
Keep up to date on current trends and technologies
Blog

Local AI Coding vs Cloud: Performance Analysis 2026
SitePoint Team

AI Agent Testing Automation: Developer Workflows for 2026
SitePoint Team

Best Ethereum Payment Gateways 2026
NOWPayments

How AI Assistants Improve Remote Team Communication for Developers
SitePoint Team
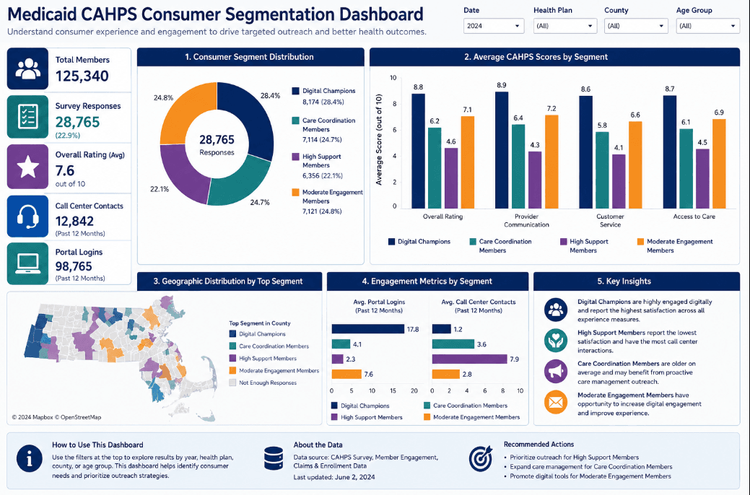
From Survey Responses to Consumer Insights: Building a Medicaid Consumer Segmentation Pipeline with Python, K-Means, and Tableau
Shilei Zhang

Claude Sonnet 5 Pricing: What the Cost Parity Misses
SitePoint Team

Alibaba Bans Claude Code: The Backdoor Scare Explained
Matt Mickiewicz

The Cost Inversion: Running Production AI on DeepSeek V4-Flash vs Gemini
Matt Mickiewicz
Beyond Code Generation: How AI Is Reshaping Modern Software Delivery
A Smith
Claude Fable 5: What the Mythos-Class Model Means for Developer AI Workflows
SitePoint Team
Claude Sonnet 5: The Developer’s Guide to Anthropic’s New Default Model
SitePoint Team

OpenClaude with DeepSeek V4: Running a Fully Private AI Coding Engine on Your Laptop
Matt Mickiewicz

HALO: Debug AI Agent Traces Locally Without a Cloud Subscription
SitePoint Team

OpenTelemetry GenAI: Instrument AI Agents Without Sending Data to the Cloud
SitePoint Team

How to build a production-ready AI meeting assistant with Recall.ai in 48 hours
SitePoint Sponsors

Prompt Compression and Cache Tuning: Cut Your LLM API Costs by 60%
SitePoint Team

Claude Code on Ollama: How to Run a Local Coding Agent Without Burning API Credits
SitePoint Team

Build an MCP Server in Go: A Production-Ready Tutorial for the Model Context Protocol
SitePoint Team

React 19's useOptimistic and useActionState: Replacing 80% of Your State Boilerplate
SitePoint Team

TypeScript 5.9: The strictInference Flag and Stable Decorator Metadata That Actually Matter
SitePoint Team

CSS Container Queries + Subgrid: The Layout Trilogy That's Now in Every Browser
SitePoint Team

How to Build Privacy-Safe Cross-Organizational Data Joins with Databricks Cleanrooms
Anurag Malik

3 REST API Testing Mistakes That Cost Us the Most Time (and How We Fixed Them)
Rishi Gaurav

I Built a Tiny Journal App to Learn Laravel. Here's the Process, Step by Step.
SitePoint Team

headroom: The Token-Compression CLI That Cuts Your LLM API Costs by 60–95%
Matt Mickiewicz

Gemma 4 QAT: Running Local LLMs in 6GB RAM
SitePoint Team

Turbopack in Production: Next.js 15 Speed Wins
SitePoint Team

React Compiler: Eliminating Manual Performance Work
SitePoint Team

Claude Code v2.1.166: Building Resilient Agent Stacks
SitePoint Team

DeepSeek V4-Pro on Ollama Cloud
SitePoint Team

Best Mass Payouts Service in 2026
NOWPayments

Best Mass Payout Solutions in 2026
NOWPayments
Showing 32 of 8451