Keep up to date on current trends and technologies
Blog
Professional Video Editor: The Foundation of Modern Digital Storytelling
SitePoint Sponsors
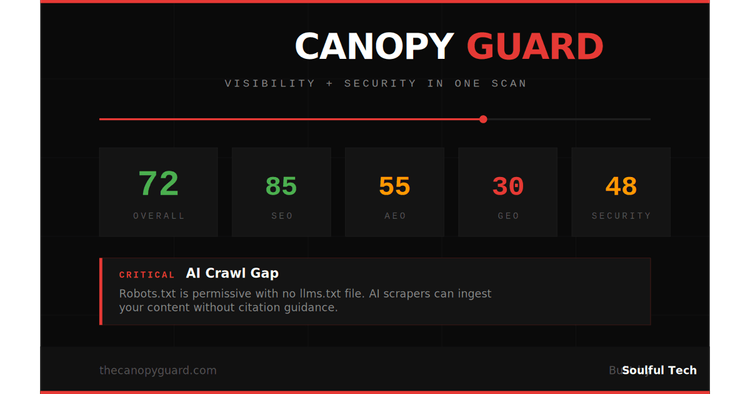
How I Built a 47-Signal Website Audit Tool That Runs in 15 Seconds
Adam McClarin
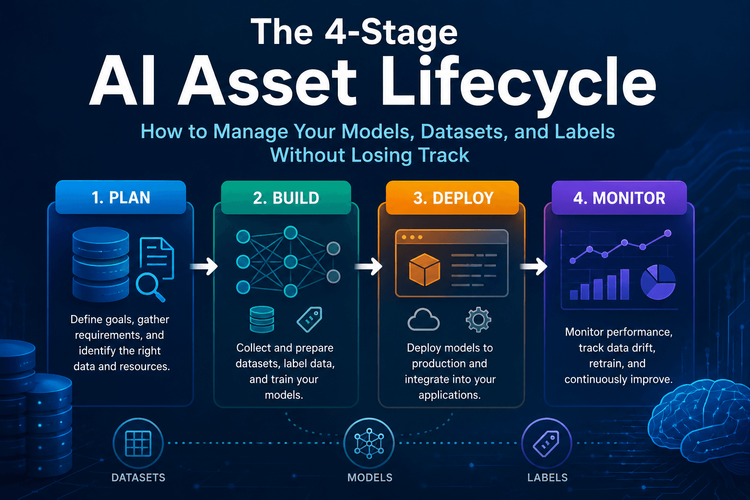
The 4-Stage AI Asset Lifecycle: How to Manage Your Models, Datasets, and Labels Without Losing Track
Bilal Ahmad

I Built a Task Management API in Laravel to Learn the Fundamentals (Here's What Happened)
SitePoint Team

**PyTorch Stochastic Gradient Optimization Technique**
aritrabesu

Payment orchestration Platforms for Enterprises to watch in 2026
SitePoint Sponsors

How to Authenticate AWS Workloads to Google Cloud Without Service Account Keys
Saurabh Ahuja

Why Building AI Products Is More Than Connecting an API
Christian chimeremeze ezenwa

Why Function Calling Is More Important Than Prompt Engineering
Christian chimeremeze ezenwa

Which DeepSeek Model Fits Your Hardware? VRAM Sizing Guide for 2026
SitePoint Team

How to Route DeepSeek-V4 Through Claude Code for Local Agentic Coding
SitePoint Team

Claude Code Plan Mode: The Read-First Workflow for Complex Refactors
SitePoint Team

AI Is Not Your Accessibility Expert: What LLMs Still Miss About WCAG
ashokyadav1231

How I Architected an Automated Programmatic SEO Auditor Using Node.js and LLM Function Calling
Christian chimeremeze ezenwa

DeepSeek R2: What Developers Need to Know Before August
SitePoint Team

Automating Code Review with DeepSeek in GitHub Actions
SitePoint Team

DeepSeek API + OpenAI SDK: A Developer's Quick-Start Guide
SitePoint Team

Local LLMs Are Getting Easier: The Complete Guide (2026)
SitePoint Team
Local LLM Deployment: Ollama vs vLLM vs LM Studio Compared
SitePoint Team

Stop Building Dumb AI Wrappers: Getting Real with LLM Function Calling
SitePoint Team

Stop Guessing: Why Transparent Pricing Calculators Are the Future of Web Agencies
sharjeel

Vibe Coding 2026: The Structured Guide to AI-First Development
SitePoint Team

Build a Human-AI Collaborative Workflow with ArvoWorks and Kanban
SitePoint Team

Vitest 4 Browser Mode: Component Testing Without Playwright
SitePoint Team

OpenAI Codex CLI: Terminal-First Coding Agent Tutorial (2026)
SitePoint Team

LM Studio 0.4 Headless Deployment: Local LLM APIs Without the GUI
SitePoint Team
Everything Claude Code: Turn Your AI Coding Agent Into a Production Engineering Platform
SitePoint Team

The New Reality of Agent Memory: The Complete Guide (2026)
Matt Mickiewicz

From a Shattered Screen to the Cloud: Building an AI Future with Termux in Nigeria
SitePoint Team

How to Name Your App (and Get the Best Trademark)
SitePoint Sponsors

5 Best JavaScript Beautifier Tools for Clean and Readable Code
Bansidhar Kadiya

Write for SitePoint
Zain Zaidi
Showing 32 of 8387