, it’s no problem at all for the elements of different linked lists to be shared!
Functional data structures allow you – or language implementors at least – to apply optimizations to share and save memory.
Copy on Write Optimization in Ruby Arrays
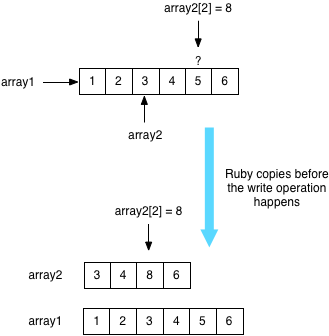
At first glance, it seems that using arrays as lists in Ruby makes space optimization impossible. In the first place, the array in Ruby is not a functional data structure – you can, of course, change any value in an array whenever you want. But let’s suppose, for a moment, that Ruby arrays were immutable – or that there was an “ImmutableArray” object in Ruby. How could two separate arrays even share the same data? For example, suppose I created an array with six elements:
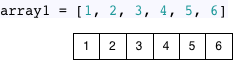
… and a second array as a subset:

In order to use space optimizations similar to Lisp and other functional languages, we would have to imagine that Ruby could share the same copy of the common elements in both arrays:
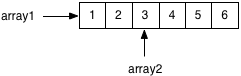
As a matter of fact, it turns out that Ruby does exactly that! Using a series of tricks known as “copy on write optimization,” Ruby shares values across different arrays! Ruby does this by maintaining a single copy of the larger array with all the data values, and creating the second array using a simple pointer or reference to the middle of larger array as shown above.
This is called a “copy on write” optimization because Ruby has to break down the sharing and copy the data elements over when you change or write to one of the values in the shared array.
Practically speaking, you don’t need to worry about this: Ruby will automatically handle everything for you internally, saving you the memory when it can, and paying the price to copy around the data when it must.
However, one simple case related to linked lists that benefits from copy on write optimization is using shift repeatedly to iterate through a list:

As I explained above, theoretically Ruby needs to shift or copy all of the existing elements over to the left whenever you remove an element from the head of a list. For a small array like this one that won’t matter. But if the array contained 1000s of elements, it’s possible this could be a slow operation.
But because of Ruby’s copy on write optimization inside of the Array object, Ruby is smart enough to preserve the original array and to simply move a pointer or reference around as you call shift:
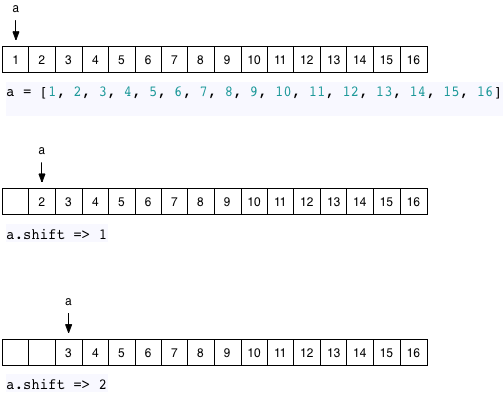
Why did I bother to draw an array with 16 elements in these diagrams? It turns out that when you call shift Ruby doesn’t use this optimization until there are at least 16 elements. If you shift a value off of an array with 15 or fewer elements, then Ruby will just move all the elements to the left, since memmove is so fast with a small array.
Implementing Your Own Linked List
To wrap things up today, let’s take a look at how you would actually implement a linked list in Ruby. As we’ve seen, arrays can often serve quite well as lists. Sometimes, however, you may actually need to repeatedly insert, remove and reorder elements in a large list. To avoid the performance penalties associated with array resizing and shifting, a real linked list might be what you need.
One simple way to create linked list would be to use the Struct object to represent a cons cell, like this:

See this interesting 2012 article for more details on this approach. The author also shows some benchmarks comparing arrays and lists.
Another approach would be to create separate Entry and List objects, as described by Eno Compton his excellent article: Reversing a Linked List in Ruby. Here’s the code:

Finally, if you’re interested in learning more about functional data structures and trying them out in Ruby, see Simon Harris’s Hamster library of immutable data structures implemented in Ruby. Simon also wrote this excellent article in 2010 about how functional programming has caused him to rethink how he writes OO classes: Functional programming in object oriented languages.
Frequently Asked Questions (FAQs) about Ruby’s Missing Data Structure
What is the difference between an Array and a Set in Ruby?
In Ruby, both Array and Set are used to store multiple values. However, they have some key differences. An Array is an ordered collection of objects, meaning that each element has a specific position or index in the Array. On the other hand, a Set is an unordered collection of unique elements. This means that a Set does not keep track of the order of elements and does not allow duplicate values. This makes Sets particularly useful when you need to quickly check if a collection includes a certain element, as Sets can do this much faster than Arrays.
How can I convert an Array to a Set in Ruby?
Converting an Array to a Set in Ruby is quite straightforward. You can use the to_set method provided by the Set class. Here’s an example:require 'set'array = [1, 2, 3, 4, 5]set = array.to_set
In this code, we first require the ‘set’ library. Then we define an Array and convert it to a Set using the to_set method.
Can I use a Set as a key in a Hash in Ruby?
No, you cannot use a Set as a key in a Hash in Ruby. This is because Hash keys in Ruby need to be immutable, meaning they cannot be changed once they are set. However, Sets in Ruby are mutable, meaning you can add, remove, or change elements in a Set. Therefore, Sets cannot be used as Hash keys in Ruby.
How can I add an element to a Set in Ruby?
You can add an element to a Set in Ruby using the add method or the << operator. Here’s an example:set = Set.newset.add("element")# orset << "element"
In this code, we first create a new Set. Then we add an element to the Set using the add method or the << operator.
How can I remove an element from a Set in Ruby?
You can remove an element from a Set in Ruby using the delete method. Here’s an example:set = Set.new(["element"])set.delete("element")
In this code, we first create a new Set with an element. Then we remove the element from the Set using the delete method.
How can I check if a Set includes a certain element in Ruby?
You can check if a Set includes a certain element in Ruby using the include? method. Here’s an example:set = Set.new(["element"])set.include?("element") # returns true
In this code, we first create a new Set with an element. Then we check if the Set includes the element using the include? method.
How can I find the intersection of two Sets in Ruby?
You can find the intersection of two Sets in Ruby using the intersect? method. Here’s an example:set1 = Set.new([1, 2, 3])set2 = Set.new([2, 3, 4])intersection = set1 & set2 # returns Set: {2, 3}
In this code, we first create two Sets. Then we find the intersection of the two Sets using the & operator.
How can I find the union of two Sets in Ruby?
You can find the union of two Sets in Ruby using the union method or the | operator. Here’s an example:set1 = Set.new([1, 2, 3])set2 = Set.new([2, 3, 4])union = set1 | set2 # returns Set: {1, 2, 3, 4}
In this code, we first create two Sets. Then we find the union of the two Sets using the | operator.
How can I find the difference between two Sets in Ruby?
You can find the difference between two Sets in Ruby using the - operator. Here’s an example:set1 = Set.new([1, 2, 3])set2 = Set.new([2, 3, 4])difference = set1 - set2 # returns Set: {1}
In this code, we first create two Sets. Then we find the difference between the two Sets using the - operator.
How can I iterate over a Set in Ruby?
You can iterate over a Set in Ruby using the each method, just like you would with an Array. Here’s an example:set = Set.new([1, 2, 3])set.each do |element|
puts elementend
In this code, we first create a new Set. Then we iterate over the Set using the each method and print each element.