Concurrency with Modern C++
A Quick Overview
With the publishing of the C++11 standard, C++ got a multithreading library and a memory model. This library has basic building blocks like atomic variables, threads, locks, and condition variables. That’s the foundation on which future C++ standards such as C++20 and C++23 can establish higher abstractions. However, C++11 already knows tasks, which provide a higher abstraction than the cited basic building blocks.
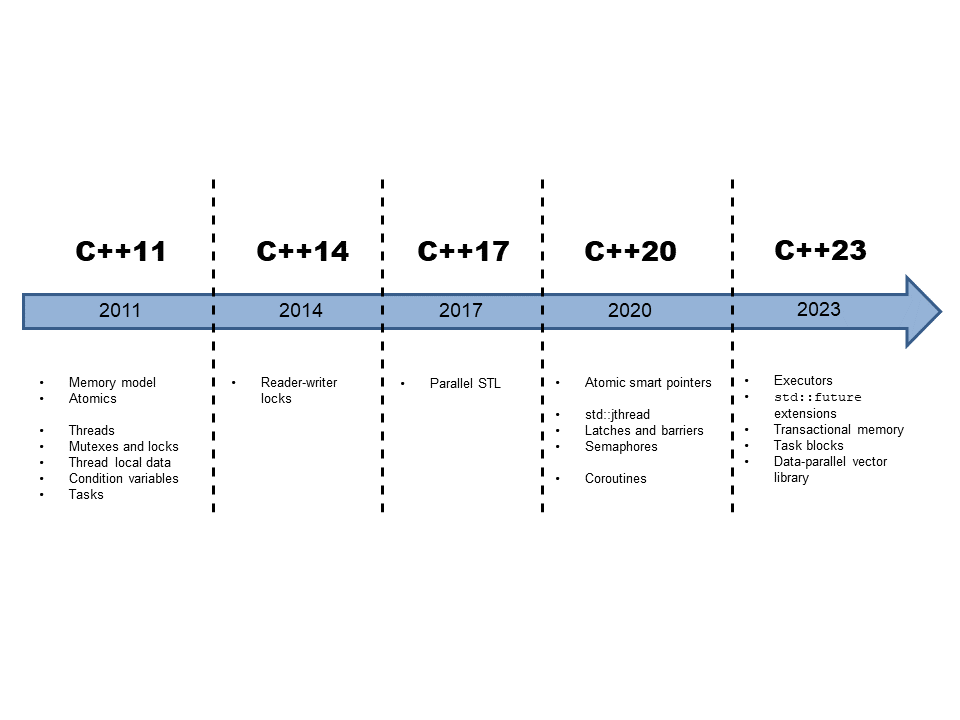
Concurrency in C++
Roughly speaking, you can divide the concurrency story of C++ into three evolution steps.
1.1 C++11 and C++14: The Foundation
C++11 introduced multithreading. The multithreading support consists of a well-defined memory model and a standardized threading interface. C++14 added reader-writer locks to the multithreading facilities of C++.
1.1.1 Memory Model

Memory Model in C++
The foundation of multithreading is a well-defined memory model. This memory model has to deal with the following aspects:
- Atomic operations: operations that are performed without interruption.
- Partial ordering of operations: a sequence of operations that must not be reordered.
- Visible effects of operations: guarantees when operations on shared variables are visible in other threads.
The C++ memory model is inspired by its predecessor: the Java memory model. Unlike the Java memory model, however, C++ allows us to break the constraints of sequential consistency, which is the default behavior of atomic operations.
Sequential consistency provides two guarantees.
- The instructions of a program are executed in source code order.
- There is a global order for all operations on all threads.
The memory model is based on atomic operations on atomic data types (short atomics).
1.1.1.1 Atomics
C++ has a set of simple atomic data types. These are booleans, characters, numbers, and pointers in many variants. You can define your atomic data type with the class template std::atomic. Atomics establishes synchronization and ordering constraints that can also hold for non-atomic types.
The standardized threading interface is the core of concurrency in C++.
