So you’ve finished reading Kevin Yank’s article Building a Database-Driven Web Site Using PHP and MySQL, and you’re happily databasing your site, when it starts to slow down. You need to get your site zipping along again before your host threatens to kick you off for almost killing their server. How do you do this? Enter: MySQL’s internal turbo-charger, indexes.
Disclaimer
I’ve attempted to keep my queries as simple as possible, but I assume that you have a basic understanding of databases and the SQL language (more specifically, MySQL’s implementation of it). I also assume you have MySQL 3.23, as a few of these queries may not work on 3.22. If you don’t have MySQL 3.23 yet, I highly recommend you install it if possible, as some of the performance increases are significant.
What are Indexes?
Indexes are organized versions of specific columns in your tables. MySQL uses indexes to facilitate quick retrieval of records. With indexes, MySQL can jump directly to the records you want. Without any indexes, MySQL has to read the entire data file to find the correct record(s). Here’s an example.
Suppose we created a table called “people”:
CREATE TABLE people (
peopleid SMALLINT NOT NULL,
name CHAR(50) NOT NULL
);Then we insert 1000 different names into the table in a completely random, non-alphabetic order. A small portion of the data file may be represented like this:

As you can see, there’s no recognizable order to the “name” column whatsoever. If we create an index on the “name” column, MySQL will automatically order this index alphabetically:

For each entry in the index, MySQL also internally maintains a “pointer” to the correct row in the actual data file. So if I want to get the value of peopleid when the name is Mike (SELECT peopleid FROM people WHERE name='Mike';), MySQL can look in the name index for Mike, jump directly to the correct row in the data file, and return the correct value of peopleid (999). MySQL only has to look at one row to get the result. Without an index on “name”, MySQL would’ve scanned all 1000 rows in the data file! In general, the less rows MySQL has to evaluate, the quicker it can do its job.
Types of Indexes
There are several types of indexes to choose from in MySQL:
[Note: Full query lists and examples can be found at the end of this article.]
- “Normal” Indexes – “Normal” indexes are the most basic indexes, and have no restraints such as uniqueness. These can be added by creating an index (
CREATE INDEX name_of_index ON tablename (columns_to_index);), altering the table (ALTER TABLE tablename ADD INDEX [name_of_index] (columns_to_index);), or when creating the table (CREATE TABLE tablename ( [...], INDEX [name_of_index] (columns_to_index) );).
CREATE UNIQUE INDEX name_of_index ON tablename (columns_to_index);), altering the table (ALTER TABLE tablename ADD UNIQUE [name_of_index] (columns_to_index);) or when creating the table (CREATE TABLE tablename ( [...], UNIQUE [name_of_index] (columns_to_index) );)."PRIMARY". If you have used AUTO_INCREMENT columns, you’re probably familiar with these. These indexes are almost always added when creating the table (CREATE TABLE tablename ( [...], PRIMARY KEY (columns_to_index) );), but may also be added by altering the table (ALTER TABLE tablename ADD PRIMARY KEY (columns_to_index);). Note that you may only have one primary key per table.Single- vs. Multi-column Indexes
You’ve probably noticed that in the CREATE INDEX, ALTER TABLE and CREATE TABLE queries above, I made references to columns (plural). Again, this can be best explained by an example.
Here’s a more complex version of the people table:
CREATE TABLE people (
peopleid SMALLINT NOT NULL AUTO_INCREMENT,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
PRIMARY KEY (peopleid)
);(Note that because “peopleid” is an AUTO_INCREMENT field, it must be declared the primary key)
A small snippet of the data we insert may look like this (ignore townid for now):
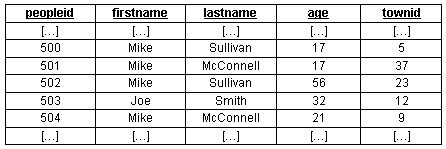
From this snippet, we have four Mikes (two Sullivans, two McConnells), two 17 year olds, and an unrelated odd ball (Joe Smith).
My intended use for this table is to get the peopleid for users with a specific first name, last name, and age. For example, I want to find the peopleid for Mike Sullivan, aged 17 (SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age=17;). Since I don’t want to have MySQL do a full table scan, I need to look into some indexing.
My first option is to create an index on a single column, firstname, lastname, or age. If I put the index on firstname (ALTER TABLE people ADD INDEX firstname (firstname);), MySQL will use the index to limit the records to those where firstname=’Mike’. Using this “temporary result set,” MySQL will apply each additional condition individually. First it eliminates those whose last name isn’t Sullivan. Then it eliminates those who aren’t 17. MySQL has now applied all conditions and can return the results.
This is more efficient than forcing MySQL to do a full table scan, but we’re still forcing MySQL to scan significantly more rows than it needs to. We could drop the index on firstname and add an index on lastname or age, but the results would be very similar.
