Elixir is a modern, dynamic, functional programming language used to build highly distributed and fault-tolerant applications. Ecto is its main library for working with databases, providing us with tools to interact with databases under a common API, version the database alongside our application, and handle data processing within our application.
This article takes a quick look at the major aspects of the Ecto library. Whilst it is written for Ecto 1.x, the examples in this article are forwards compatible with Ecto 2, and where discrepancies lie, they are mentioned. Basic knowledge of Elixir and Mix are assumed.
The Application
We’ll be building a very simple application from scratch that will store and retrieve notes for us. By doing this, we’ll look through each of Ecto’s four main components: repos, schemas, changesets, and queries.
Creating a new application
Let’s start by generating a new Mix application:
mix new notex --sup
The --sup flag generates some additional boilerplate code that’s required for an OTP application. This application needs to have a supervision tree, because Ecto needs it (more on this in a minute).
Setting up the dependencies
Now, let’s update our mix.exs file with some application dependencies. For this, we’re going to want to specify Ecto and one of its adapters. I’ve chosen to use MySQL for this, so we’ll need to specify the Mariaex library (Ecto supports a number of databases).
Update the application/0 function in the mix.exs file with the following:
def application do
[applications: [:logger, :ecto, :mariaex],
mod: {Notex, []}]
end
And update deps/0 with the following:
defp deps do
[{:ecto, "~> 1.1.5"}, # or "~> 2.0" for Ecto 2
{:mariaex, "~> 0.6.0"}] # or "~> 0.7.0" for Ecto 2
end
Now fetch the dependencies with mix deps.get.
Next, we need to integrate these dependencies into our application. This will involve creating a new wrapper module for an Ecto repository, updating our application’s supervision tree to start and supervise that new module, and configuring the adapter’s connection information.
Let’s firstly start by defining a Notex.Repo module at lib/notex/repo.ex with the following code:
defmodule Notex.Repo do
use Ecto.Repo, otp_app: :notex
end
The location of this module (lib/app_name/repo.ex) is conventional. Any time we use a mix ecto command, it will default to looking for the defined repository at AppName.Repo. We can place it elsewhere, but it will be at the inconvenience of having to specify its location using the -r (or --repo) flag.
The above Notex.Repo module enables us to work with databases using Ecto. It does this by firstly injecting functions from Ecto’s Repo module (that provide the database querying API) and by secondly naming our OTP application as :notex.
An Ecto repository provides us with a common interface to interact with an underlying database (which is decided upon by the adapter being used). As such, whilst Ecto uses the terminology repo, it does not follow the repository design pattern, since it’s a wrapper around a database, not a table.
Now that we have defined the Notex.Repo module, we must now add this to our supervision tree in the Notex module (at lib/notex.ex). Update the start/2 function with the following:
def start(_type, _args) do
import Supervisor.Spec, warn: false
children = [
supervisor(Notex.Repo, []),
]
opts = [strategy: :one_for_one, name: Notex.Supervisor]
Supervisor.start_link(children, opts)
end
We’ve added the Notex.Repo module as a child supervisor (since it is itself a supervising OTP app). This means that it will be supervised by our OTP application, and our application will be responsible for starting it upon application startup.
Each connection created with Ecto uses a separate process (where the process is pulled from a process pool using a library called Poolboy). This is done so that our queries can execute concurrently, as well as being resilient from failures (e.g. timeouts). Our application therefore requires OTP, because Ecto has its own processes that need supervising (including a supervision tree supervising a pool of database connections). This can be seen using Erlang’s Observer library, which enables us to visualize the processes in an application.
After having added the repo to our worker processes to be supervised, we need to lastly configure the adapter so that it can communicate with our database. Place the following code at the end of the `config/config.exs` file (updating the details as necessary):config :notex, Notex.Repo,
adapter: Ecto.Adapters.MySQL,
database: "notex",
username: "root",
password: "root",
hostname: "localhost"
# uncomment the following line if Ecto 2 is being used
# config :notex, ecto_repos: [Notex.Repo]
:notex) and the name of our freshly defined module (Notex.Repo) for enabling communication with the database. The other configure options should be pretty self-explanatory. Ecto 2 requires us to additionally specify a list of the Ecto repos we are using in our application.
Ecto actually provides us with a shortcut for setting up the above Repo module as a mix task: mix ecto.gen.repo. This generates the repository module for us and updates the config.exs file with some basic configuration (the Repo module still needs to be manually added to the supervision tree though). I avoided using it here predominantly for didactic reasons of showing how to set up Ecto manually (that, and the fact that the repo generator assumes you’re using Postgres, so we would have had to update the adapter in the config anyway).