1.1.2 Multithreading
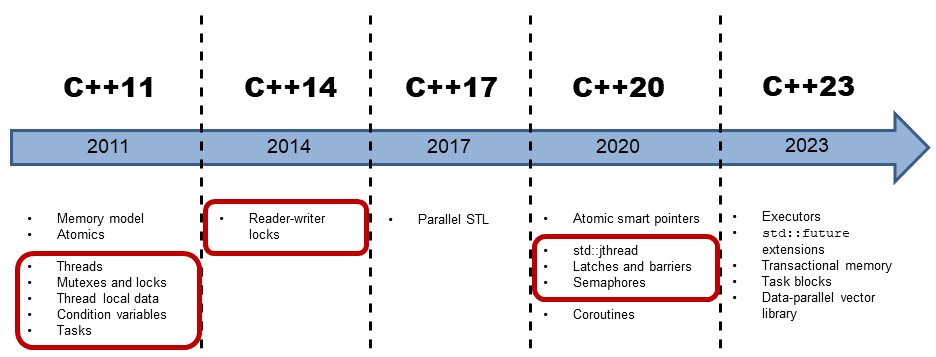
Multithreading in C++
Multithreading in C++ consists of threads, synchronization primitives for shared data, thread-local data, and tasks.
1.1.2.1 Threads
C++ supports two kind of threads: the basic thread std::thread (C++11) and the improved thread std::jthread (C++20).
1.1.2.1.1 std::thread
A std::thread represents an independent unit of program execution. The executable unit, which is started immediately, receives its work package as a callable unit. A callable unit can be a named function, a function object, or a lambda function.
The creator of a thread is responsible for its lifecycle. The executable unit of the new thread ends with the end of the callable. Either the creator waits until the created thread t is done (t.join()) or the creator detaches itself from the created thread: t.detach(). A thread t is joinable if no operation t.join() or t.detach() was performed on it. A joinable thread calls std::terminate in its destructor, and the program terminates.
A from its creator detached thread is typically called a daemon thread because it runs in the background.
A std::thread is a variadic template. This means that it can receive an arbitrary number of arguments; either the callable or the thread can get the arguments.
1.1.2.1.2 std::jthread (C++20)
std::jthread stands for joining thread. In addition to std::thread from C++11, std::jthread automatically joins in it destructor and can cooperatively be interrupted. Consequently, std::jthread extends the interface of std::thread.
1.1.2.2 Shared Data
You have to coordinate access to a shared variable if more than one thread uses it simultaneously and the variable is mutable (non-const). Reading and writing a shared variable concurrently is a data race and, therefore, undefined behavior. Coordinating access to a shared variable is achieved with mutexes and locks in C++.
1.1.2.2.1 Mutexes
A mutex (mutual exclusion) guarantees that only one thread can access a shared variable at any given time. A mutex locks and unlocks the critical section, to which the shared variable belongs. C++ has five different mutexes. They can lock recursively, tentatively, and with or without time constraints. Even mutexes can share a lock at the same time.
1.1.2.2.2 Locks
You should encapsulate a mutex in a lock to release the mutex automatically. A lock implements the RAII idiom by binding a mutex’s lifetime to its own. C++ has a std::lock_guard / std::scoped_lock for the simple, and a std::unique_lock / std::shared_lock for the advanced use cases such as the explicit locking or unlocking of the mutex, respectively.
1.1.2.2.3 Thread-safe Initialization of Data
If shared data is read-only, it’s sufficient to initialize it in a thread-safe way. C++ offers various ways to achieve this including using a constant expression, a static variable with block scope, or using the function std::call_once in combination with the flag std::once_flag.
1.1.2.3 Thread Local Data
Declaring a variable as thread-local ensures that each thread gets its own copy. Therefore, there is no shared variable. The lifetime of thread-local data is bound to the lifetime of its thread.
1.1.2.4 Condition Variables
Condition variables enable threads to be synchronized via messages. One thread acts as the sender while the other acts as the receiver of the message. The receiver blocks waiting for the message from the sender. Typical use cases for condition variables are producer-consumer workflows. A condition variable can be either the sender or the receiver of the message. Using condition variables correctly is quite challenging; therefore, tasks are often the easier solution.
1.1.2.5 Cooperative Interruption (C++20)
The additional functionality of the cooperative interruption of std::jthread is based on the std::stop_source, std::stop_token, and the std::stop_callback classes. std::jthread and std::condition_variable_any support cooperative interruption by design.
1.1.2.6 Semaphores (C++20)
Semaphores are a synchronization mechanism used to control concurrent access to a shared resource. A counting semaphore is a semaphore that has a counter that is bigger than zero. The counter is initialized in the constructor. Acquiring the semaphore decreases the counter, and releasing the semaphore increases the counter. If a thread tries to acquire the semaphore when the counter is zero, the thread will block until another thread increments the counter by releasing the semaphore.
