


Mutations are something you hear about fairly often in the world of JavaScript, but what exactly are they, and are they as evil as they’re made out to be?
In this article, we’re going to cover the concepts of variable assignment and mutation and see why — together — they can be a real pain for developers. We’ll look at how to manage them to avoid problems, how to use as few as possible, and how to keep your code predictable.
If you’d like to explore this topic in greater detail, or get up to speed with modern JavaScript, check out the first chapter of my new book Learn to Code with JavaScript for free.
Let’s start by going back to the very basics of value types …
Key Takeaways
- JavaScript values are categorized into primitives (immutable) and objects (mutable), impacting how variable assignment and mutation behave.
- Using `const` does not prevent mutations to objects; it only prevents reassignment of the variable to a different value or object.
- The `let` keyword allows for reassignment, making it suitable for variables that need to change value throughout the code.
- The spread operator (`…`) is crucial for creating shallow copies of objects, thus avoiding issues related to mutations in copied-by-reference objects.
- Mutations are not inherently bad but should be managed carefully to maintain code predictability and minimize bugs, especially in dynamic web applications.
Data Types
Every value in JavaScript is either a primitive value or an object. There are seven different primitive data types:
- numbers, such as
3,0,-4,0.625 - strings, such as
'Hello',"World",`Hi`,'' - Booleans,
trueandfalse nullundefined- symbols — a unique token that’s guaranteed never to clash with another symbol
BigInt— for dealing with large integer values
Anything that isn’t a primitive value is an object, including arrays, dates, regular expressions and, of course, object literals. Functions are a special type of object. They are definitely objects, since they have properties and methods, but they’re also able to be called.
Variable Assignment
Variable assignment is one of the first things you learn in coding. For example, this is how we would assign the number 3 to the variable bears:
const bears = 3;
A common metaphor for variables is one of boxes with labels that have values placed inside them. The example above would be portrayed as a box containing the label “bears” with the value of 3 placed inside.

An alternative way of thinking about what happens is as a reference, that maps the label bears to the value of 3:
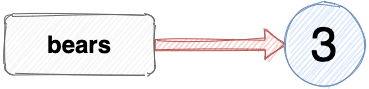
If I assign the number 3 to another variable, it’s referencing the same value as bears:
let musketeers = 3;
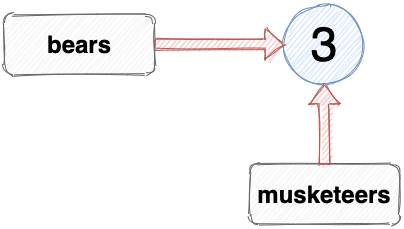
The variables bears and musketeers both reference the same primitive value of 3. We can verify this using the strict equality operator, ===:
bears === musketeers
<< true
The equality operator returns true if both variables are referencing the same value.
Some gotchas when working with objects
The previous examples showed primitive values being assigned to variables. The same process is used when assigning objects:
const ghostbusters = { number: 4 };
This assignment means that the variable ghostbusters references an object:
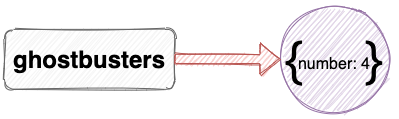
A big difference when assigning objects to variables, however, is that if you assign another object literal to another variable, it will reference a completely different object — even if both object literals look exactly the same! For example, the assignment below looks like the variable tmnt (Teenage Mutant Ninja Turtles) references the same object as the variable ghostbusters:
let tmnt = { number: 4 };
Even though the variables ghostbusters and tmnt look like they reference the same object, they actually both reference a completely different object, as we can see if we check with the strict equality operator:
ghostbusters === tmnt
<< false

Variable Reassignment
When the const keyword was introduced in ES6, many people mistakenly believed that constants had been introduced to JavaScript, but this wasn’t the case. The name of this keyword is a little misleading.
Any variable declared with const can’t be reassigned to another value. This goes for primitive values and objects. For example, the variable bears was declared using const in the previous section, so it can’t have another value assigned to it. If we try to assign the number 2 to the variable bears, we get an error:
bears = 2;
<< TypeError: Attempted to assign to readonly property.
The reference to the number 3 is fixed and the bears variable can’t be reassigned another value.
The same applies to objects. If we try to assign a different object to the variable ghostbusters, we get the same error:
ghostbusters = {number: 5};
TypeError: Attempted to assign to readonly property.