Before moving on, let’s take a very quick look at the process hierarchy. (Note that if you’re running Ecto 2, you will firstly need to create the database with mix ecto.create before attempting to compile the project.) Start up our application in Elixir’s interactive shell and then start the observer:
iex -S mix
iex(1)> :observer.start
:ok
Navigating to the Application tab, we can see the application’s processes, including which ones are the supervisors:
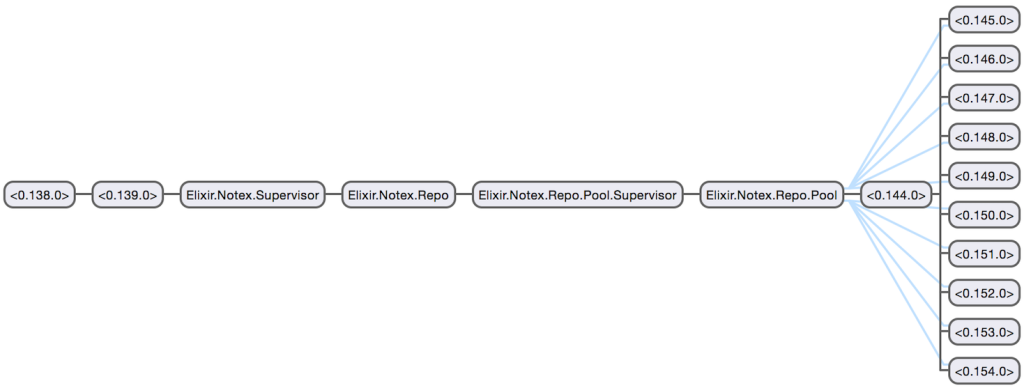
So that’s why this application needs to be an OTP app. But that’s as far down the rabbit hole we’ll be going with respect to processes and OTP in this article. They will be covered in greater detail in later articles to come.
Creating the database and tables
Now with that setup, we can create our database and tables. To create the database, run the following command:
mix ecto.create
To create the tables, we’ll use Ecto’s migrations feature. Migrations enable us to version the database alongside the source code, enabling changes to be tracked and different states to be applied. We therefore create new migrations whenever we’d like to change the structure of the database.
A new migration can be created with the mix ecto.gen.migration command as follows:
mix ecto.gen.migration create_notes_table
The above should create a new migrations folder at priv/repo/migrations, as well as a new migration file. This file is prefixed with the date and time created (for easy directory ordering), along with our migration name. Open up that file and modify it to the following:
defmodule Notex.Repo.Migrations.CreateNotesTable do
use Ecto.Migration
def change do
create table(:notes) do
add :note_name, :string
add :note_content, :string
end
end
end
Keeping things simple, we used the create macro to define a new table (called notes) with two fields: note_name and note_content. The primary key is automatically created for us (named id). Whilst both of our fields were defined as simple strings, Ecto supports many types — which you can check out in its documentation.
With our migration complete, we can now run the migration with the following command:
mix ecto.migrate
This will create our notes table with 3 fields (the third field being id, the primary key).
With the table created, it’s now time to create a model for the table. The model is used to define the fields of the table and their respective types. These will be used by the application and Ecto’s querying DSL when casting and validating the data. Model definitions may also contain virtual fields (unlike migration definitions), which are used to hold typically ephemeral data that we don’t want to persist (such as unhashed passwords).
In its most basic form, our Notex.Note model (located at lib/notex/note.ex) will look like the following:
defmodule Notex.Note do
use Ecto.Schema
schema "notes" do
field :note_name, :string
field :note_content, :string
end
end
We inject the Ecto.Schema module so that we can use the schema macro to define the fields and their types. These definitions will become important later on when we used Ecto’s changesets. Something else the schema macro does for us is define a struct of the type as the current module (in this case, it’s %Notex.Note{}). This struct will enable us to create new changesets (more on this soon) and insert data into the table.
With just the above, we can fire up IEx and begin querying our database:
iex(1)> import Ecto.Query
nil
iex(2)> Notex.Repo.all(from n in Notex.Note, select: n.note_name)
[]
(Console debugging information redacted.)