Here’s where multi-column indexes come into play. If we add a single index on three columns, we can get the correct set in a single pass! Here is the code I use to add this index:
ALTER TABLE people ADD INDEX fname_lname_age (firstname,lastname,age);Since the index file is organized, MySQL can jump directly to the correct first name, then move to the correct last name, and finally go directly to the correct age. MySQL has found the correct rows without having to scan a single row of the data file!
Now, you’re probably wondering if creating three single-column indexes on (firstname), (lastname), and (age) is the same as one multi-column index on (firstname,lastname,age). No: it’s completely different. When running a query, MySQL can only use one index. If you have three single-column indexes, MySQL will attempt to pick the most restrictive one, but the most restrictive single-column index will be significantly less restrictive than our multi-column index on (firstname,lastname,age).
Leftmost Prefixing
Multi-column indexes provide an additional benefit through what is known as leftmost prefixing. To continue our previous example, we have a three-column index on (firstname,lastname,age), which I have nicknamed “fname_lname_age” (I’ll explain more about that later). This index will be used when searching the following combination of columns:
- firstname,lastname,age
- firstname,lastname
- firstname
To put it another way, we have basically created indexes on (firstname,lastname,age), (firstname,lastname), and just (firstname). The following queries can use the index:
SELECT peopleid FROM people WHERE firstname='Mike'
AND lastname='Sullivan' AND age='17';
SELECT peopleid FROM people WHERE firstname='Mike'
AND lastname='Sullivan';
SELECT peopleid FROM people WHERE firstname='Mike';The following queries cannot use the index at all:
SELECT peopleid FROM people WHERE lastname='Sullivan';
SELECT peopleid FROM people WHERE age='17';
SELECT peopleid FROM people WHERE lastname='Sullivan'
AND age='17';How to Pick Columns to Index
One of the most important steps in optimizing is selecting which columns to index. There are two major places you want to consider indexing: columns you reference in the WHERE clause and columns used in join clauses. Look at the following query:
SELECT
age ## no use indexing
FROM
people
WHERE
firstname='Mike' ## consider indexing
AND
lastname='Sullivan' ## consider indexingThis query is a little different from the past ones, but it’s still quite simple. Since “age” is referenced in the SELECT portion, MySQL will not use it to limit the chosen rows. Hence, there is no great need to index it. Here’s a more complex example:
SELECT
people.age, ## no use indexing
town.name ## no use indexing
FROM
people
LEFT JOIN
town
ON
people.townid=town.townid ## consider indexing
## town.townid
WHERE
firstname='Mike' ## consider indexing
AND
lastname='Sullivan' ## consider indexingThe possibility of indexing firstname and lastname carries over as they are again located in the WHERE clause. An additional field you’ll want to consider indexing is the townid field from town table (please note that I’m only using the town table as an example of a join) because it is in a join clause.
“So I simply consider indexing every field in the WHERE clause or a join clause?” Almost, but not quite. Next, you need to consider the type of comparisons your doing on the fields. MySQL will only use indexes for ‘<‘, ‘<=’, ‘=’, ‘>’, ‘>=’, BETWEEN, IN, and some LIKE operations. These specific LIKE operations are times where the first character is not a wildcard (% or _). SELECT peopleid FROM people WHERE firstname LIKE 'Mich%'; would use an index, but SELECT peopleid FROM people WHERE firstname LIKE '%ike'; wouldn’t.
Analyzing Index Efficiency
You have some ideas on which indexes to use, but you’re not sure which is the most efficient. Well, you’re in luck, because MySQL has a built-in SQL statement to do this, known as EXPLAIN. The general syntax for this is EXPLAIN select statement;. You can find more information in the MySQL documentation. Here’s an example:
EXPLAIN SELECT peopleid FROM people WHERE firstname='Mike'
AND lastname='Sullivan' AND age='17';This will return a somewhat cryptic result that will look usually look similar to this:
[Note: table split across two rows for readability]
+--------+------+-----------------+-----------------+
| table | type | possible_keys | key |
+--------+------+-----------------+-----------------+ ...
| people | ref | fname_lname_age | fname_lname_age |
+--------+------+-----------------+-----------------+
+---------+-------------------+------+------------+
| key_len | ref | rows | Extra |
... +---------+-------------------+------+------------+
| 102 | const,const,const | 1 | Where used |
+---------+-------------------+------+------------+
Let’s break this down column by column.
- table – This is the name of the table. This will become important when you have large joins, as each table will get a row.
