

Okay, before we begin, let me come clean and admit that the title of this article is a little sensationalist! JavaScript doesn’t really have multi-threading capabilities, and there’s nothing a JavaScript programmer can do to change that. In all browsers – apart from Google Chrome – JavaScript runs in a single execution thread, and that’s just how it is.
However, what we can do is simulate multi-threading, insofar that it gives rise to one of the benefits of a multi-threaded environment: it allows us to run extremely intensive code. This is code which would otherwise freeze-up the browser and generate one of those “unresponsive script” warnings in Firefox.
Key Takeaways
- JavaScript does not natively support multi-threading but simulates it through asynchronous timers and Web Workers, allowing intensive computations without freezing the browser.
- Asynchronous timers break down tasks into smaller chunks, preventing the browser from becoming unresponsive by managing how code executes over time.
- Web Workers enhance JavaScript’s capability to perform background tasks without affecting the user interface, though they cannot interact with the DOM or use certain web APIs.
- For complex operations that risk locking up the browser, refactoring code to use asynchronous timers can prevent UI freezes and manage resource-intensive processes more effectively.
- Despite JavaScript’s single-threaded nature, techniques like asynchronous programming and Web Workers provide developers with robust tools to handle multi-threading-like scenarios, improving performance for intensive tasks.
Time Waits for No One
It all hinges on the use of asynchronous timers. When we run repetitive code inside an asynchronous timer, we’re giving the browser’s script interpreter time to process each iteration.
Effectively, a piece of code inside a for iterator is asking the interpreter to do everything straight away: “run this code n times as fast as possible.” However the same code inside an asynchronous timer is breaking the code up into small, discreet chunks; that is, “run this code once as fast possible,” – then wait – then “run this code once as fast as possible”, and so on, n times.
The trick is that the code inside each iteration is small and simple enough for the interpreter to process it completely within the speed of the timer, be it 100 or 5,000 milliseconds. If that requirement is met, then it doesn’t matter how intense the overall code is, because we’re not asking for it to be run all at once.
How Intense is “Too Intense”?
Normally, if I were writing a script that proved to be too intensive, I would look at re-engineering it; such a significant slowdown usually indicates a problem with the code, or a deeper problem with the design of an application.
But sometimes it doesn’t. Sometimes there’s simply no way to avoid the intensity of a particular operation, short of not doing it in JavaScript at all.
That might be the best solution in a given case; perhaps some processing in an application needs to be moved to the server-side, where it has more processing power to work with, generally, and a genuinely threaded execution environment (a web server).
But eventually you may find a situation where that’s just not an option – where JavaScript simply must be able to do something, or be damned. That’s the situation I found myself in when developing my Firefox extension, Dust-Me Selectors.
The core of that extension is the ability to test CSS selectors that apply to a page, to see if they’re actually being used. The essence of this is a set of evaluations using the matchAll() method from Dean Edwards‘ base2:
for(var i=0; i<selectors.length; i++)
{
if(base2.DOM.Document.matchAll
(contentdoc, selectors[i]).length > 0)
{
used ++;
}
else
{
unused ++;
}
}Straightforward enough, for sure. But matchAll() itself is pretty intense, having – as it does – to parse and evaluate any CSS1 or CSS2 selector, then walk the entire DOM tree looking for matches; and the extension does that for each individual selector, of which there may be several thousand. That process, on the surface so simple, could be so intensive that the whole browser freezes while it’s happening. And this is what we find.
Locking up the browser is obviously not an option, so if this is to work at all, we must find a way of making it run without error.