Ecto’s Query module is imported to make all of the querying DSL macros (such as from) available to us in the shell. We then create a simple query to return all records (using all/1), selecting only the note_name field. This returns back an empty list, since we currently have no records in the database. Let’s create a new changeset and insert it into the table:
iex(1)> import Ecto.Query
nil
iex(2)> changeset = Ecto.Changeset.change(%Notex.Note{note_name: "To Do List", note_content: "Finish this article"})
%Ecto.Changeset{action: nil, changes: %{}, constraints: [], errors: [],
filters: %{},
model: %Notex.Note{__meta__: #Ecto.Schema.Metadata<:built>, id: nil,
note_content: "Finish this article", note_name: "To Do List"}, optional: [], opts: [],
params: nil, prepare: [], repo: nil, required: [],
types: %{id: :id, note_content: :string, note_name: :string}, valid?: true,
validations: []}
iex(3)> Notex.Repo.insert(changeset)
{:ok,
%Notex.Note{__meta__: #Ecto.Schema.Metadata<:loaded>, id: 2,
note_content: "Finish this article", note_name: "To Do List"}}
iex(4)> Notex.Repo.all(from n in Notex.Note, select: n.note_name)
["To Do List"]
(Console debugging information redacted.)
We start by importing Ecto.Query again, which is needed for the last fetch operation (specifically for the from macro). We then use the change/1 function from Ecto.Changeset to create a new changeset using a %Notex.Note{} struct. This changeset is then inserted, and then retrieved.
Changesets are what we use when working with records. They enable us to track changes to the data prior to insertion, as well as validating those changes and casting their values to the correct data types (according to our schema definition). As we can see from the above, the %Ecto.Changeset{} struct contains a number of members that will be useful for seeing if the changes are valid (changeset.valid?), what the errors are if they weren’t (changeset.errors), and so on.
Let’s update the Notex.Note model to demonstrate some changesets and query operations, since performing these in IEx is getting a little messy:
defmodule Notex.Note do
use Ecto.Schema
import Ecto.Changeset, only: [cast: 4]
import Ecto.Query, only: [from: 2]
alias Notex.Note
alias Notex.Repo
schema "notes" do
field :note_name, :string
field :note_content, :string
end
@required_fields ~w(note_name)
@optional_fields ~w(note_content)
def insert_note(%{} = note) do
%Note{}
|> cast(note, @required_fields, @optional_fields)
|> Repo.insert!
end
def get_notes do
query = from n in Note,
select: {n.id, n.note_name}
query
|> Repo.all
end
def get_note(note_id) do
Repo.get!(Note, note_id)
end
def update_note(%{"id" => note_id} = note_changes) do
Repo.get!(Note, note_id)
|> cast(note_changes, @required_fields, @optional_fields)
|> Repo.update!
end
def delete_note(note_id) do
Repo.get!(Note, note_id)
|> Repo.delete!
end
end
Let’s go through each of the five new functions. The insert_note/1 function creates a new note for us. The cast/4 function handles the casting of data from the input fields to their respective field types (according to our schema definition), as well as ensuring that all required fields have values. The changeset returned from cast/4 is then inserted into the database. Note that in Ecto 2, the cast/3 and validate_required/3 functions should be used instead of cast/4.
The get_notes/0 function returns a list of tuples of all notes in the table. This is done through pattern matching in the select statement. (We could quite easily have returned a list of maps instead with select: %{id: n.id, note_name: n.note_name}, for example.)
The get_note/1 function retrieves a single note from the table according to the note ID. This is done via the get! function, which either returns the note upon success or throws upon failure.
The update_note/1 function updates a note according to the supplied note ID. Notice the string key in the map of the function signature (the id key). This is a convention I’ve taken from the Phoenix framework, where unsanitized data (typically user-supplied) is represented in maps with string keys, and sanitized data is represented in maps with atom keys. To perform the update, we first retrieve the note according to its ID from the database, then use the cast/4 function to apply the changes to the record before finally inserting the updated changeset back into the database.
The delete_note/1 function removes a note from the database. We firstly fetch the note from the database via its ID (similar to the update_note/1 function), and then delete it using the returned Note struct.
