One of the most overlooked new features of HTML5 is Microdata. Microdata allows us to more specifically categorize and label our web content in a machine-readable way. Why this is important is because it may positively affect your search results.
When you search for something on Google or elsewhere, you get a list of links with a few sentences of description below them. We all use these descriptions—which Google calls “Rich Snippets”—to determine which link to click on.
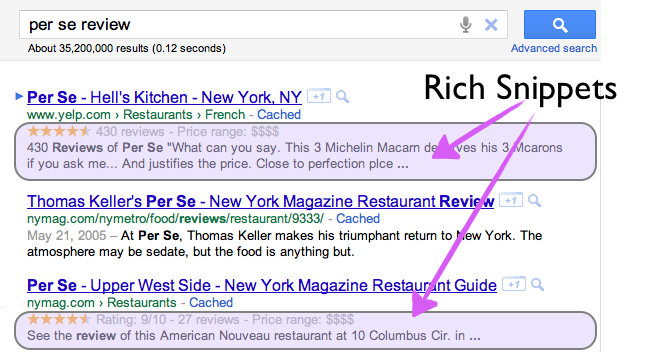
Wouldn’t you like to be able to influence what is displayed in search results snippets for your site? Wouldn’t it be nice to be able to clarify for the search engine and its bots that crawl your page, “Hey Google, I know I have twenty images on my page, but this image, that one is my bio picture.” Or perhaps, “Hi Bing, I know there are tons of links on my page but this link is the link relevant to my event.”
With Microdata, we can mark-up our existing HTML with a few new attributes in order to label and categorize our content in ways search engines can both understand and make use of in their rich snippets.
Before we add these new attributes, we need to pick a vocabulary of the thing we’re trying to describe. We could write our own vocabularies, or we could use someone else’s. We used to have a site, http://data-vocabulary.org, maintained by Google with several vocabularies. But it was unclear if the other search engines supported it. Lucky for us, in June 2011, Google, Microsoft and Yahoo! have teamed up to agree on a very large set of vocabularies we can use on our sites.
The Trinity of Search, Together
It’s hard to imagine Google, Microsoft and Yahoo! collaborating on anything, much less something search-related, but that’s exactly what they’re doing on the site schema.org. Schema.org provides a set of vocabularies we can make use of with Microdata. By using the vocabularies for things like Person, Book and Organization that are on defined schema.org, we can be sure our Microdata will be understood by Google, Bing and Yahoo! searches
How it works
To use Microdata, we must add at least three new attributes to our existing HTML:
ItemscopeItemtypeItemprop
To follow along with this example, please see the demonstration page. View source for the full code.
Itemscope
Itemscope sets the scope of what we are describing with microdata. You can think of it as defining a parent element, inside which will contain other elements with information we are trying to supply to search engines. All elements nested an element with the itemscope will adhere to the vocabulary you specify in #2, the itemtype.
If we want to describe a person on their online resume, we could wrap a section element around the resume and give it the itemscope attribute to begin:
<section itemscope>
Audre Lorde was an author, academic, activist and poet, known for
her many contributions to feminist literature and thought. Perhaps
her most celebrated work is "
<a href="http://t.co/8wbANUC">
Sister Outsider
</a>," a collection of essays and speeches. She passed away on
November 17th, 1992.
</section>Itemtype
The itemtype attribute is where we declare what vocabulary we’re using, and what thing we’re trying to describe. The most basic vocabulary on schema.org is for, well, a Thing. The Thing vocabulary includes four properties we can set: a description, an image, a name and a url. All other things (Books, Restaurants, Places) descend from the Thing vocabulary.
To continue adding Microdata to our online resume, we add the itemtype to our Person:
<section itemscope itemtype=”http://schema.org/Person”>
Audre Lorde was an author, academic, activist and poet, known for
her many contributions to feminist literature and thought. Perhaps
her most celebrated work is "
<a href="http://t.co/8wbANUC">
Sister Outsider
</a>," a collection of essays and speeches. She passed away on
November 17th, 1992.
</section>Itemprop
The itemprop attribute is how we add label the majority of our content. We simply add the itemprop attribute to existing elements with content we want to label. How are we labeling the content? That depends on what value we assign to the itemprop attribute. The value must be one of the properties of our vocabulary.
In some cases, you may want to label pure text content with itemprops. In these cases, there’s no existing HTML elements to add attributes to, so spans or divs are often added.