Variable reassignment using let
When the keyword let is used to declare a variable, it can be reassigned to reference a different value later on in our code. For example, we declared the variable musketeers using let, so we can change the value that musketeers references. If D’Artagnan joined the Musketeers, their number would increase to 4:
musketeers = 4;
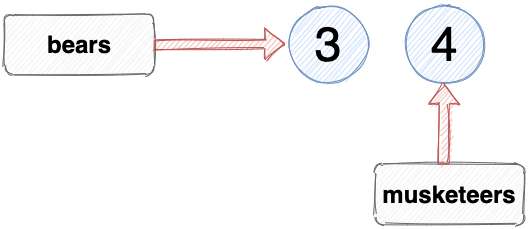
This can be done because let was used to declare the variable. We can alter the value that musketeers references as many times as we like.
The variable tmnt was also declared using let, so it can also be reassigned to reference another object (or a different type entirely if we like):
tmnt = {number: 5};
Note that the variable tmnt now references a completely different object; we haven’t just changed the number property to 5.
In summary, if you declare a variable using const, its value can’t be reassigned and will always reference the same primitive value or object that it was originally assigned to. If you declare a variable using let, its value can be reassigned as many times as required later in the program.
Using const as often as possible is generally considered good practice, as it means that the value of variables remains constant and the code is more consistent and predictable, making it less prone to errors and bugs.
Variable Assignment by Reference
In native JavaScript, you can only assign values to variables. You can’t assign variables to reference another variable, even though it looks like you can. For example, the number of Stooges is the same as the number of Musketeers, so we can assign the variable stooges to reference the same value as the variable musketeers using the following:
const stooges = musketeers;
This looks like the variable stooges is referencing the variable musketeers, as shown in the diagram below:
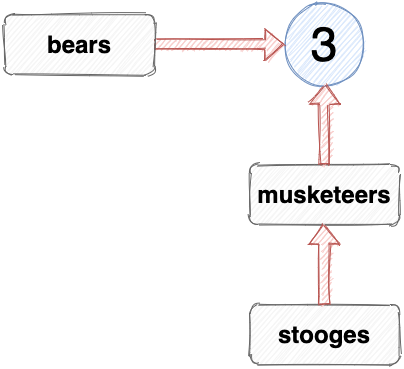
However, this is impossible in native JavaScript: a variable can only reference an actual value; it can’t reference another variable. What actually happens when you make an assignment like this is that the variable on the left of the assignment will reference the value the variable on the right references, so the variable stooges will reference the same value as the musketeers variable, which is the number 3. Once this assignment has been made, the stooges variable isn’t connected to the musketeers variable at all.
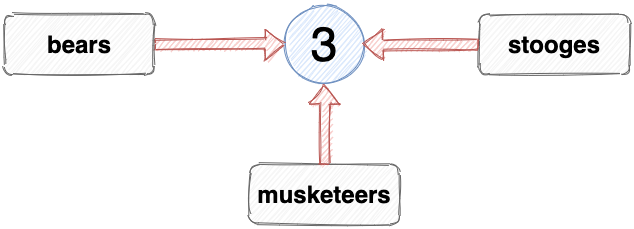
This means that if D’Artagnan joins the Musketeers and we set the value of the musketeers to 4, the value of stooges will remain as 3. In fact, because we declared the stooges variable using const, we can’t set it to any new value; it will always be 3.
In summary: if you declare a variable using const and set it to a primitive value, even via a reference to another variable, then its value can’t change. This is good for your code, as it means it will be more consistent and predictable.
Mutations
A value is said to be mutable if it can be changed. That’s all there is to it: a mutation is the act of changing the properties of a value.
All primitive value in JavaScript are immutable: you can’t change their properties — ever. For example, if we assign the string "cake" to variable food, we can see that we can’t change any of its properties:
const food = "cake";
If we try to change the first letter to “f”, it looks like it has changed:
food[0] = "f";
<< "f"
But if we take a look at the value of the variable, we see that nothing has actually changed:
food
<< "cake"
The same thing happens if we try to change the length property:
food.length = 10;
<< 10
Despite the return value implying that the length property has been changed, a quick check shows that it hasn’t:
food.length
<< 4
Note that this has nothing to do with declaring the variable using const instead of let. If we had used let, we could set food to reference another string, but we can’t change any of its properties. It’s impossible to change any properties of primitive data types because they’re immutable.
Mutability and objects in JavaScript
Conversely, all objects in JavaScript are mutable, which means that their properties can be changed, even if they’re declared using const (remember let and const only control whether or not a variable can be reassigned and have nothing to do with mutability). For example, we can change the the first item of an array using the following code:
const food = ['🍏','🍌','🥕','🍩'];
food[0] = '🍎';
food
<< ['🍎','🍌','🥕','🍩']
Note that this change still occurred, despite the fact that we declared the variable food using const. This shows that using const does not stop objects from being mutated.