A Simple Test Case
Let’s demonstrate the problem with a simple test case involving two levels of iteration; the inner level is deliberately too intensive so we can create the race conditions, while the outer level is fairly short so that it simulates the main code. This is what we have:
function process()
{
var above = 0, below = 0;
for(var i=0; i<200000; i++)
{
if(Math.random() * 2 > 1)
{
above ++;
}
else
{
below ++;
}
}
}
function test1()
{
var result1 = document.getElementById('result1');
var start = new Date().getTime();
for(var i=0; i<200; i++)
{
result1.value = 'time=' +
(new Date().getTime() - start) + ' [i=' + i + ']';
process();
}
result1.value = 'time=' +
(new Date().getTime() - start) + ' [done]';
}We kick off our test, and get our output, from a simple form (this is test code, not production, so forgive me for resorting to using inline event handlers):
<form action="">
<fieldset>
<input type="button" value="test1" onclick="test1()" />
<input type="text" id="result1" />
</fieldset>
</form>
Now let’s run that code in Firefox (in this case, Firefox 3 on a 2GHz MacBook) … and as expected, the browser UI freezes while it’s running (making it impossible, for example, to press refresh and abandon the process). After about 90 iterations, Firefox produces an “unresponsive script” warning dialog.
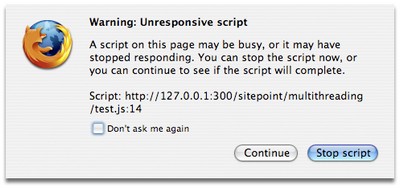
If we allow it to continue, after another 90 iterations Firefox produces the same dialog again.
Safari 3 and Internet Explorer 6 behave similarly in this respect, with a frozen UI and a threshold at which a warning dialog is produced. In Opera there is no such dialog – it just continues to run the code until it’s done – but the browser UI is similarly frozen until the task is complete.
Clearly we can’t run code like that in practice. So let’s re-factor it and use an asynchronous timer for the outer loop:
function test2()
{
var result2 = document.getElementById('result2');
var start = new Date().getTime();
var i = 0, limit = 200, busy = false;
var processor = setInterval(function()
{
if(!busy)
{
busy = true;
result2.value = 'time=' +
(new Date().getTime() - start) + ' [i=' + i + ']';
process();
if(++i == limit)
{
clearInterval(processor);
result2.value = 'time=' +
(new Date().getTime() - start) + ' [done]';
}
busy = false;
}
}, 100);
}Now let’s run it in again … and this time we receive completely different results. The code takes a while to complete, sure, but it runs successfully all the way to the end, without the UI freezing and without warnings about excessively slow scripting.
(The busy flag is used to prevent timer instances from colliding. If we’re already in the middle of a sub-process when the next iteration comes around, we simply just wait for the following iteration, thereby ensuring that only one sub-process is running at a time.)
So you see, although the work we can do on the inner process is still minimal, the number of times we can run that process is now unlimited: we can run the outer loop basically forever, and the browser will never freeze.
That’s much more like it – we can use this in the wild.
You’re Crazy!
I can hear the objectors already. In fact, I could be one myself: why would you do this – what kind of crazy person insists on pushing JavaScript to all these places it was never designed to go? Your code is just too intense. This is the wrong tool for the job. If you have to jump through these kinds of hoops then the design of your application is fundamentally wrong.
I’ve already mentioned one example where I had to find a way for heavy scripting to work; it was either that, or the whole idea had to be abandoned. If you’re not convinced by that answer, then the rest of the article may not appeal to you either.
But if you are – or at least, if you’re open to being convinced, here’s another example that really nails it home: using JavaScript to write games where you can play against the computer.
Game on
What I’m talking about here is the code required to understand the rules of a game, which can then evaluate situations and tactics in order to try to beat you at that game. Complicated stuff.
To illustrate, I’m going to look at a project I’ve been developing on the side for a little while. By “little while” I mean three years, the majority of which was spent at a plateau where the game theoretically worked, but was too intense to use … until I thought of this approach. The game is a competitive puzzle based around color- and shape-matching.

To summarize: you make your way across the board by adjacent shape- and color-matching. For example, if you start on, say, a green triangle – then you can move to any other triangle, or any other green shape. Your objective is to reach the crystal in the middle, then take it to the other side of the board, while your opponent tries to do the same. You can also steal the crystal from your opponent.
So, we have logical rules determining movement and we can also see tactics emerging. For example, to avoid having your opponent reach the crystal, or stealing it from you – you might select a move that blocks them, or try to finish at a place they can’t reach.