1.1.2.7 Latches and Barriers (C++20)
Latches and barriers are coordination types that enable some threads to block until a counter becomes zero. The counter is initialized in the constructor. At first, don’t confuse the new barriers with memory barriers, also known as fences. In C++20 we get latches and barriers in two variations: std::latch, and std::barrier. Concurrent invocations of the member functions of a std::latch or a std::barrier produce no data race.
1.1.2.8 Tasks
Tasks have a lot in common with threads. While you explicitly create a thread, a task is just a job you start. The C++ runtime automatically handles, such as in the simple case of std::async, the task’s lifetime.
Tasks are like data channels between two communication endpoints. They enable thread-safe communication between threads. The promise as one endpoint puts data into the data channel, the future at the other endpoint picks the value up. The data can be a value, an exception, or simply a notification. In addition to std::async, C++ has the class templates std::promise and std::future that give you more control over the task.
1.1.2.9 Synchronized Outputstreams (C++20)
With C++20, C++ enables synchronized outputstreams. std::basic_syncbuf is a wrapper for a std::basic_streambuf. It accumulates output in its buffer. The wrapper sets its content to the wrapped buffer when it is destructed. Consequently, the content appears as a contiguous sequence of characters, and no interleaving of characters can happen. Thanks to std::basic_osyncstream, you can directly write synchronously to std::cout.
1.2 C++17: Parallel Algorithms of the Standard Template Library
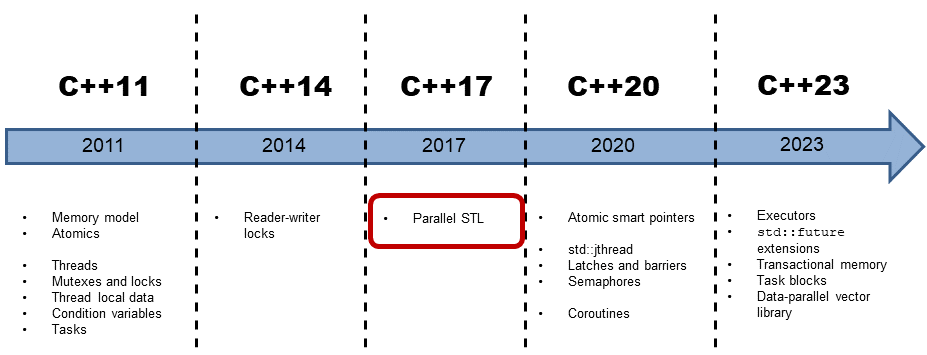
Parallel algorithms in C++17
With C++17, concurrency in C++ has drastically changed, in particular the parallel algorithms of the Standard Template Library (STL). C++11 and C++14 only provide the basic building blocks for concurrency. These tools are suitable for a library or framework developer but not for the application developer. Multithreading in C++11 and C++14 becomes an assembly language for concurrency in C++17!
1.2.1 Execution Policy
With C++17, most of the STL algorithms are available in a parallel implementation. This makes it possible for you to invoke an algorithm with a so-called execution policy. This policy specifies whether the algorithm runs sequentially (std::execution::seq), in parallel (std::execution::par), or in parallel with additional vectorisation (std::execution::par_unseq).
1.2.2 New Algorithms
In addition to the 69 algorithms available in overloaded versions for parallel, or parallel and vectorized execution, we get eight additional algorithms. These new ones are well suited for parallel reducing, scanning, or transforming ranges.
1.3 Coroutines
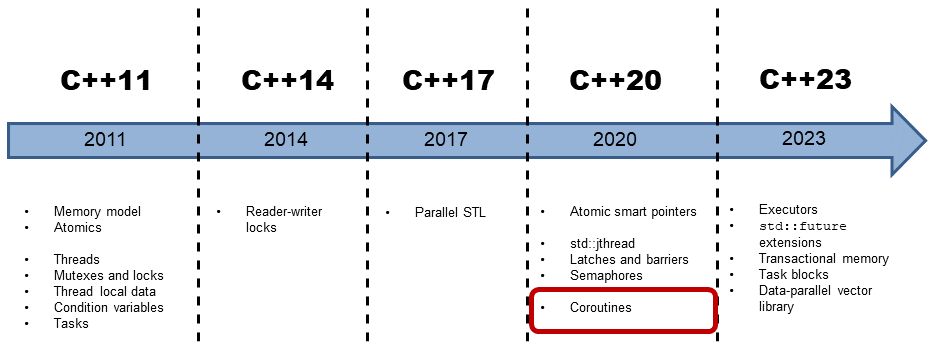
Coroutines
Coroutines are functions that can suspend and resume their execution while maintaining their state. Coroutines are often the preferred approach to implement cooperative multitasking in operating systems, event loops, infinite lists, or pipelines.