With the above CRUD operations in place, let’s jump back into IEx and try it out:
iex(1)> alias Notex.Note
nil
iex(2)> Note.insert_note(%{"note_name" => "To Do's", "note_content" => "Finish this article..."})
{:ok,
%Notex.Note{__meta__: #Ecto.Schema.Metadata<:loaded>, id: 6,
note_content: "Finish this article...", note_name: "To Do's"}}
iex(3)> Note.get_notes
[{6, "To Do's"}]
iex(4)> Note.get_note(6)
%Notex.Note{__meta__: #Ecto.Schema.Metadata<:loaded>, id: 6,
note_content: "Finish this article...", note_name: "To Do's"}
iex(5)> Note.update_note(%{"id" => 6, "note_name" => "My To Do List"})
{:ok,
%Notex.Note{__meta__: #Ecto.Schema.Metadata<:loaded>, id: 6,
note_content: "Finish this article...", note_name: "My To Do List"}}
iex(6)> Note.get_note(6)
%Notex.Note{__meta__: #Ecto.Schema.Metadata<:loaded>, id: 6,
note_content: "Finish this article...", note_name: "My To Do List"}
iex(7)> Note.delete_note(6)
{:ok,
%Notex.Note{__meta__: #Ecto.Schema.Metadata<:deleted>, id: 6,
note_content: nil, note_name: nil}}
iex(8)> Note.get_notes
[]
(Console debugging information redacted.)
And there we have it, a basic CRUD application using Ecto! We could render the output and make the API nicer to query against, but I’ll leave that as an extension, since those are tangential to what we are covering (and this article is long enough, I think).
Conclusion
This article has looked at the fundamentals of Ecto by creating a simple CRUD application from scratch. We’ve seen the many abilities Ecto packs to manage records and database changes, including migrations, schemas, and its querying DSL, along with touching upon tangential topics such as OTP. I hope this has served as a good primer for those looking to get up to speed in working with databases in Elixir!
In my next article, I look at the basics of Elixir’s Ecto Querying DSL.Frequently Asked Questions (FAQs) about Elixir’s Ecto Library
What is the purpose of Elixir’s Ecto library?
Elixir’s Ecto library is a database wrapper and language integrated query for Elixir. It’s designed to handle all the data manipulation tasks in an application, providing a unified API to interact with databases. Ecto allows you to create, read, update, and delete records, as well as perform complex queries, transactions, and migrations. It supports different databases, including PostgreSQL and MySQL, making it a versatile tool for any Elixir developer.
How does Ecto handle data validation?
Ecto uses a feature called “changesets” for data validation. A changeset is a data structure that holds changes to be made to the database, along with errors, validations, and type casting information. Changesets ensure that only valid data is saved to the database, providing a robust mechanism for data validation and error handling.
How can I perform complex queries with Ecto?
Ecto provides a powerful query API that allows you to write complex queries in a readable and efficient manner. You can use the from keyword to start a query, and chain other functions like select, where, order_by, and join to build the query. Ecto also supports subqueries, aggregations, and other advanced SQL features.
What is the role of Ecto.Schema in Elixir’s Ecto library?
Ecto.Schema is a module that defines the structure of your data. It maps the data from your Elixir application to your database tables and vice versa. With Ecto.Schema, you can define the fields of your data, their types, and any associations between different schemas.
How does Ecto handle database migrations?
Ecto provides a built-in mechanism for handling database migrations. Migrations are scripts that alter the structure of your database over time. They can create or drop tables, add or remove columns, create indexes, and so on. Ecto’s migration feature ensures that these changes are performed in a controlled and reversible manner.
Can Ecto work with NoSQL databases?
While Ecto was primarily designed for SQL databases, it can also work with NoSQL databases through the use of adapters. However, some features like migrations and complex queries may not be fully supported or may work differently depending on the specific NoSQL database and adapter used.
How does Ecto handle transactions?
Ecto provides a simple and powerful API for handling transactions. You can use the Ecto.Repo.transaction function to start a transaction, and any changes made within the transaction will be committed to the database if the function returns :ok, or rolled back if it returns :error.
What is Ecto.Multi?
Ecto.Multi is a feature of Ecto that allows you to group multiple operations together. It’s useful when you need to perform multiple operations in a single transaction, and you want all of them to succeed or fail as a whole. Ecto.Multi ensures data consistency and makes error handling easier.
How can I use Ecto with Phoenix?
Phoenix, the popular web framework for Elixir, integrates seamlessly with Ecto. Phoenix uses Ecto for all its data manipulation needs, and provides generators that make it easy to create Ecto schemas, changesets, and migrations. You can also use Ecto’s query API directly in your Phoenix controllers and views.
How can I learn more about Ecto?
The official Ecto documentation is a great resource for learning more about Ecto. It provides a comprehensive guide to all the features of Ecto, along with examples and best practices. You can also find many tutorials and blog posts online that cover various aspects of Ecto in more detail.
 Thomas Punt
Thomas PuntThomas is a recently graduated Web Technologies student from the UK. He has a vehement interest in programming, with particular focus on server-side web development technologies (specifically PHP and Elixir). He contributes to PHP and other open source projects in his free time, as well as writing about topics he finds interesting.






