 How far should you go to protect your copyright?
How far should you go to protect your copyright?
Yesterday I clicked through to an anti-Twitter rant on MISAustralia.com (ironically via a retweet). While you can make your own call on the content, the thing that really caught my eye was the body font. Why on earth would a large, professional content site choose to display their content in an ugly, unreadable monospaced font?
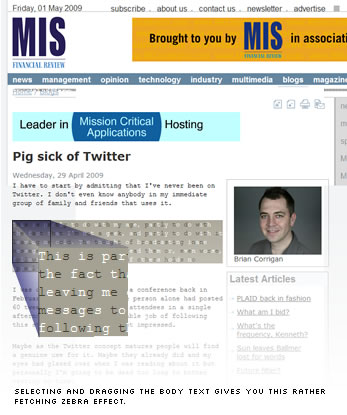 Absented-mindedly I drag-selected some of the text and got another surprise — a pretty, checkerboard pattern on the selection area.
Absented-mindedly I drag-selected some of the text and got another surprise — a pretty, checkerboard pattern on the selection area.
Hmmm… interesting. What’s going on here?…
Viewing the source, my jaw nearly hit the desk.
The insane scientists at MISAustralia appear to have built a content management system that automatically shuffles each paragraph into two piles, letter by letter.
Each pile is then dumped into its own DIV and padded out with non-breaking spaces, before they are precisely overlayed with each other to make them readable again.
Of course, this means copy-and-pasting the text ONLY touches the uppermost DIV, and explains both the zebra patterning and their choice of mono-spaced font.
Clearly their motivation is Digital Rights Management (DRM) by making it more difficult to copy-and-paste or screen scrape their content. In fact, their HTML source commenting refers to it as a ‘DRM Viewer’.

This seems astonishing to me on so many levels.
- Firstly it makes their content present as utter gobbledygook to screen readers and other assistive technologies. I am not a lawyer, but I’d suspect there’s the basis of a robust discrimination law suit in there.
- Secondly, it makes their content unreadable in any RSS reader and prevents them even offering an RSS feed.
- Thirdly, it necessitates the use of font that further erodes the value of their content.
- Finally, and most importantly, it makes their body copy (i.e. the heart and soul of their site and business) completely invisible to Google, Yahoo and every other search engine on the planet.
That last point is mindboggling to me.
An entire industry (SEO) has evolved for no other reason than to ensure Google sees and values your content. Companies live or die on their ability to make their content visible. Here is a company going to great time, effort and expense to actively obscure their work from the web’s largest traffic provider.
As far as Google is concerned, this isn’t just lowly rated content, it is ‘non-content’. It simply doesn’t exist. It was never written.
As a quick example, take this recent article Nine loses EPG battle.
Search Google for the non-DRMed article title and it comes up first. Perfect! Google clearly knows and visits them.
However, let’s step inside the article and search for a highly specific phrase, “Ice TV general manager Matt Kossatz said the ruling was timely”.
Result: Nothing. Blip. Nothing to see here, people, move along.
Of course that’s no surprise. How WOULD Google know what it was looking at?
I’m not even going to start with the huge accessibility issues for fear of turning this into a 10 page post.
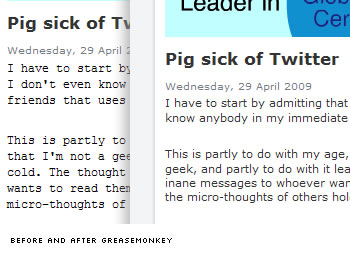 The Final Irony
The Final Irony
Now, if this was a foolproof solution to their copyright dilemmas it’s still highly debatable whether it’s worthwhile inconveniencing 99.99% of your everyday readers to stop the .01% of your visitors that are infringers.
Unfortunately this DRM is anything but foolproof.
Anyone running Greasemonkey and the MISaustralia text selector userscript (Hats off to Gustav Axelsson) can not only cut-and-paste their little hearts out, but they get to read it in a comparatively luxurious Verdana, Arial, or Helvetica typeface.
In fact, if you’re a Firefox user who reads this site, you’d be almost silly NOT to use this script, just for readability reasons.
Equally, writing an application that automatically parsed and republished every new article elsewhere would be just as trivial. And the cool bit is they don’t even have to compete with the original authors. They would ‘own’ that content as far as Google was concerned.
Now these guys are part of a large, generally, tech-savvy company (Fairfax).
Is this nuts?
 Alex Walker
Alex WalkerAlex has been doing cruel and unusual things to CSS since 2001. He is the lead front-end design and dev for SitePoint and one-time SitePoint's Design and UX editor with over 150+ newsletter written. Co-author of The Principles of Beautiful Web Design. Now Alex is involved in the planning, development, production, and marketing of a huge range of printed and online products and references. He has designed over 60+ of SitePoint's book covers.