The work of the computer is to find the best move for any given situation, so let’s have a look at that process in summary pseudo-code:
function compute()
{
var move = null;
move = tactic1();
if(!move) { move = tactic2(); }
if(!move) { move = tactic3(); }
if(move)
{
doit();
}
else
{
pass();
}
}We evaluate a tactic, and if that gives us a good move then we’re done; otherwise we evaluate another tactic, and so on, until we either have a move, or conclude that there isn’t one and we have to pass.
Each of those tactic functions runs an expensive process, as it has to evaluate every position on the board, as well as potential future positions, possibly many times each in light of various factors. The example only has three tactics, but in the real game there are dozens of different possibilities, each one expensive to evaluate.
Any one of those evaluations individually is fine, but all of them together, run consecutively, make for an overly intense process that freezes the browser.
So what I did was split the main code into discreet tasks, each of which is selected with a switch statement, and iterated over using an asynchronous timer. The logic of this is not a million miles away from those Choose Your Own Adventure books I used to have as a kid, where each task concludes with a choice of further tasks, all in real time, until we reach the end:
function compute()
{
var move = null;
var busy = false, task = 'init';
var processor = setInterval(function()
{
if(!busy)
{
switch(task)
{
case 'init' :
move = tactic1();
if(move) { task = 'doit'; }
else { task = 'tactic2'; }
busy = false;
break;
case 'tactic2' :
move = tactic2();
if(move) { task = 'doit'; }
else { task = 'tactic3'; }
busy = false;
break;
case 'tactic3' :
move = tactic3();
if(move) { task = 'doit'; }
else { task = 'pass'; }
busy = false;
break;
case 'doit' :
doit();
task = 'final';
busy = false;
break;
case 'pass' :
pass();
task = 'final';
busy = false;
break;
case 'final' :
clearInterval(processor);
busy = false;
break;
}
}
}, 100);
}This code is significantly more verbose than the original, so if reducing code size were the only imperative, this would clearly not be the way to go.
But what we’re trying to do here is create an execution environment with no ceiling, that is, a process that doesn’t have an upper limit in terms of complexity and length; and that’s what we’ve done.
This pattern can be extended indefinitely, with hundreds or even thousands of tasks. It might take a long time to run, but run it will, and as long as each individual task is not too intense, it will run without killing the browser.
A Path of No Return
The strength of this approach is also its major weakness: since the inner function is asynchronous, we cannot return a value from the outer function. So, for example, we cannot do this (or rather, we can, but there would be no point):
function checksomething()
{
var okay = false;
var i = 0, limit = 100, busy = false;
var processor = setInterval(function()
{
if(!busy)
{
busy = true;
if(condition)
{
okay = true;
}
if(++i == limit)
{
clearInterval(processor);
}
busy = false;
}
}, 100);
return okay;
}That checksomething() function will always return false because the inner function is asynchronous. The outer function will return before the first iteration of the inner function has even happened!
This next example is similarly pointless:
if(++i == limit)
{
clearInterval(processor);
return okay;
}We’re out of the scope of the outer function, therefore we’re unable to return from it; that return value disappears uselessly into the ether.
What we can do here is take a leaf out of Ajax coding techniques, and use a callback function (which in this example I’m calling “oncomplete”):
function checksomething(oncomplete)
{
var okay = false;
var i = 0, limit = 100, busy = false;
var processor = setInterval(function()
{
if(!busy)
{
busy = true;
if(condition)
{
okay = true;
}
if(++i == limit)
{
clearInterval(processor);
if(typeof oncomplete == 'function')
{
oncomplete(okay);
}
}
busy = false;
}
}, 100);
}So when we call checksomething(), we pass an anonymous function as its argument, and that function is called with the final value when the job is complete:
checksomething(function(result)
{
alert(result);
});Elegant? No. But robustly functional? Yes. And that’s the point. Using this technique, we can write scripts that would otherwise be impossible.
Do Androids Dream of Silicon Sheep?
With this technique in our kit, we now have a means for tackling JavaScript projects that were previously way out of the realm of possibility. The game I developed this pattern for has fairly simple logic, and hence a fairly simple brain, but it was still too much for conventional iteration; and there are plenty of other games out there that need a good deal more clout!
My next plan is to use this technique to implement a JavaScript Chess engine. Chess has a huge range of possible scenarios and tactics, leading to decisions that could take an extremely long time to calculate, far longer than would have been feasible without this technique. Intense computation is required to create even the most basic thinking machine, and I confess to being quite excited about the possibilities.
