
Database Versioning with DBV

Key Takeaways
- DBV is a PHP-based database version control system for MySQL databases. It is not standalone and requires a version control system such as Git, Mercurial, or SVN for syncing changes with your team.
- DBV allows developers to track changes made to a database, share these changes with team members, and ensure everyone is working with the latest copy of the database. It can track changes like new tables, renamed or dropped tables, new or updated fields, new or updated table rows, and more.
- The DBV workflow involves creating a local copy of the database, making changes, exporting these changes to disk, committing them into source control, and pushing them to a central repository. Team members can then pull these changes to their local copy.
- DBV also supports revisions, allowing developers to modify the structure of more than one table. However, it is good practice to make changes to a single table and make a revision for it, unless the changes are related to each other.
It’s good practice to always use a version control system in any of your projects. Be it a side-project in which you are the only developer, or a team project where five or more people are working on it together. But the idea of putting your database into version control isn’t really that widespread. Often times we take the database for granted.
But like the source files in our project, the database is constantly changing too. That’s why we also need a way to track the changes that we have made and easily share it to other members of our team.
In this article we will take a look at DBV, a database version control system written in PHP for MySQL databases so you need to have PHP and MySQL installed before you can use it, along with a web server like Apache or Nginx.
An important note about this software is that it is not a stand-alone database version control system, because it needs a version control system such as Git, Mercurial or SVN for syncing changes with your team.
Installing DBV
To start working with DBV, first you have to download the installer from their website, extract it into your project directory then rename the resulting folder to dbv. This will give you the following path:
my_project/dbvAn alternative approach is just cloning from Github.
DBV Configuration
You can start configuring the options for DBV by creating a copy of the config.php.sample file and renaming it to config.php.
The most important things to update here are the first two sections. Just substitute the values for my_username, my_password, my_database for the values in your current database configuration:
<?php
/**
* Your database authentication information goes here
* @see http://dbv.vizuina.com/documentation/
*/
define('DB_HOST', 'localhost');
define('DB_PORT', 3306);
define('DB_USERNAME', 'my_username');
define('DB_PASSWORD', 'my_password');
define('DB_NAME', 'my_database');
/**
* Authentication data for access to DBV itself
* If you leave any of the two constants below blank, authentication will be disabled
* @see http://dbv.vizuina.com/documentation/#optional-settings
*/
define('DBV_USERNAME', 'my_username');
define('DBV_PASSWORD', 'my_password');
?>The first section in the configuration file above is all about the MySQL database details in your machine.
The second section are the login details for dbv itself.
Next open up the .gitignore file. By default it contains the following:
config.php
.buildpath
.project
.settingsThese are the files that will be ignored by Git. But if you know that you have the same database information (user, password, database name) as your team mates then you can remove config.php from the .gitignore file. If not then they will have to create their own configuration file and exclude it from source control.
Next you also have to add the data/meta/revision file to .gitignore as that is where dbv puts information about your local copy of the database. It might be different for your team mates so it needs to be excluded from source control.
Once you’re done with the configuration you can now add dbv into version control:
git add dbv
git commit -m "add dbv into project"And then push it to your central repository for the other members of your team to pull:
git pushWhat Changes To Keep Track Of?
Before we move on into actually using dbv. I’d like to touch a bit on which changes to keep track of. In the database world pretty much any change can be put into source control. This includes the following:
- new tables
- renamed tables
- dropped tables
- new fields
- updated field
- deleted field
- new table row (default table data)
- updated table row
- deleted table row
- views
- stored procedures
- triggers
- functions (user-defined functions)
DBV Workflow
You can fire up dbv from your browser by accessing the following URL:
http://localhost/your_project/dbvOr if you defined a virtual host, by accessing its URL.