We can also change the length property of an array, even if it has been declared using const:
food.length = 2;
<< 2
food
<< ['🍎','🍌']
Copying by Reference
Remember that when we assign variables to object literals, the variables will reference completely different objects, even if they look the same:
const ghostbusters = {number: 4};
const tmnt = {number: 4};
But if we assign a variable fantastic4 to another variable, they will both reference the same object:
const fantastic4 = tmnt;
This assigns the variable fantastic4 to reference the same object that the variable tmnt references, rather than a completely different object.
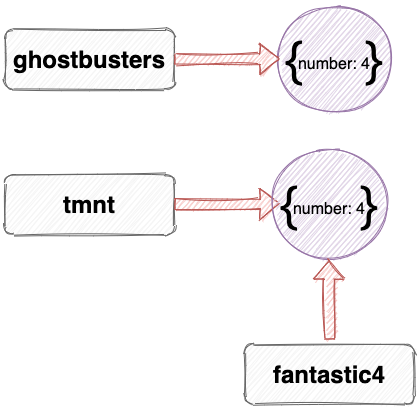
This is often referred to as copying by reference, because both variables are assigned to reference the same object.
This is important, because any mutations made to this object will be seen in both variables.
So, if Spider-Man joins The Fantastic Four, we might update the number value in the object:
fantastic4.number = 5;
This is a mutation, because we’ve changed the number property rather than setting fantastic4 to reference a new object.
This causes us a problem, because the number property of tmnt will also also change, possibly without us even realizing:
tmnt.number
<< 5
This is because both tmnt and fantastic4 are referencing the same object, so any mutations that are made to either tmnt or fantastic4 will affect both of them.
This highlights an important concept in JavaScript: when objects are copied by reference and subsequently mutated, the mutation will affect any other variables that reference that object. This can lead to unintended side effects and bugs that are difficult to track down.
The Spread Operator to the Rescue!
So how do you make a copy of an object without creating a reference to the original object? The answer is to use the spread operator!
The spread operator was introduced for arrays and strings in ES2015 and for objects in ES2018. It allows you to easily make a shallow copy of an object without creating a reference to the original object.
The example below shows how we could set the variable fantastic4 to reference a copy of the tmnt object. This copy will be exactly the same as the tmnt object, but fantastic4 will reference a completely new object. This is done by placing the name of the variable to be copied inside an object literal with the spread operator in front of it:
const tmnt = {number: 4};
const fantastic4 = {...tmnt};
What we’ve actually done here is assign the variable fantastic4 to a new object literal and then used the spread operator to copy all the enumerable properties of the object referenced by the tmnt variable. Because these properties are values, they’re copied into the fantastic4 object by value, rather than by reference.
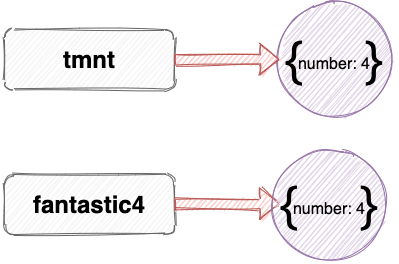
Now any changes that are made to either object won’t affect the other. For example, if we update the number property of the fantastic4 variable to 5, it won’t affect the tmnt variable:
fantastic4.number = 5;
fantastic4.number
<< 5
tmnt.number
<< 4
The spread operator also has a useful shortcut notation that can be used to make copies of an object and then make some changes to the new object in a single line of code.
For example, say we wanted to create an object to model the Teenage Mutant Ninja Turtles. We could create the first turtle object, and assign the variable leonardo to it:
const leonardo = {
animal: 'turtle',
color: 'blue',
shell: true,
ninja: true,
weapon: 'katana'
}
The other turtles all have the same properties, except for the weapon and color properties, that are different for each turtle. It makes sense to make a copy of the object that leonardo references, using the spread operator, and then change the weapon and color properties, like so:
const michaelangelo = {...leonardo};
michaelangelo.weapon = 'nunchuks';
michaelangelo.color = 'orange';
We can do this in one line by adding the properties we want to change after the reference to the spread object. Here’s the code to create new objects for the variables donatello and raphael:
const donatello = {...leonardo, weapon: 'bo staff', color: 'purpple'}
const raphael = {...leonardo, weapon: 'sai', color: 'purple'}
Note that using the spread operator in this way only makes a shallow copy of an object. To make a deep copy, you’d have to do this recursively, or use a library. Personally, I’d advise that you try to keep your objects as shallow as possible.
Are Mutations Bad?
In this article, we’ve covered the concepts of variable assignment and mutation and seen why — together — they can be a real pain for developers.