If we can pull off tricks like this, who’s to say what’s possible? Natural language processing, heuristics … perhaps we have the building blocks to develop Artificial Intelligence in JavaScript!
If you enjoyed reading this post, you’ll love Learnable; the place to learn fresh skills and techniques from the masters. Members get instant access to all of SitePoint’s ebooks and interactive online courses, like JavaScript Programming for the Web.
Comments on this article are closed. Have a question about JavaScript? Why not ask it on our forums?
Image credit: Randen L Peterson
Frequently Asked Questions on Multithreading in JavaScript
What is the Role of Web Workers in JavaScript Multithreading?
Web Workers play a crucial role in JavaScript multithreading. They are a simple means for web content to run scripts in background threads. The worker thread can perform tasks without interfering with the user interface. In addition, they can perform I/O using XMLHttpRequest (although the responseXML and channel attributes are always null). Once created, a worker can send messages to the JavaScript code that created it by posting messages to an event handler specified by that code (and vice versa).
How Does JavaScript Handle Multithreading Despite Being Single-Threaded?
JavaScript is inherently single-threaded, but it can handle multithreading through the use of asynchronous callbacks and promises. This means that while JavaScript itself operates on a single thread, it can schedule tasks to be executed in the future, effectively allowing it to perform multiple tasks concurrently. This is particularly useful for handling operations like user input or API requests, which can be processed in the background while the main thread continues to execute other code.
What are the Limitations of Multithreading in JavaScript?
While multithreading in JavaScript can be achieved through Web Workers, it’s important to note that these workers do not have access to the DOM or other web APIs. They are limited to only a few data types they can send back and forth to the main thread. Also, each worker is a separate instance, so they don’t share scope or any global variables.
How Can I Implement Multithreading in Node.js?
Node.js has a built-in module called ‘cluster’ that allows you to create child processes (workers), which share server ports with the main Node process (master). These child processes can run simultaneously and work on different tasks, effectively implementing multithreading.
Why Doesn’t JavaScript Support Multithreading Natively?
JavaScript was designed to be single-threaded to avoid complexity and potential issues with data manipulation. Multithreading can lead to problems such as race conditions, where the output is dependent on the sequence or timing of other uncontrollable events. It was thought that it would be easier to optimize a single-threaded environment, as there would be no need to deal with dependencies between threads.
How Can I Use Web Workers for Multithreading in JavaScript?
To use Web Workers for multithreading in JavaScript, you need to create a new Worker object and specify a JavaScript file to be executed in the worker thread. You can then communicate with the worker thread using the postMessage method and receive messages from it using the onmessage event handler.
Can Multithreading Make My JavaScript Code Faster?
Multithreading can potentially make your JavaScript code faster, but it depends on the nature of the tasks being performed. For CPU-intensive tasks, multithreading can significantly improve performance by allowing tasks to be performed in parallel. However, for I/O-bound tasks, the benefits of multithreading are less pronounced, as these tasks are often limited by factors outside the CPU’s control, such as network speed.
What is the Difference Between Multithreading and Asynchronous Programming in JavaScript?
Multithreading and asynchronous programming are both techniques used to manage multiple tasks at the same time. However, they do it in different ways. Multithreading involves multiple threads of execution, with each thread performing a different task. Asynchronous programming, on the other hand, involves a single thread of execution, but tasks can be started and then put on hold to be completed later, allowing other tasks to be performed in the meantime.
How Can I Handle Data Sharing Between Threads in JavaScript?
Data sharing between threads in JavaScript can be achieved using SharedArrayBuffer and Atomics. SharedArrayBuffer allows sharing memory between the main thread and worker threads, while Atomics provides methods to perform safe atomic operations on shared memory.
Can I Use Multithreading in JavaScript for Front-End Development?
Yes, you can use multithreading in JavaScript for front-end development. However, it’s important to note that Web Workers, which enable multithreading, do not have access to the DOM or other web APIs. Therefore, they are typically used for tasks that don’t involve manipulating the DOM or interacting with the web page, such as performing calculations or handling data.