1.4 Case Studies
After presenting the theory of the memory model and the multithreading interface, I apply the theory in a few case studies.
1.4.1 Calculating the Sum of a Vector
Calculating the sum of a vector can be done in various ways. You can do it sequentially or concurrently with maximum and minimum sharing of data. The performance numbers differ drastically.
1.4.2 The Dining Philosophers Problem by Andre Adrian
The dining philosophers problem is a classic synchronization problem formulated by Edsger Dijkstra in the article Hierarchical Ordering of Sequential Processes: Five philosophers, numbered from 0 through 4 are living in a house where the table laid for them, each philosopher having his own place at the table. Their only problem - besides those of philosophy - is that the dish served is a very difficult kind of spaghetti, that has to be eaten with two forks. There are two forks next to each plate, so that presents no difficulty: as a consequence, however, no two neighbours may be eating simultaneously.
1.4.3 Thread-Safe Initialization of a Singleton
Thread-safe initialization of a singleton is the classical use-case for thread-safe initialization of a shared variable. There are many ways to do it, with varying performance characteristics.
1.4.4 Ongoing Optimization with CppMem
I start with a small program and successively improve it by weakening the memory ordering. I verify each step of my process of ongoing optimization with CppMem. CppMem is an interactive tool for exploring the behavior of small code snippets using the C++ memory model.
1.4.5 Fast Synchronization of Threads
There are many ways in C++20 to synchronize threads. You can use condition variables, std::atomic_flag, std::atomic<bool>, or semaphores. I discuss the performance numbers of various ping-pong games.
1.5 Variations of Futures
Thanks to the new keyword co_return, I can implement in the case study variations of futures an eager future, a lazy future, or a future running in a separate thread. Heavily used comments make its workflow transparent.
1.6 Modification and Generalization of a Generator
co_yield enables it to create infinite data streams. In the case stucy modification and generalization of a generator, the infinite data streams become finite and generic.
1.7 Various Job Workflows
The case study of various job workflows presents a few coroutines that are automatically resumed if necessary. co_await makes this possible.
1.8 The Future: C++23
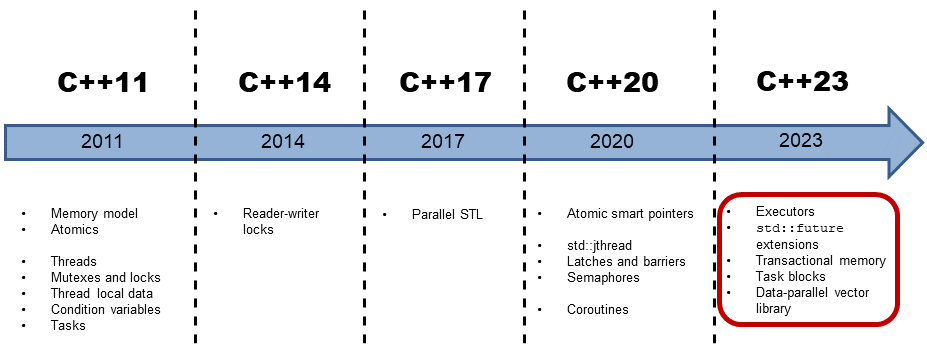
Concurrency in C++23
It isn’t easy to make predictions, especially about the future (Niels Bohr).
1.8.1 Executors
An executor consists of a set of rules about where, when, and how to run a callable unit. They are the basic building block to execute and specify if callables should run on an arbitrary thread, a thread pool, or even single threaded without concurrency. The extended futures, the extensions for networking N4734 depend on them but also the parallel algorithms of the STL, and the new concurrency features in C++20/23 such as latches and barriers, coroutines, transactional memory, and task blocks eventually use them.