To continue with our example:
<section itemscope itemtype=”http://schema.org/Person”>
<span itemprop=”name”>Audre Lorde</span>
was an
<span itemprop=”jobTitle”>author,</span>
<span itemprop=”jobTitle”>academic,</span>
<span itemprop=”jobTitle”>activist</span> and
<span itemprop=”jobTitle”>poet</span>, known for her
many contributions to feminist literature and thought.
Perhaps her most celebrated work is "
<a href="http://t.co/8wbANUC">
Sister Outsider
</a>," a collection of essays and speeches. She passed away on
November 17th, 1992.
</section>Now we have specified which item property we care about, but, how does the search engine know what content I mean? Does it just take the text content inside the span elements (“Audre Lorde”, “author”, etc) How would it know where to grab the URL from for the itemprop=”url” on the a element?
The good news is that it essentially always grabs the value you’d hope it would grab. The complete list is in the Microdata spec:
A,areaorlinkelements take the value in thehrefattribute- A
metaelement takes the value in thecontentattribute Audio,embed,iframe,img,source,trackorvideoelements take the absolute URL from thesrcattribute- The
timeelement takes the value from thedatetimeattribute - The
objectelement takes the absolute URL from thedataattribute - All other elements take the text content inside the element. (example:
span,p,div)
Speaking of Datetime
We have a date of death in our small biographical page. Can we just add itemprop=”deathDate”, which is a property defined in the Person vocabulary? Unfortunately, we can’t. We need to first wrap it in the new HTML5 time element, to ensure we have a computer-readable date.
She passed away on <time itemprop="deathDate" datetime="1992-11-17">November
17th, 1992</time>.This all sounds familiar…
You may find these concepts familiar, as they’ve been around for some time. Microformats is one way that has been used in the past to make HTML content machine-readable. If you take a look at the HTML on a LinkedIn profile, you’ll find that it’s marked up with the hCard microformat. The same is true of Facebook Events.
One issue with microformats is that we’re overloading the class attribute in a non-standard way. It becomes hard to distinguish “is this class being used in my CSS, or is this for microformats?” By using the new, dedicated attributes itemscope, itemtype and itemprop, Microdata avoids this confusion.
Another limitation with microformats is that any data you want to include must live inside a single parent element—which can be limiting, especially if you have relevant information, say, in the footer of your website.
Including items beyond the parent item’s scope with Itemref
Let’s assume way down at the bottom of the page, we had a footer with a list of footnotes about the text about Audre Lorde above. If there footnotes were links, it would be nice to include them as itemprop=”url” in our mark-up.
<section itemscope itemtype=”http://schema.org/Person”>
<span itemprop=”name”>Audre Lorde</span>
was an
<span itemprop=”jobTitle”>author,</span>
<span itemprop=”jobTitle”>academic,</span>
<span itemprop=”jobTitle”>activist</span> and
<span itemprop=”jobTitle”>poet</span>, known for her
many contributions to feminist literature and
thought[<a href=”#citation1”>1</a>].
<!-- snip -->
</section>
<!-- more HTML -->
<footer>
<a name=”citation1”>[1]</a>
<a id=”cite1” itemprop=”url”
href=”http://en.wikipedia.org/wiki/Audre_Lorde”>
Audre Lorde on Wikipedia
</a>
</footer>How can we include this link in our footer in the page? By using an attribute called itemref in the section opening tag:
<section itemscope itemtype=”http://schema.org/Person” itemref=”cite1”>That will tell the search engines to also grab the relevant content out of an element whose id is cite1, as our link element in the footer has.
What if you want to refer to more than one id later on in the page? The way to do this is to simply specify a space-separated list of ids in the itemref, much as you can specify multiple class attributes by using a space-separated list.
Summary
Microdata allows us to mark up our existing elements and text with machine-readable labels, allowing our pages to be more clearly seen and understood by the major search engines. Google, Yahoo! And Microsoft have come together to give us a rich vocabulary of things we can describe with http://schema.org. And as a proper part of the HTML5 spec with its own dedicated attributes, a little extra work may give you a real edge in your search results.
Further Resources
Getting started guide
Google Rich Snippets
Rich Snippets Testing tool
 Alexis Goldstein
Alexis GoldsteinAlexis Goldstein first taught herself HTML while a high school student in the mid-1990s, and went on to get her degree in Computer Science from Columbia University. She runs her own software development and training company, aut faciam LLC. Before striking out on her own, Alexis spent seven years in Technology on Wall Street, where she worked in both the cash equity and equity derivative spaces at three major firms, and learned to love daily code reviews. She is a teacher and a co-organizer of Girl Develop It, and a very proud member of the NYC Resistor hackerspace in Brooklyn, NY.