This will give you an interface similar to the following:
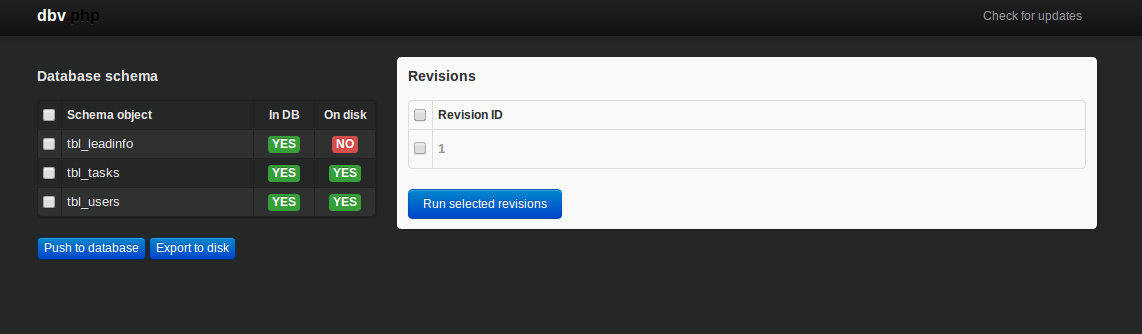
From the screenshot above you will see the tables that are currently in the database that you supplied in the config.php earlier. There’s also an In DB field that displays whether a specific table is currently in the database and the On disk which displays whether the current table is saved in your filesystem. With this information you’re pretty much aware whether you currently have the latest copy of the database.
An important thing to remember when working with dbv is that any changes you make to your local copy of your database should have a local copy that you can commit into your source control.
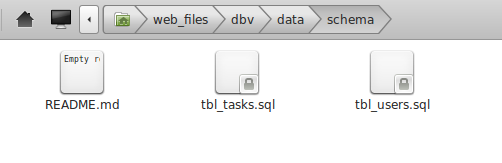
That means that if you create a new table in the database you have to export it to disk. All the tables that are exported to disk are saved in the data/schema directory of your dbv installation. You can see from the screenshot below that we currently do not have the tbl_leadinfo table in our filesystem:
After exporting the newly created table to disk you have to commit it into version control:
git add data/schema/tbl_tasks.sql
git commit -m "add tbl_task table"Then you can just push it to your central repository:
git pushAt this point you can just tell to your team mates that you have created a new table in the database and that you have already pushed it to the central repo. Now they can just pull it down to their local copy.
git pullNext tell your team mate to visit the dbv page (http://localhost/your_project/dbv).
Your team mate will probably have a screen similar to the following:
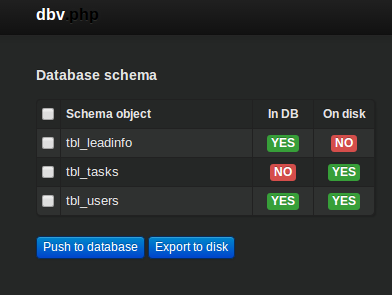
At this point he can just tick the checkbox next to the tbl_tasks table and click on the ‘Push to database’ button. This will create the tbl_tasks table in the database.
And that’s the workflow for working with dbv. Pretty easy, isn’t it? But what if you need to make changes to the current database schema? Maybe you missed a field or forgot to add it on a specific table before you distributed it to your team. That’s where revisions come in.
Revisions
If you’re like me and you tried updating the schema (added a new field, remove a field, updated the data type, etc.) for a specific table you might have noticed that dbv isn’t aware of it by default. For those changes you need to create a revision file. You can do that by creating a new folder in the data/revisions directory in your dbv installation. The convention for naming the folder is making use of a number. So the first time you make a revision the folder name would be 1 and then the next time it would be 2 and so on. Note that revisions are changes that can be applied to the whole database. This means that you have the freedom to modify the structure of more than one table, but its good practice to only make changes to a single table and make a revision for it. This is for you and your team to easily manage the changes and make sense of it later on. The only exception to this practice is when the changes are related to each other. In that case it would make sense to put those changes together in one revision.
Let’s try creating a new field inside the tbl_users table and name it email:
ALTER TABLE `tbl_users`
ADD `email` varchar(160) COLLATE 'latin1_swedish_ci' NOT NULLNext create a new file in the data/revisions/1 directory in your dbv installation and put the query that you just executed as the contents. Name the file tbl_users.sql. The convention here is using the name of the modified table as the name for the revision file.
If you are making modifications to more than one table then create a separate file for each table.
After that you can commit the new file into your source control:
git add data/revisions/1/tbl_users.sql
git commit -m "add email field to tbl_users"And then push it to your central repository:
git pushAgain you can inform your team mates about the particular change. Communication is key when making changes to the database. You want to make sure that everyone on your team is on the same page as you.