- type – The type of the join. Here’s what the MySQL documentation has to say about the
reftype:
All rows with matching index values will be read from this table for each combination of rows from the previous tables. ref is used if the join uses only a leftmost prefix of the key, or if the key is not
UNIQUEor aPRIMARY KEY(in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this join type is good.In this case, since our index isn’t
UNIQUE, this is the best join type we can get.In summary, if the join type is listed as “ALL” and you aren’t trying to select most of the rows in the table, then MySQL is doing a full table scan which is usually very bad. You can fix this by adding more indexes. If you want more information, the MySQL manual covers this value with much more depth.
- possible_keys – The name of the indexes that could possibly be used. This is where nicknaming your index helps. If you leave the name field blank, the name defaults to the name of the first column in the index (in this case, it would be “firstname”), which isn’t very descriptive.
- key – This shows the name of the index that MySQL actually uses. If this is empty (or
NULL), then MySQL isn’t using an index. - key_len – The length, in bytes, of the parts of the index being used. In this case, it’s 102 because firstname takes 50 bytes, lastname takes 50, and age takes 2. If MySQL were only using the firstname part of the index, this would be 50.
- ref – This shows the name of the columns (or the word “const”) that MySQL will use to select the rows. Here, MySQL references three constants to find the rows.
- rows – The number of rows MySQL thinks it has to go through before knowing it has the correct rows. Obviously, one is the best you can get.
- Extra – There are many different options here, most of which will have an adverse effect on the query. In this case, MySQL is simply reminding us that it used the
WHEREclause to limit the results.
Disadvantages of Indexing
So far, I’ve only discussed why indexes are great. However, they do have several disadvantages.
First, they take up disk space. Usually this isn’t significant, but if you decided to index every column in every possible combination, your index file would grow much more quickly than the data file. If you have a large table, the index file could reach your operating system’s maximum file size.
Second, they slow down the speed of writing queries, such as DELETE, UPDATE, and INSERT. This is because not only does MySQL have to write to the data file, it has to write everything to the index file as well. However, you may be able to write your queries in such a way that the performance degradation is not very noticeable.
Conclusion
Indexes are one of the keys to speed in large databases. No matter how simple your table, a 500,000-row table scan will never be fast. If you have a site with a 500,000-row table, you should really spend time analyzing possible indexes and possibly consider rewriting queries to optimize your application.
As always, there is more to indexing than I covered in this article. More information can be found in the official MySQL manual, or in Paul DuBois’ great book, MySQL.
Query Reference
Adding a “normal” index via CREATE INDEX:
CREATE INDEX [index_name] ON tablename (index_columns); Example: CREATE INDEX fname_lname_age ON people (firstname,lastname,age);
Adding a unique index via CREATE INDEX:
CREATE UNIQUE INDEX [index_name] ON tablename (index_columns); Example: CREATE UNIQUE INDEX fname_lname_age ON people (firstname,lastname,age);
Adding a “normal” index via ALTER TABLE:
ALTER TABLE tablename ADD INDEX [index_name] (index_columns); Example: ALTER TABLE people ADD INDEX fname_lname_age (firstname,lastname,age);
Adding a unique index via ALTER TABLE:
ALTER TABLE tablename ADD UNIQUE [index_name] (index_columns); Example: ALTER TABLE people ADD UNIQUE fname_lname_age (firstname,lastname,age);
Adding a primary key via ALTER TABLE:
ALTER TABLE tablename ADD PRIMARY KEY (index_columns); Example: ALTER TABLE people ADD PRIMARY KEY (peopleid);
Adding a “normal” index via CREATE TABLE:
CREATE TABLE tablename ( Example:
rest of columns,
INDEX [index_name] (index_columns)
[other indexes]
);
CREATE TABLE people (
peopleid SMALLINT UNSIGNED NOT NULL,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
INDEX fname_lname_age (firstname,lastname,age)
);
Adding a unique index via CREATE TABLE:
CREATE TABLE tablename ( Example:
rest of columns,
UNIQUE [index_name] (index_columns)
[other indexes]
);
CREATE TABLE people (
peopleid SMALLINT UNSIGNED NOT NULL,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
UNIQUE fname_lname_age (firstname,lastname,age)
);
Adding a primary key via CREATE TABLE:
CREATE TABLE tablename ( Example:
rest of columns,
INDEX [index_name] (index_columns)
[other indexes]
);
CREATE TABLE people (
peopleid SMALLINT NOT NULL AUTO_INCREMENT,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
PRIMARY KEY (peopleid)
);
Dropping (removing) a “normal” or unique index via ALTER TABLE:
ALTER TABLE tablename DROP INDEX index_name; Example: ALTER TABLE people DROP INDEX fname_lname_age;
Dropping (removing) a primary key via ALTER TABLE:
ALTER TABLE tablename DROP PRIMARY KEY; Example: ALTER TABLE people DROP PRIMARY KEY;
 Mike Sullivan
Mike SullivanMike is currently working as a vBulletin developer and doing other freelance development. He hopes to release several PHP scripts on his site, EsuiteToday.com.