Mutations have a bad reputation, but they’re not necessarily bad in themselves. In fact, if you’re building a dynamic web app, it must change at some point. That’s literally the meaning of the word “dynamic”! This means that there will have to be some mutations somewhere in your code. Having said that, the fewer mutations there are, the more predictable your code will be, making it easier to maintain and less likely to develop any bugs.
A particularly toxic combination is copying by reference and mutations. This can lead to side effects and bugs that you don’t even realize have happened. If you mutate an object that’s referenced by another variable in your code, it can cause lots of problems that can be difficult to track down. The key is to try and minimize your use of mutations to the essential and keep track of which objects have been mutated.
In functional programming, a pure function is one that doesn’t cause any side effects, and mutations are one of the biggest causes of side effects.
A golden rule is to avoid copying any objects by reference. If you want to copy another object, use the spread operator and then make any mutations immediately after making the copy.
Next up, we’ll look into array mutations in JavaScript.
Don’t forget to check out my new book Learn to Code with JavaScript if you want to get up to speed with modern JavaScript. You can read the first chapter for free. And please reach out on Twitter if you have any questions or comments!
Frequently Asked Questions (FAQs) about JavaScript Variable Assignment and Mutation
What is the difference between variable assignment and mutation in JavaScript?
In JavaScript, variable assignment refers to the process of assigning a value to a variable. For example, let x = 5; Here, we are assigning the value 5 to the variable x. On the other hand, mutation refers to the process of changing the value of an existing variable. For example, if we later write x = 10; we are mutating the variable x by changing its value from 5 to 10.
How does JavaScript handle variable assignment and mutation differently for primitive and non-primitive data types?
JavaScript treats primitive data types (like numbers, strings, and booleans) and non-primitive data types (like objects and arrays) differently when it comes to variable assignment and mutation. For primitive data types, when you assign a variable, a copy of the value is created and stored in a new memory location. However, for non-primitive data types, when you assign a variable, both variables point to the same memory location. Therefore, if you mutate one variable, the change is reflected in all variables that point to that memory location.
What is the concept of pass-by-value and pass-by-reference in JavaScript?
Pass-by-value and pass-by-reference are two ways that JavaScript can pass variables to a function. When JavaScript passes a variable by value, it creates a copy of the variable’s value and passes that copy to the function. Any changes made to the variable inside the function do not affect the original variable. However, when JavaScript passes a variable by reference, it passes a reference to the variable’s memory location. Therefore, any changes made to the variable inside the function also affect the original variable.
How can I prevent mutation in JavaScript?
There are several ways to prevent mutation in JavaScript. One way is to use the Object.freeze() method, which prevents new properties from being added to an object, existing properties from being removed, and prevents changing the enumerability, configurability, or writability of existing properties. Another way is to use the const keyword when declaring a variable. This prevents reassignment of the variable, but it does not prevent mutation of the variable’s value if the value is an object or an array.
What is the difference between shallow copy and deep copy in JavaScript?
In JavaScript, a shallow copy of an object is a copy of the object where the values of the original object and the copy point to the same memory location for non-primitive data types. Therefore, if you mutate the copy, the original object is also mutated. On the other hand, a deep copy of an object is a copy of the object where the values of the original object and the copy do not point to the same memory location. Therefore, if you mutate the copy, the original object is not mutated.
How can I create a deep copy of an object in JavaScript?
One way to create a deep copy of an object in JavaScript is to use the JSON.parse() and JSON.stringify() methods. The JSON.stringify() method converts the object into a JSON string, and the JSON.parse() method converts the JSON string back into an object. This creates a new object that is a deep copy of the original object.
What is the MutationObserver API in JavaScript?
The MutationObserver API provides developers with a way to react to changes in a DOM. It is designed to provide a general, efficient, and robust API for reacting to changes in a document.
How does JavaScript handle variable assignment and mutation in the context of closures?
In JavaScript, a closure is a function that has access to its own scope, the scope of the outer function, and the global scope. When a variable is assigned or mutated inside a closure, it can affect the value of the variable in the outer scope, depending on whether the variable was declared in the closure’s scope or the outer scope.
What is the difference between var, let, and const in JavaScript?
In JavaScript, var, let, and const are used to declare variables. var is function scoped, and if it is declared outside a function, it is globally scoped. let and const are block scoped, meaning they exist only within the block they are declared in. The difference between let and const is that let allows reassignment, while const does not.
How does JavaScript handle variable assignment and mutation in the context of asynchronous programming?
In JavaScript, asynchronous programming allows multiple things to happen at the same time. When a variable is assigned or mutated in an asynchronous function, it can lead to unexpected results if other parts of the code are relying on the value of the variable. This is because the variable assignment or mutation may not have completed before the other parts of the code run. To handle this, JavaScript provides several features, such as promises and async/await, to help manage asynchronous code.