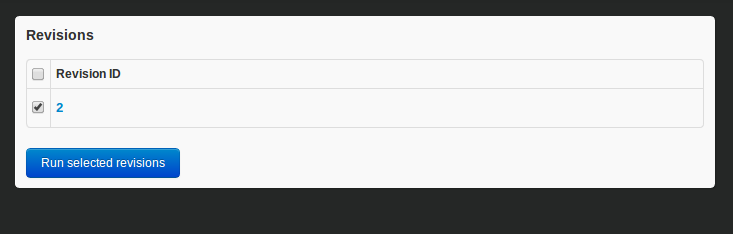
Now if they access dbv from the browser they can now see the revision. All they have to do now is to tick the checkbox beside the revision and then click on the ‘Run selected revisions’ button. This will commit your changes to their local database copy:
Conclusion
DBV is a nice way to easily manage your database version control needs. It lets you and your team easily keep track of the changes made in your database. It also allows for easy sharing of your changes with the rest of your team through the use of Git. This ensures that everyone always has the latest copy of the database.
In this article we have looked at using DBV with Git but you can pretty much use any version control system of your choice. Feedback? Please leave it in the comments below!
Frequently Asked Questions on Database Versioning
What are the key benefits of database versioning?
Database versioning offers several benefits. Firstly, it provides a historical record of all changes made to the database schema, which can be useful for debugging and auditing purposes. Secondly, it allows for easy rollback of changes in case of errors or issues. Thirdly, it facilitates collaboration among team members by ensuring everyone is working with the same version of the database. Lastly, it helps in maintaining consistency and integrity of the database, especially in a distributed development environment.
How does database versioning work in practice?
In practice, database versioning involves maintaining a version history of the database schema. This is typically done using a version control system like Git. Each change to the database schema is committed as a new version in the version control system. These versions are then used to update the database schema in different environments (development, testing, production, etc.) as needed.
What tools can be used for database versioning?
There are several tools available for database versioning. Some of the popular ones include Liquibase, Flyway, and DBmaestro. These tools provide features like automated schema updates, rollback capabilities, and support for multiple database types. The choice of tool depends on the specific requirements and preferences of the development team.
What are the challenges in implementing database versioning?
Implementing database versioning can be challenging due to several reasons. Firstly, it requires a change in the development process, which can be difficult to manage. Secondly, it requires careful handling of database migrations to avoid data loss or corruption. Lastly, it requires a good understanding of the database schema and the changes being made to it.
How can database versioning help in agile development?
In agile development, changes are made frequently and rapidly. Database versioning can help manage these changes effectively by providing a historical record of all changes, facilitating easy rollback of changes, and ensuring consistency across different environments. This can greatly enhance the agility and efficiency of the development process.
How does database versioning relate to DevOps?
Database versioning is a key component of DevOps, as it enables continuous integration and continuous deployment (CI/CD) of database changes. By maintaining a version history of the database schema, it allows for automated deployment of changes across different environments, thereby enhancing the speed and efficiency of the DevOps process.
Can database versioning be used with cloud databases?
Yes, database versioning can be used with cloud databases. Most database versioning tools support a wide range of database types, including cloud databases. However, the specific features and capabilities may vary depending on the tool and the type of cloud database.
What is the role of database versioning in data governance?
Database versioning plays a crucial role in data governance by ensuring the integrity and consistency of the database schema. It provides a historical record of all changes, which can be useful for auditing and compliance purposes. It also facilitates collaboration and communication among team members, which is essential for effective data governance.
How can database versioning improve database performance?
While database versioning itself does not directly improve database performance, it can help identify performance issues by providing a historical record of schema changes. This can be useful for debugging and performance tuning. Moreover, by ensuring consistency and integrity of the database schema, it can indirectly contribute to better database performance.
What are the best practices for database versioning?
Some of the best practices for database versioning include: using a version control system to maintain a version history of the database schema; committing each change as a new version; testing each version thoroughly before deployment; using automated tools for schema updates and rollbacks; and maintaining good communication and collaboration among team members.
Wern is a web developer from the Philippines. He loves building things for the web and sharing the things he has learned by writing in his blog. When he's not coding or learning something new, he enjoys watching anime and playing video games.


Published in
·Cloud·Databases·Debugging & Deployment·Development Environment·PHP·Programming·Web·February 24, 2014
Published in
·Cloud·CMS·Databases·Debugging & Deployment·Development Environment·PHP·Programming·Web·March 12, 2014