1.8.2 Extended futures
Tasks called promises and futures, introduced in C++11, have a lot to offer, but they also have drawbacks: tasks are not composable into powerful workflows. That limitation does not hold for the extended futures in C++23. Therefore, an extended future becomes ready when its predecessor (then) becomes ready, when_any one of its predecessors becomes ready, or when_all of its predecessors becomes ready.
1.8.3 Transactional Memory
Transactional memory is based on the ideas underlying transactions in database theory. A transaction is an action that provides the first three properties of ACID database transactions: A tomicity, C onsistency, and I solation. The durability that is characteristic for databases holds not for the proposed transactional memory in C++. The new standard has transactional memory in two flavors: synchronized blocks and atomic blocks. Both are executed in total order and behave as if a global lock protected them. In contrast to synchronized blocks, atomic blocks cannot execute transaction-unsafe code.
1.8.4 Task Blocks
Task Blocks implement the fork-join paradigm in C++. The following graph illustrates the key idea of a task block: you have a fork phase in which you launch tasks and a join phase in which you synchronize them.
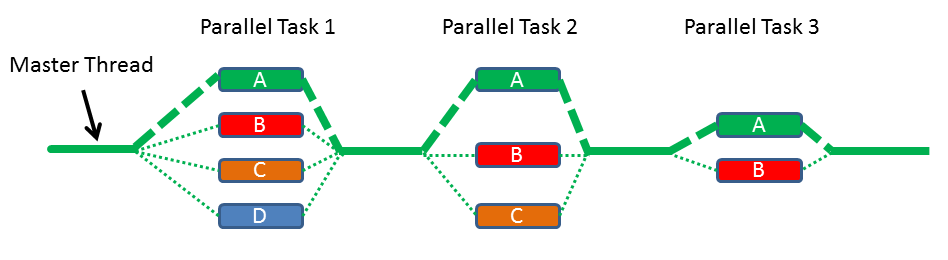
Task Blocks
1.8.5 Data-Parallel Vector Library
The data-parallel vector library provides data-parallel (SIMD) programming via vector types. SIMD means that one operation is performed on many data in parallel.
1.9 Patterns and Best Practices
Patterns are documented best practices from the best. They “… express a relation between a certain context, a problem, and a solution.” Christopher Alexander. Thinking about the challenges of concurrent programming from a more conceptional point of view provides many benefits. In contrast to the more conceptional patterns to concurrency, the chapter best practices provide pragmatic tips to overcome the concurrency challenges.
1.9.1 Synchronization
A necessary prerequisite for a data race is shared mutable state. Synchronization patterns boil down to two concerns: dealing with sharing and dealing with mutation.
1.9.2 Concurrent Architecture
The chapter to concurrent architecture presents five patterns. The two patterns Active Object and the Monitor Object synchronize and schedule member functions invocation. The third pattern Half-Sync/Half-Async has an architectural focus and decouples asynchronous and synchronous service processing in concurrent systems. The Reactor pattern and the Proactor pattern can be regarded as variations of the Half-Sync/Half-Async pattern. Both patterns enable event-driven applications to demultiplex and dispatch service requests. The reactor performs its job synchronously, but the proactor asynchronously.
1.9.3 Best Practices
Concurrent programming is inherently complicated, therefore having best practices in general, but also for multithreading, and the memory model makes a lot of sense.
1.10 Data Structures
A data structure that protects itself so that no data race can appear is called thread-safe. The chapter lock-based data structures presents the challenges to design those lock-based data structures.
1.11 Challenges
Writing concurrent programs is inherently complicated. This is particularly true if you only use C++11 and C++14 features. Therefore, I describe in detail the most challenging issues. I hope that if I dedicate a whole chapter to the challenges of concurrent programming, you become more aware of the pitfalls. I write about challenges such as race conditions, data races, and deadlocks.
1.12 Time Library
The time library is a key component of the concurrent facilities of C++. Often you let a thread sleep for a specific time duration or until a particular point in time. The time library consists of: time points, time durations, and clocks.
1.13 CppMem
CppMem is an interactive tool to get deeper inside into the memory model. It provides two precious services. First, you can verify your lock-free code, and second, you can analyze your lock-free code and get a more robust understanding of your code. I often use CppMem in this book. Because the configuration options and the insights of CppMem are quite challenging, the chapter gives you a basic understanding of CppMem.
1.14 Glossary
The glossary contains non-exhaustive explanations on essential terms.